회귀 모델 결정 계수 정리
결정계수란?
- 회귀모델이 주어진 자료에 얼마나 적합한지를 평가하는 지표
- y의 변동량대비 모델 예측값의 변동량을 의미함
- 0~1의 값을 가지며, 상관관계가 높을수록 1에 가까워짐
- r2=0.3인 경우 약 30% 정도의 설명력을 가진다 라고 해석할 수 있음
- sklearn의 r2_score의 경우 데이터가 arbitrarily할 경우 음수가 나올수 있음
음수가 나올경우 모두 일괄 평균으로 예측하는 것보다 모델의 성능이 떨어진다는 의미
결정계수는 독립변수가 많아질 수록 값이 커지기때문에, 독립변수가 2개 이상일 경우 조정된 결정계수를 사용해야 함
일반적인 결정계수 기준
- 일반적으로 Bio는 0.95, 공학은 0.7, 사회과학은 0.3 정도를 기준으로 한다고 함.
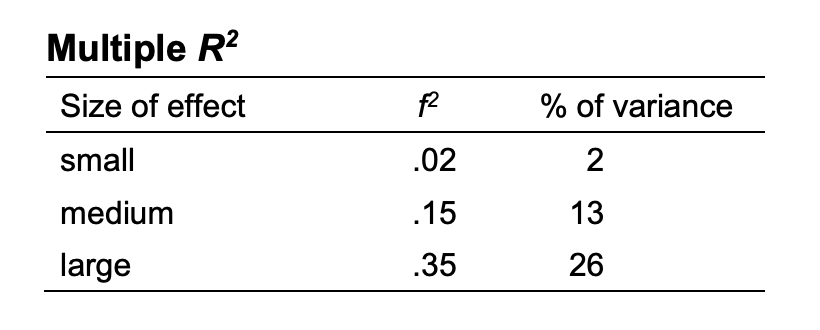
Cohen이라는 학자는 아래와 같이 효과크기에 따른 결정계수의 기준을 제시함
보통 사회과학에서는 이중 medium의 기준인 0.13 정도를 기준으로 함
결정계수 및 조정된 결정계수를 계산
def adj_r2(r2, n, p):
return 1 - (1-r2)*(n-1)/(n-p-1)
r2 = r2_score(lr.predict(test_x), test_y)
print("df.shape :", df2.shape, "r2_score", r2)
print("adj_r2_score", adj_r2(r2, test_x.shape[0], test_x.shape[1]))
주의해서 볼 점은 두번째 모델의 결정계수(r2)가 첫번째 모델의 값보다 월등히 높더라도, 조정된 결정계수(adj_r2)가 차이가 없다면 성능(조정된 결정계수)에 큰 차이가 없고, 오히려 첫번째 모델을 사용하는게 나은 선택이 될 수도 있다
설명력이 중요한 상황이라면 첫번째 모델이 더 나을수 있고, 정확도가 중요하다면 두번째 모델이 더 나을수 있다.

Don't forget the grace