프로젝트를 진행하다 보면 다양한 모델을 다루게 되고, 각 모델의 Entity 는 여러 column으로 구성되어 있다.
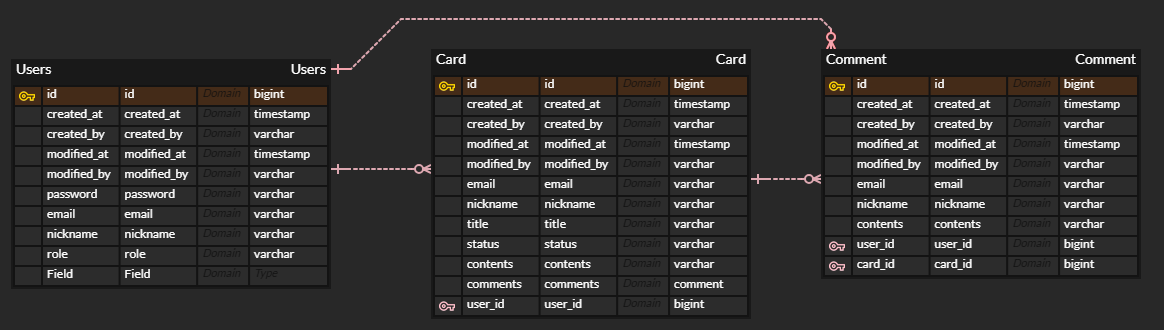
하지만 이곳에 있는 column들을 항상 A-Z 까지 전부 쓰는 것은 아니고, 상황에 따라 A-C 까지 혹은 D-F 까지 부분만 호출하여 사용하는 상황도 많다. 그동안 JPA, QueryDSL 을 이용해 Repository 에서 Etity 를 호출한 뒤 Response 양식에 맞춰 필요한 부분만 return 하고 있었던 작업은 나머지 데이터까지 불필요하게 호출하고 있었던 것이다.
이에 Projection 이란 기법을 적용하여 효율적인 데이터 전송을 구현해보려 한다.
Projection 이란?
'투사' 라는 뜻으로 수학에선 아래와 같은 의미로 쓰인다.
사영 또는 투영으로 불리며, 어떤 집합을 "부분집합"으로 특정한 조건을 만족시키면서 옮기는 작용이다. 수학에서 사영은 집합(또는 다른 수학적 구조)을 하위 집합(또는 하위 구조)으로 멱등적으로 매핑하는 것이다.
즉, Entity 모든 column 을 호출해서 사용하는 것이 아니라 필요한 "부분집합" 을 추려서 필요한 데이터만을 가져오므로 데이터 전송을 최소화 하여 성능을 향상시키려는 아이디어인 것이다.
+ 뿐만 아니라 필요한 데이터만 노출하기 때문에 보안성도 강화된다!
그리고 Entity 를 그대로 조회하는 것에는 또 다른 문제가 있다. 조회된 모든 Entity 는 강제로 영속성 컨텍스트의 관리를 받게 된다. Dirty Checking 을 위해 Entity 의 상태를 추적하고, 변경을 자동으로 감지한다는 것인데, 이 부분도 성능 및 메모리에 영향을 주기 때문이다.
따라서 쓰기(Command) 작업을 수행할 땐 Entity 로 조회하는 것이 필요하지만 읽기(Query) 작업을 수행할 땐 Projection 을 통해 필요한 정보만 조회하기로 하는 것이다.
DTO 사용하기
DTO(Data Transfer Object) 는 말 그대로 데이터를 옮기기 위해 존재하는 객체로, Projection 을 통해 데이터를 조회한다는 것은 반환 자료형으로 Entity 가 아닌 DTO 를 사용한다는 것이다.
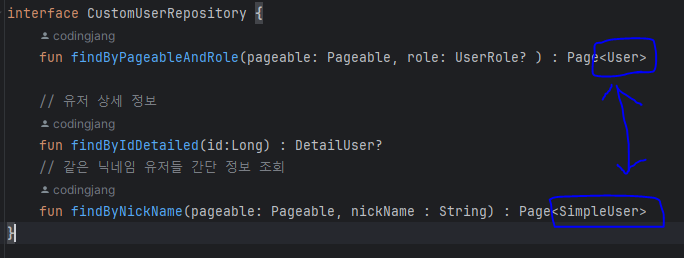
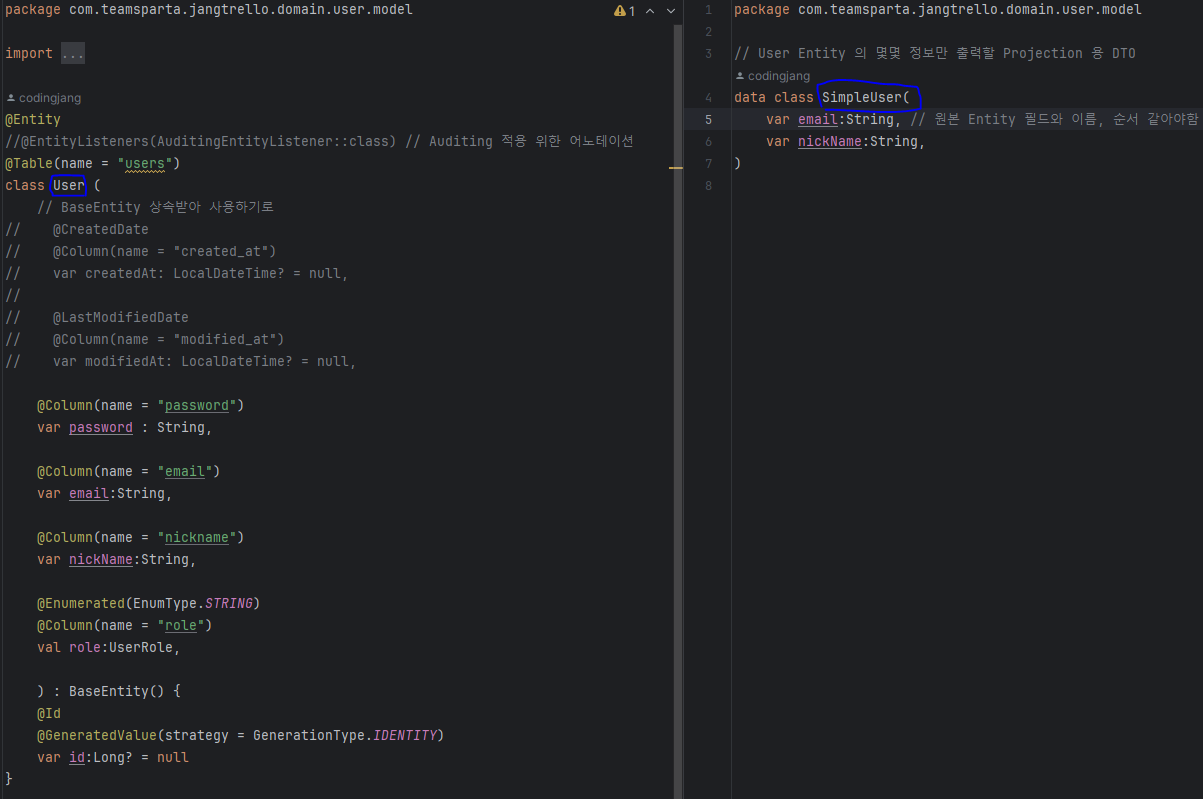
JPA Repository 와 JPQL 에서의 Projection
Projection 은 두 가지로 구분된다.
- Closed Projection : 데이터베이스에 있는 컬럼을 그대로 매핑해 Projection 하는 것
- Open Projection : 데이터베이스에 있는 컬럼을 이용해 다양한 연산을 한 결과로 Projection 하는 것
그리고 구현 방법에도 두 가지 방법이 있다.
- Interface-Based Projection : 인터페이스에 정확한 컬럼명을 Getter 추상메소드를 만들어 getEmail(), getNickName() 등으로 JPA 가 직접 필요한 컬럼을 추론하게 만드는 방법
- Class-Based Projection : Data class 를 생성하여 필요한 컬럼명과 동일한 필드를 만들어
사용하는 방법. ( JPQL 에선 직접 JPQL 모든 경로를 포함한 쿼리문을 작성해야 하는 불편함도 있다! )
여기에 적용할 수 있는 Dynamic Projection 도 있는데, 제네릭을 이용하여 전달받는 클래스의 타입에 따라 반환타입이 달라지게 하는 방법이다.
두 방법 모두 번거로운 과정이 필요하기 때문에 QueryDSL 에서 사용해보려 한다.
QueryDSL 에서 Proejction 사용하기
QueryDSL 에서 Projection 을 구현하는 방법은 총 4가지 이다.
- Projection.bean ( 비추천 )
- dto를 생성하고 Setter 를 기반으로 동작. ( 1개의 Bean 을 생성하여 값을 Set 해가며 사용하는 것 )
- 따라서 필드를 var 로 선언해야 하고, 기본 생성자로 null 을 지정해주어야 한다.
- DTO 의 불변성 위배 , Nullable 강제 되는 문제 발생 !!
- Projection.field ( 비추천 )
- .bean 방식과 내부적으로 동일하게 동작 -> 동일한 문제
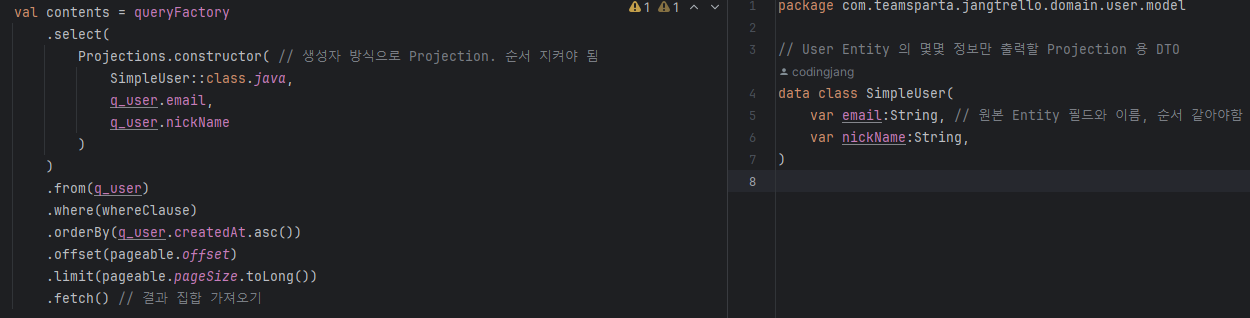
- Projection.constructor
- .bean 에서 .contstructor 로 바꾸었을 뿐인데 .bean 방식의 문제점을 모두 해결할 수 있다. ( val 사용, 기본 생성자 불필요 )
- 하지만 생성자 순서와 QueryDSL 의 순서가 완벽하게 일치해야 한다 !
- @QueryProjection
- dto 의 생성자에 @QueryProjection 어노테이션을 붙여준 뒤, Gradle 의 compileKotlin 을 실행하면 QueryDSL 에서 QClass 를 자동으로 생성해준다.
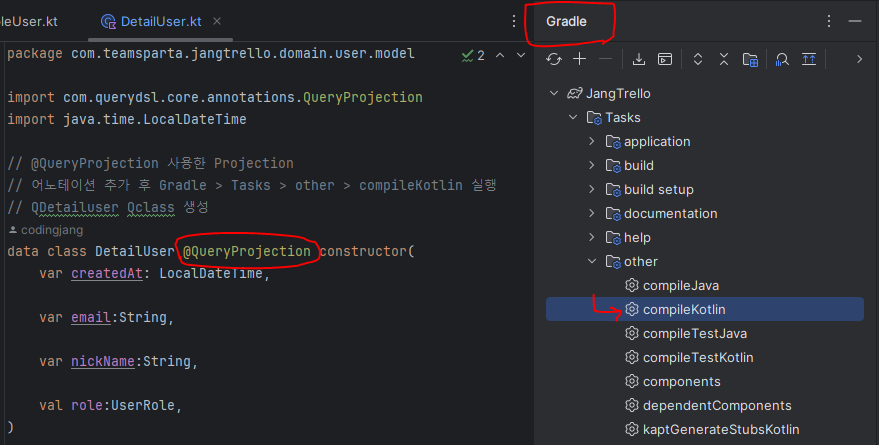
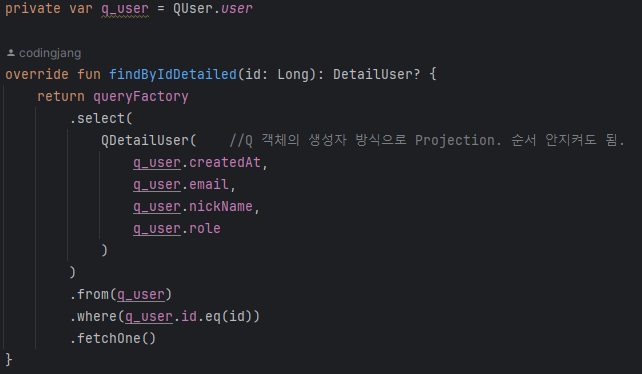
이렇게 @QueryProjection 방식으로 구현하면 DTO 불변을 지키면서도 Nullable 타입을 사용하지 않아도 될 뿐더러 생성자 순서를 맞추어야 한다는 문제도 사라지게 된다 !
하지만 약간의 단점이 존재한다면
- DTO 는 Repository 를 벗어나 다른 계층도 오가는 객체인데 DTO 자체가 QueryDSL 을 의존하는 것은 사실 옳지 않다. -> Repsitory 의 변경점이 다른 계층으로 전파될 가능성이 생기기 때문..
결론 : 반드시 생성자 방식을 사용하되 .constructor 방식이나 @QueryProjection 중 상황을 고려하자!
+ 이후 반환된 DTO 에 맞는 Response DTO 를 생성하여 반환해주면 된다.
+ Projection 이용하면 Covering Index(쿼리의 결과를 인덱스만으로 얻어내어 디스크 I/O를 최소화하여 쿼리 성능을 향상시키는 기술) 를 활용할 수 있다. 이 내용은 조금 더 공부가 필요할 것 같다.
