[NLP Paper] Financial Sentiment Analysis: An Investigation into Common Mistakes and Silver Bullets
논문 본문은 여기서:
최근 금융 텍스트 데이터 분석에 관해 다양한 연구들이 나오고 있다. (e.g. Stock market prediction, asset allocation, initial public offering valuation(IPO)). 이 중에서도 감정 분석 연구들의 목적은, 어떤 금융 관련 텍스트의 특정 argument를 통해 긍정적(positive/bullish) 혹은 부정적(negative/bearish) 의견을 밝혀내는 것이다.
금융 데이터 감정 분석(FSA)에 특히 어려운 점이 있다면 무엇일까?
- 방대한 양의 training data를 찾기 어렵고 labeling하기 위해서는 도메인 지식이 필요하다.
- General domain에 비해, 같은 감정분석 모델을 사용해도 퍼포먼스가 현저히 떨어진다(domain adaptation problem). 뛰어난 언어 능력을 가진 사람도 별다른 공부 과정 없이 어려운 의학 서적을 읽는다면 읽는 속도와 정확도가 느려질 것이다.
이 연구에서는 금융 데이터 감정 분석의 이러한 점에 주목하여, 다음과 같은 질문을 던지고 있다.
RQ1: Do different sentiment analysis methods make the common errors or each of them makes errors on different examples of financial texts?
RQ2: How reliable and consistent are the usually reported sentiment analysis metrics, i.e., F-score and accuracy measure, in evaluating methods across datasets from different language domains?
RQ3: Is the performance deterioration for financial texts due to the same reasons as those found in other language domains?
if so → the problem is expected to be significantly mitigated with common domain adapted methods
otherwise → we suspect that to understand financial sentiment, more resources (jargon, time, complex reference) are required than in other domains
Compared Models for the FSA Task
다음과 같은 8개의 모델들을 사용하였다.
Lexicon-based
- OpinionLex
- SenticNet
- L&M dictionary
ML-based
Deep learning-based
- bi-LSTM
- S-LSTM
- BERT
Experiments
1. Datasets
(1) the Yelp dataset : business review 도메인, balanced
(2) StockTwits Sentiment dataset(StockSen): finance 도메인, self-labeld by users, imbalanced(positive texts posted triples the number of negative ones)
이 StockSen 데이터셋에는, 유저들의 self-label이 없으면 감정 판단을 하기 거의 불가능한 데이터들이 다수 포함되어 있었다. 그리고 실제 환경과 가깝게 하기 위해서 저자들이 pre-prossing을 최소한으로 했기 때문에 실제 테스트에 사용된 데이터셋은 Yelp dataset보다 훨씬 적었다.
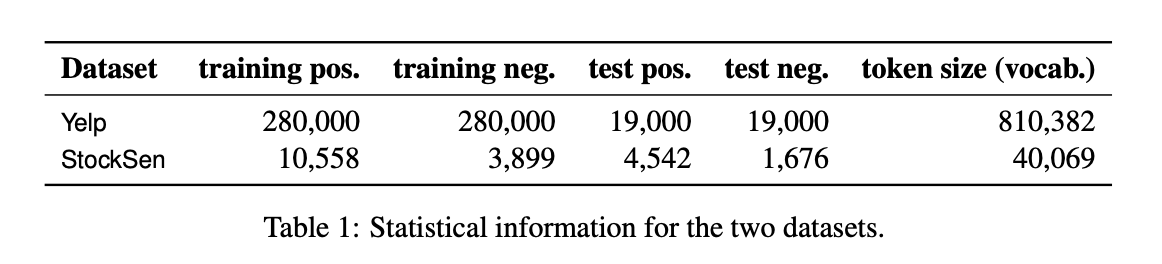
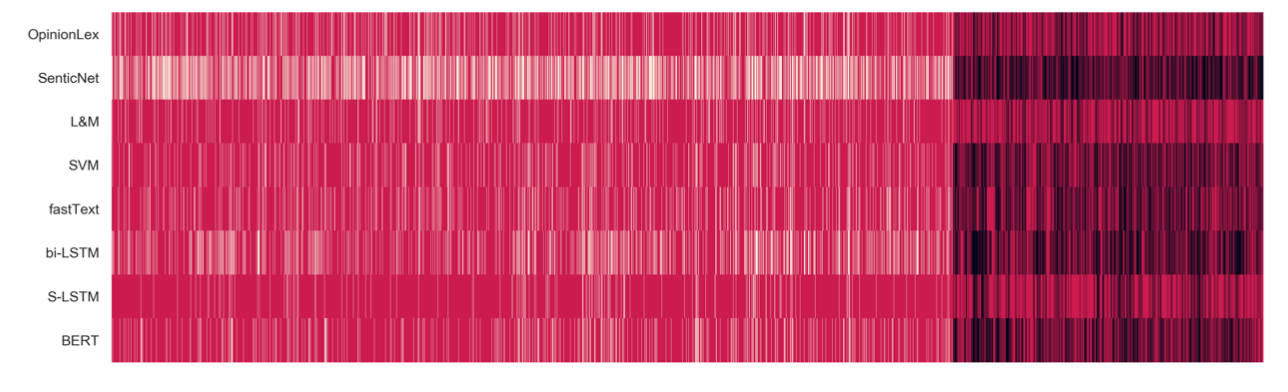
Figure 1: visualization of the financial sentiment classification error distributions by different methods(x:시간축, White strips: false negative, Black strips: false positive)
→ S-LSTM을 제외하고, ML기반 및 딥러닝 기반의 모델들이 false positive errors를 더 많이 낸다는 것을 볼 수 있다.
2. Result Evaluation
8개의 experimented methods의 예측 결과의 correlation을 그림으로 나타내었다.
2개의 methods에 관해 pos-neg: correlation -1
2개의 methods에 관해 pos-pos, neg-neg: correlation 1 이다.
여기서 사용된 StocksSen 데이터셋 자체가 imbalanced되어 있기 때문에, imbalanced dataset을 위해 디자인 된 Matthews Correlation Coefficient 을 사용하였다.

다음과 같은 공식을 사용하여 위 matrices에 나온 값을 도출했다.
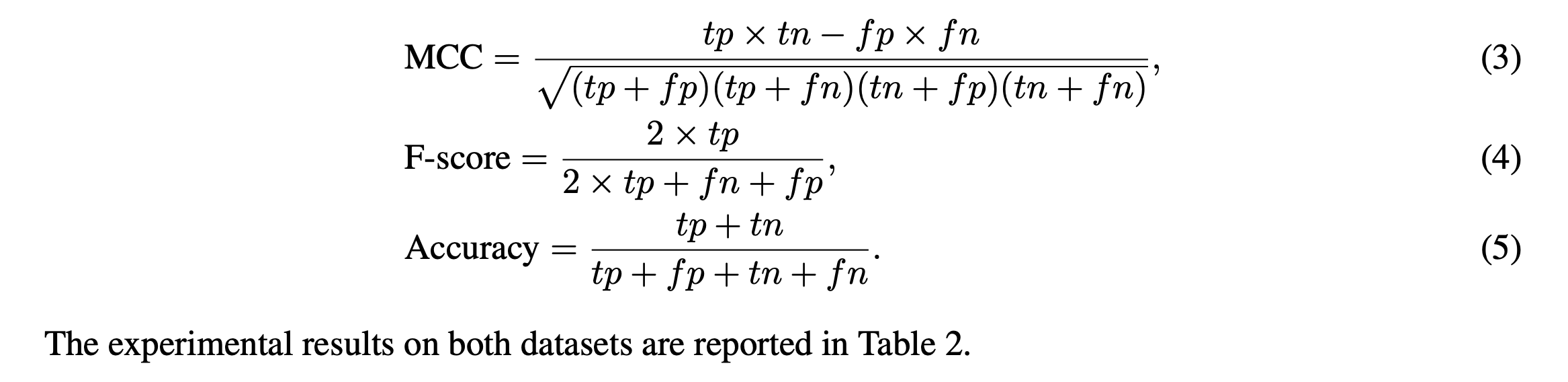
Discoveries and the Answer to Research Questions
Table 2 를 통해, 감정 분석의 퍼포먼스는 동일한 모델에 대해 금융 도메인에서 훨씬 낮아진다는 것을 알 수 있다.
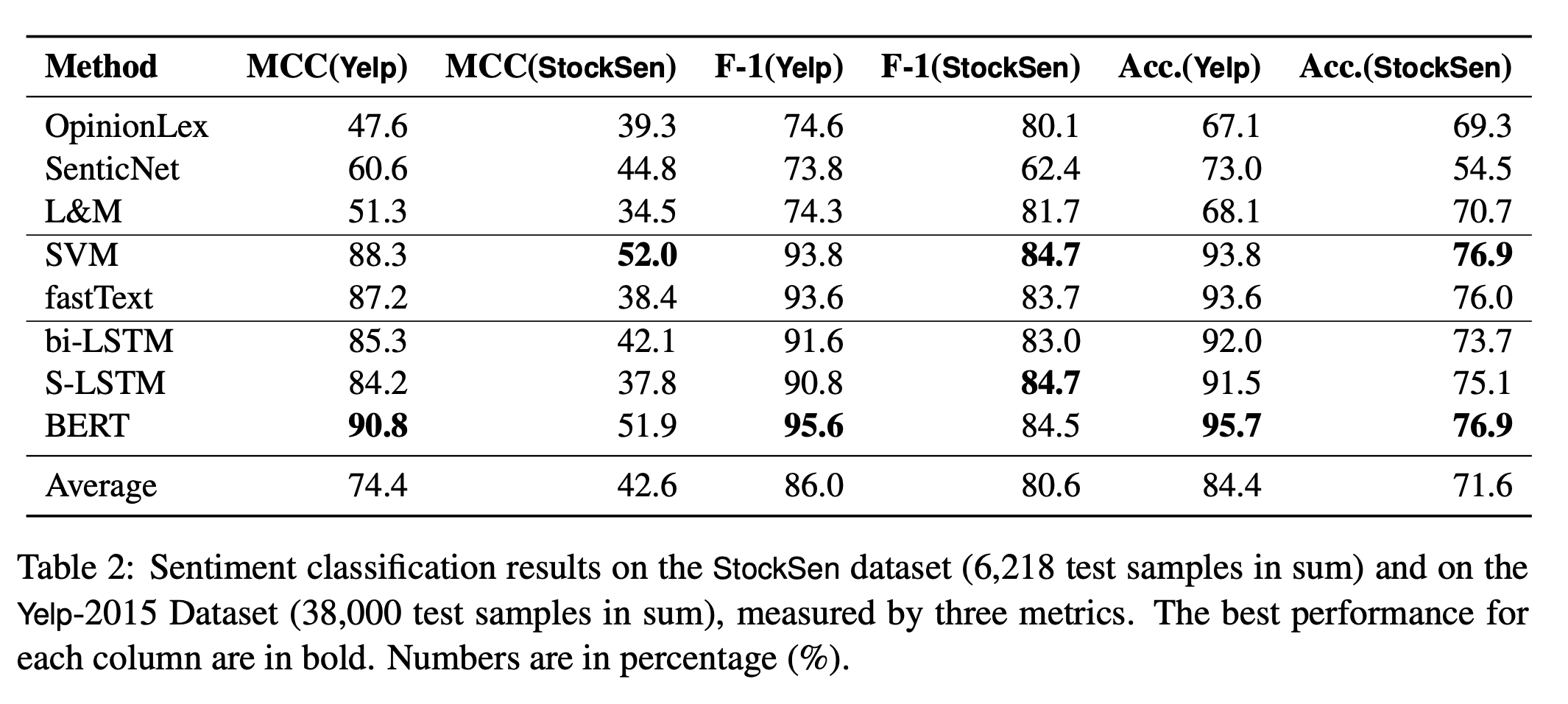
RQ1: 오류는 model-specific 하며 negative samples에 대해 less consensus를 이룬다. 위 Figure 2의 아래 삼각 행렬이 더 연한 색인 것을 보면 알 수 있다.
RQ2: 하나의 metric만 가지고 어느 모델이 제일 나은지 판단하기 어렵다. Table 2를 보면 모델마다 각각 제일 잘 나온 score의 종류가 다르다.
RQ3: Domain adapted lexicon을 사용하는 것만으로는 FSA problem을 해결할 수 없다. 심지어 L&M은 finance domain을 위해 나왔지만 세 개의 lexicon-based models는 StockSen dataset 보다 Yelp dataset에 서 더 나은 결과를 보여줬다.
Reasons behind Classification Errors
이 논문은 Abbasi et al.(2014)의 트윗 감정 분석 연구가 머신러닝 feature에 집중한 것과 달리, linguistic phenomena가 원인이 되어 발생한 오류에 더 초점을 두고 있다. 그리고 금융 도메인에서 이러한 오류들이 두드러지게 나타나는 사례들을 발견했다.

1. Irrealis Moods
Conditional mood: “if there was any better opportunity to exit long term holdings [...] It would be this month”.
여기서는 미래에 대해 비관적인 성향을 보이지만, "better opportunity" 때문에 모델이 positive라고 판단할 수 있다. “if+ VBD/VBN, would/should/might+VB/VBN” (Narayanan et al., 2009). 등으로 구성된 문장들이 이러한 혼란을 초래할 수 있다.
Subjunctive mood: “Would be shocked if this closes under 1900 tmrw”; “would be amazing if it touch 210 tomorrow”. 첫 번째 문장에서 화자는 가격이 1900이상이 될 것이라고 판단(positive) 하며 두 번째 문장에서는 210이하가 될 가능성이 크다고 본다. 이 경우 단순히 "amazing"은 positive라고 판별한다면 false positive sentiment가 나올 것이다.
Imperative mood: “2 negative articles paid for by short sellers. Dont believe them!”. 뒤에 don't believe them이라고 하기 때문에, 이 화자는 이 주제에 positive하다. 하지만 "negative articles" 때문에 모델이 negative라고 판단할 가능성이 있다.
2. Rhetoric
Syntactic features + semantic meanings
Negative assertion: “In the market for a iwatch and airpods too. What recession?!”; “Who buys at 205? Not me.”. 여기서의 질문은, 정답을 바라는 것이 아닌 proposing a challenge를 위해 사용된다. "What recession?!” 은 현재 recession이 없다는 것을 의미하며 "Who buys?"는 아무도 사지 않을 것임을 의미한다. 즉 이 의미를 파악하지 못하면 틀린 감정 분석 결과를 도출할 것이다.
Personification: “$TSLA fighting for its life here”. 여기서는 테슬라를 사람에 비유했다. 의인화는 part-of-speech (POS) 및 named entity recognition (NER) tags에서 관찰될 수 있다.
Sarcasm: “*$AMZN the Amazon board is hilarious”.* 여기서 “hilarious” 는 모델에서는 positive라고 판단되지만, 문맥상의 실제 의미는 negative이다. StockSen과 Yelp 데이터셋에서, negative test case에 sarcasm은 거의 항상 존재했다.
3. Dependent Opinion
“[...] I think many underestimate it. spring how” and in “bulls need 236.. not far away..”. 여기서 "underestimate" 는 제 3자의 의견이며, 이 단어 자체 때문에 negative가 될 가능성이 있다. 즉 dependent opinion으로 인해 발생된 오류는, 제 3자의 의견이 문장 속에 들어가 있는 경우에 모델이 이를 화자의 의견으로 착각하는 것을 말한다.
4. Unspecified Aspects
하나의 문장에 1개 이상의 sentiment aspect가 들어가 있을 수 있다.
“$SOLY Allergan should be concerned that cool sculpting will be rendered obsolete” 여기서 화자는 Allergan 의 기술이 구식이라고 생각한다. 하지만 이 코멘트는 경쟁사인 $SOLY 에 달렸다. 즉 이는 $SOLY에 대한 positive한 의견이다. 즉 감정 분석의 오류를 줄이기 위해서 모델은 이 문장이 다른 aspect 에 대한 것인지 판단해야 한다.
5. Unrecognized Words
Entity: “$AAPL time to upgrade my 6s. [...] Otherwise flawless.”. 여기서 6s 는 6초가 아니라 아이폰 모델을 의미한다. 이러한 것들을 판단하기 위해서는 도메인 지식과 상식이 동시에 필요하다.
Microtext: “it will break 1800 EOW.” 에서 EOW는 end of week 을 의미한다. 이처럼 모델이 판단하기 어려운 줄임말 등이 있을 수 있다.
Jargons: out-of-vocabulary words(oov)다. 즉 도메인에 특화된 용어들 중 은어들을 얘기한다. *“the stock formed a head and shoulders on a 5 day”* 에서 head 와 shoulder은, 차트에서의 downward trend를 의미한다. 즉 감정 분석 결과는 neutral이 아닌 negative가 되어야 한다.
6. External Reference
“Lets get down to price levels beginning of the year!!!” 를 보면, 이 문장의 감정분석 결과를 알기 위해서는 beginning of the year의 주식 가격 정보가 필요하다. 이 문장만 가지고는 positive인지 negative인지 알기 어렵다.
Conclusion
- Model metrics를 비교하는 것을 넘어서, 오류 패턴을 시각화하고 언어적 분석을 시행
- 동일한 cluster에 있는 모델들은 유사한 오류 패턴에 취약
- 금융 데이터 감정 분석이 실패하는 6가지 원인 도출. 이를 통해 모델 퍼포먼스를 발전시킬 수 있다.
- 금융 데이터 감정 분석에서 'silver bullets(만병통치약)' 는 환상에 불과. 감정 분석의 오류들은 NLP sub-problems를 해결하지 않고는 결코 완전히 해결될 수 없음
- Divide-and-conquer approach 필요
많은 FSA연구들이 감정분석 → 무언가를(주가, 수익률 등..)예측하는 방식으로 진행되는데 이와 달리 '감정분석 시 발생하는 오류'에 주목한 논문이었다. 다양한 모델을 통해 나온 수치값을 비교하는 것을 넘어서, 오류 패턴을 시각화했고 원인들을 분석했다. 이런 점들이 고쳐진 모델의 퍼포먼스가 어떨지도 궁금했는데 이 논문에서 그건 다루지 않았다. (아마 어떻게 고칠지 해답을 못 찾았기 때문에 그랬던 듯)
한국어 금융 데이터로 이러한 연구를 수행한다면,
-
한국어와 영어의 다른 점에서 기인한, 오류 원인의 차이(문장 구조도 다르고, unrecognized words도 다를 것이다)
-
데이터에서 온 차이(여기는 user 가 positive/negative로 self-labeling 한 StockSen 데이터셋을 썼는데, 만약 unlabeled financial text data를 사용하면 어떻게 될까? 또한 트위터 데이터가 아닌, 뉴스 데이터셋을 사용한다면 어떻게 될까? 트위터의 사용자 의견보다는 아무래도 뉴스는 더 정제되어 있으니..오류 원인도 달라지지 않을까?
뒤쪽 error reason classify하는 부분을 어떻게 했는지 궁금했는데(Table 3이 어떻게 나왔는지..), 아쉽게도 코드는 공개되어 있지 않다. 금융 도메인에 유사한 연구가 없다면 일반 NLP 연구에서는 어떤 식으로 접근했는지, 코드는 있는지 더 찾아봐야 할 것 같다.
.jpeg)