Redis?

Redis란 Remote Dictionary Server의 약자로 일종의 DBMS이다.
하지만 우리가 자주 사용하는 Orcle, MySQL처럼 관계형 데이터베이스(RDBMS)가 아닌 Dictionary 이름 그대로 Key와 Velue로 이루어진 비관계형 DBMS 이다.
특징 1 : 자료구조
Hash Map과 비슷하게 일반적인 데이터 타입 뿐만이 아니라 List, Hash, set 등 과 같은 다양한 자료구조를 사용할 수 있다는 것이 하나의 특징이다.
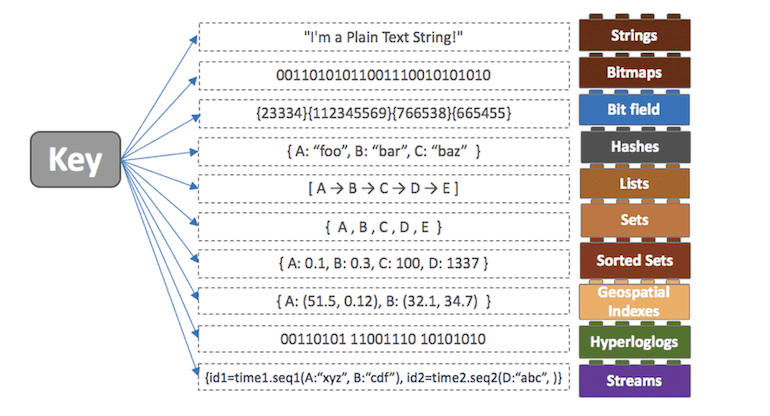
이러한 자료구조들을 사용할 수 있으며 코드로 예를 들면
import redis.clients.jedis.Jedis;
public class RedisListExample {
public static void main(String[] args) {
// Redis 서버에 연결
Jedis jedis = new Jedis("localhost");
// 리스트에 값 추가
jedis.lpush("mylist", "Java");
jedis.lpush("mylist", "Python");
jedis.lpush("mylist", "JavaScript");
// 리스트의 모든 값 가져오기
System.out.println("All values in the list:");
System.out.println(jedis.lrange("mylist", 0, -1));
// Redis 연결 종료
jedis.close();
}
}이 코드는 Java에서 Redis을 사용하는데 value 값을 리스트 형태로 저장하는 코드이다
key 값은 mylist 이고,value 값은 Java, Python, JavaScript가 순차적으로 들어가게 된다.
이 결과로는
All values in the list:
[JavaScript, Python, Java]이렇게 List 형식으로 출력된다.
다양한 자료구조로 저장할 수 있으니 필요할때 다르게 사용해서 저장해놓으면 된다.
특징 2 : 인메모리 구조
또 다른 특징으로 Redis는 데이터를 캐시형식으로 메모리에 저장하는 인메모리 데이터 구조이다.
인메모리 형태란 일반적으로 하드디스크에 데이터를 저장하는 것이 아니라 메모리에 저장하는 형태라는 것이다.
이 특징을 이해하기 위해서는 '캐시'(cache) 개념을 이해해야한다.
캐시는 나중에 요청이 들어올 결과를 미리 저장해두었다가 빠르게 클라이언트에게 데이터를 제공하는 것을 말한다.
즉, 자주 요청되는 결과를 메모리에 저장해두고 해당 요청이 들어오면 따로 DB나 api 참조 없이 cache에 접근하여 요청을 처리한다.
이 방식의 장점은 메모리에서 값을 출력하기 때문에 속도가 하드디스크에 접근하는 것 보다 몇백배 빠르다는 것이다.
즉, Redis는 이러한 캐시의 방식을 통해 데이터를 저장하는 '인메모리 데이터 구조'를 사용하기 때문에 다른 DBMS에 비해 속도가 매우 빠르다는 장점이 있다.
하지만 메모리에 데이터를 저장한다면 매우 빠를지언정 가장 큰 단점이 있다.
메모리의 '휘발성'이다.
만약 컴퓨터가 꺼진다면 메모리에 존재하던 데이터는 모두 삭제되기 때문에 만약 데이터를 따로 저장해놓지 않았다면 데이터 유실 현상이 일어나게 될 것이다.
이러한 단점을 극복 하기 위한 방법이 AOF와 RDB이다.
AOF : Append Only File
이 방법은 redis에서 발생하는 모든 write/update 연산 자체를 모두 log 파일에 기록한다.
이러한 방법으로 인해 메모리가 삭제되더라도 파일에 기록되어 있기 때문에 데이터 유실이 일어나지 않는다.
RDB : Snapshotting
이 방법은 순간적으로 메모리에 있는 내용을 캡쳐하듯이 찍고 Disk에 전체를 옮겨 담는 방식이다.
이러한 방식으로 메모리의 휘발성을 방지하고 영속성을 유지한다.
하지만 AOF는 매번 파일에 기록하기 때문에 성능이 저하되는 단점이 있고, RDB방식은 disk에 데이터를 옮기기 전에 메모리에서 정보가 휘발된다면 데이터가 유실될 수 있는 단점이 존재한다.
이러한 단점 때문에 많은 기업에서 성능이 뛰어난 Redis를 주 저장장치로 하지 않고 cache 역할을 하는 서브 저장장치로 이용한다.
Why Redis?
그렇다면 기업들은 이 Redis를 왜 사용할까?
약 100만의 트래픽이 발생한다고 하자.
하지만 이렇게 많은 트래픽에서 모든 http 메소드가 실행되지는 않는다.
서버에 정보를 요청하는 Get 메소드가 대부분인데 약 90% 라고 했을 때 이 요청 전부를 DB와 연동한다면 비용이 매우 많이 들 것이다.
하지만 Redis를 DB와 연동하는 서버 바로 앞에 위치 시켜 사용한다면 Cache 방식을 통해 Get 요청에 대한 정보를 미리 메모리에 저장하여 클라이언트에게 훨씬 빠르게 데이터를 전달할 수 있으며, 실제 DB에서 발생하는 비용이 10%까지 줄어들 수 있을 것이다.
현재 프로젝트에 사용한다면?
현재 우리 프로젝트는 입력된 환자의 데이터를 보여주는 기능이 가장 중요하다.
MySQL를 사용하는 현재 DB에 저장된 데이터가 많을수록, 조회하려는 날짜가 길 수록 출력해야하는 데이터가 많아질 것이고 이에따라 서버에 부하가 걸려 속도가 느려질 것이다.
Redis가 매우 성능이 좋은 편이지만 데이터 유실에 대한 위험성이 존재하는 것은 확실하다.
우리 프로젝트는 환자의 생체 데이터를 다루기 때문에 성능적인 측면을 위해 이러한 비안정성을 내버려 둘 수 없다.
때문에 우리 프로젝트에 적용하기 위해서는 다른 기업들과 비슷하게 RDBMS를 주 DB로 하고, Redis를 보조 DB 서버로 하여 적용하면 유저가 환저 정보를 출력하려했을때 Redis를 먼저 탐색하여 데이터가 있다면 매우 빠른 속도로 환자의 생체 데이터를 출력해줄 것이다.
