
1. GraphQL이란?
GraphQL는 API를 만들 때 사용할 수 있는 쿼리언어입니다. 그와 동시에 쿼리에 대한 데이터를 받을 수 있는 런터임이기도 합니다.
GraphQL은 선언형 데이터 fetching 언어라고 흔히 일컬어집니다. 그러므로 개발자는 무슨데이터가 필요한지에 대한 요구사항만 작성하면 되고 어떻게 가져올지는 신경쓰지 않아도 됩니다.
GraphQL(이하 gql)은 Structed Query Language(이하 sql)와 마찬가지로 쿼리 언어입니다. 하지만 gql과 sql의 언어적 구조 차이는 매우 큽니다. 또한 gql과 sql이 실전에서 쓰이는 방식의 차이도 매우 큽니다. gql과 sql의 언어적 구조 차이가 활용 측면에서의 차이를 가져왔습니다. 이 둘은 애초에 탄생 시기도 다르고 배경도 다릅니다.
SQL은 데이터베이스 시스템에 저장된 데이터를 효율적으로 가져오는 것이 목적이고, gql은 웹 클라이언트가 데이터를 서버로 부터 효율적으로 가져오는 것이 목적입니다. sql의 문장(statement)은 주로 백앤드 시스템에서 작성하고 호출 하는 반면, gql의 문장은 주로 클라이언트 시스템에서 작성하고 호출 합니다.
서버사이드 gql 어플리케이션은 gql로 작성된 쿼리를 입력으로 받아 쿼리를 처리한 결과를 다시 클라이언트로 돌려줍니다. HTTP API 자체가 특정 데이터베이스나 플렛폼에 종속적이지 않은것 처럼 마찬가지로 gql 역시 어떠한 특정 데이터베이스나 플렛폼에 종속적이지 않습니다. 심지어 네트워크 방식에도 종속적이지 않습니다. 일반적으로 gql의 인터페이스간 송수신은 네트워크 레이어 L7의 HTTP POST 메서드와 웹소켓 프로토콜을 활용합니다.
- GraphQL 파이프 라인
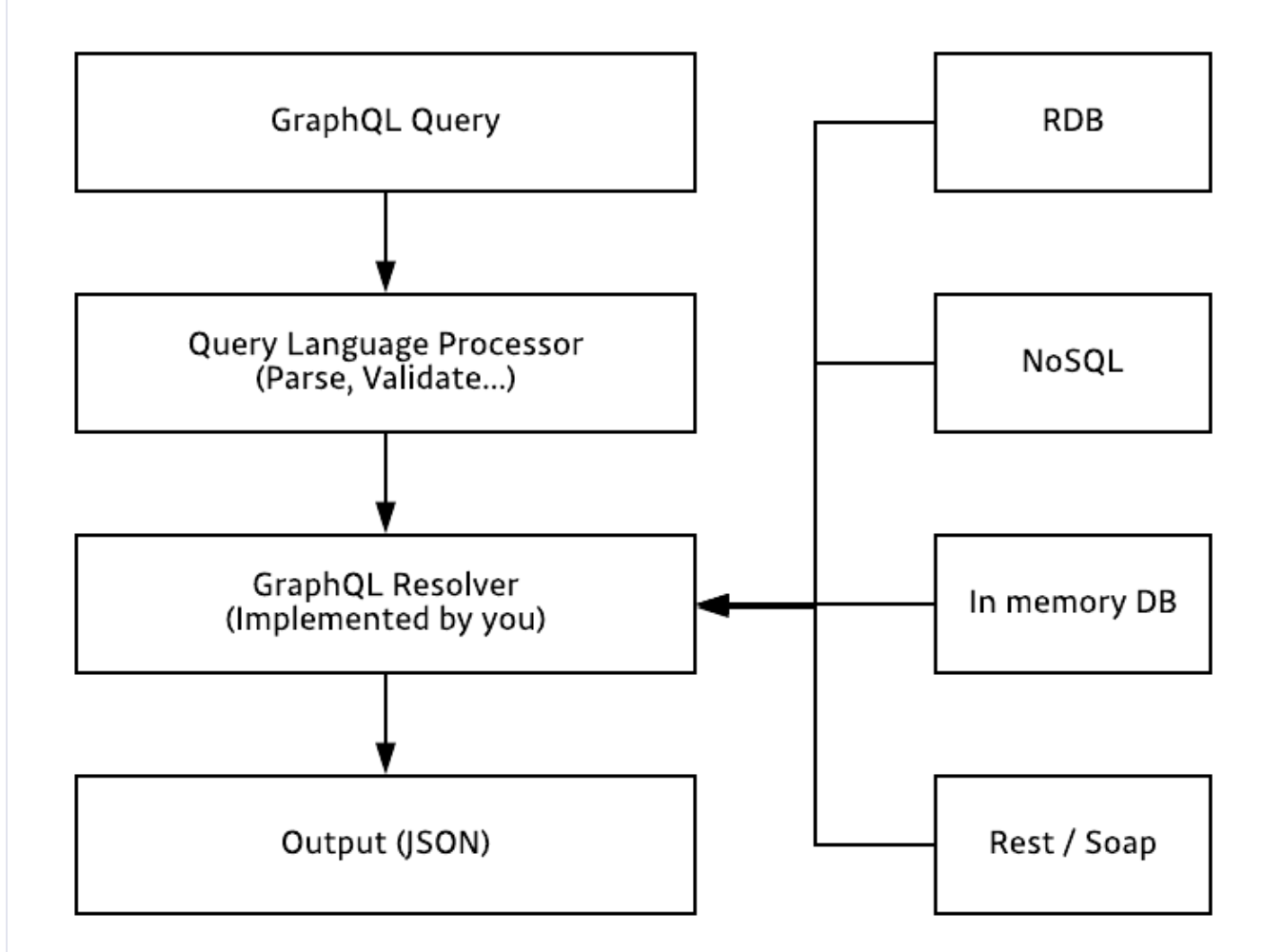
2. GraphQL vs REST API
REST API와 GraphQL API를 사용할 때와 다른 이유는 REST API를 사용할 때 URL에서 바로 진행한다. URL을 통해 Json파일을 얻어내고 그를 통해 비지니스 코드를 작성해서 프론트에서 처리한다.
-
REST API- URL, METHOD 조합으로 다양한 Endpoint가 존재
- REST API에서는 각 EndPoint마다 데이터베이스 SQL쿼리가 달라짐
-
GraphQL(gql)-
gql은 단 하나의 EndPoint가 존재
-
gql API는 gql 스키마의 타입마다 데이터베이스의 SQL 쿼리가 다름
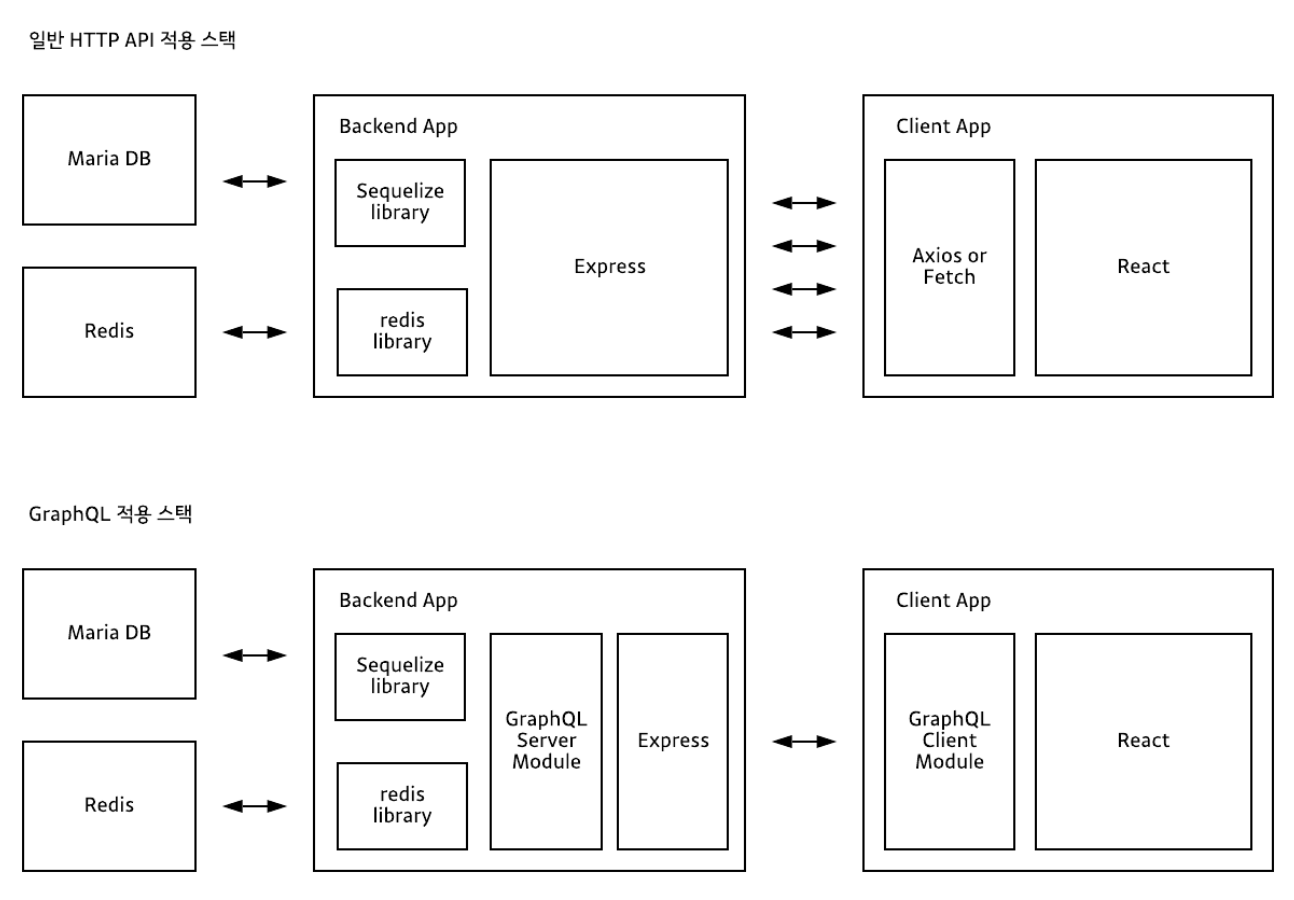
gql API를 사용하면 여러번 네트워크 호출 할 필요 없이,
한번의 네트워크 호출로 처리가 가능하다./* db.js 데이터베이스를 직접 사용한것이 아닌 API를 가져와 사용하였습니다. */ import axios from 'axios'; const BASE_URL = 'https://yts.mx/api/v2/'; const LIST_MOVIES_URL = `${BASE_URL}list_movies.json`; const MOVIE_DETAILS_URL = `${BASE_URL}movie_details.json`; const MOVIE_SUGGESTIONS_URL = `${BASE_URL}movie_suggestions.json`; console.log(MOVIE_DETAILS_URL); console.log(MOVIE_SUGGESTIONS_URL); export const getMovies = async (limit, rating) => { const { data: { data: {movies} } } = await axios(LIST_MOVIES_URL, { params: { limit, minimum_rating: rating } }); return movies; }; export const getMovie = async (id) => { const { data: { data: {movie} } } = await axios(MOVIE_DETAILS_URL, { params: { movie_id: id } }); return movie; }; export const getSuggestions = async (id) => { const { data: { data: {movies} } } = await axios(MOVIE_SUGGESTIONS_URL, { params: { movie_id: id } }); return movies; };/* resolvers.js */ import {getMovies, getMovie, getSuggestions} from './db'; const resolvers = { Query: { movies: (_, {rating, limit}) => getMovies(limit, rating), movie: (_, {id}) => getMovie(id), suggestions: (_, {id}) => getSuggestions(id) } }; export default resolvers;/* schema.graphql */ import {getMovies, getMovie, getSuggestions} from './db'; const resolvers = { Query: { movies: (_, {rating, limit}) => getMovies(limit, rating), movie: (_, {id}) => getMovie(id), suggestions: (_, {id}) => getSuggestions(id) } }; export default resolvers;
-
gql PlayGround
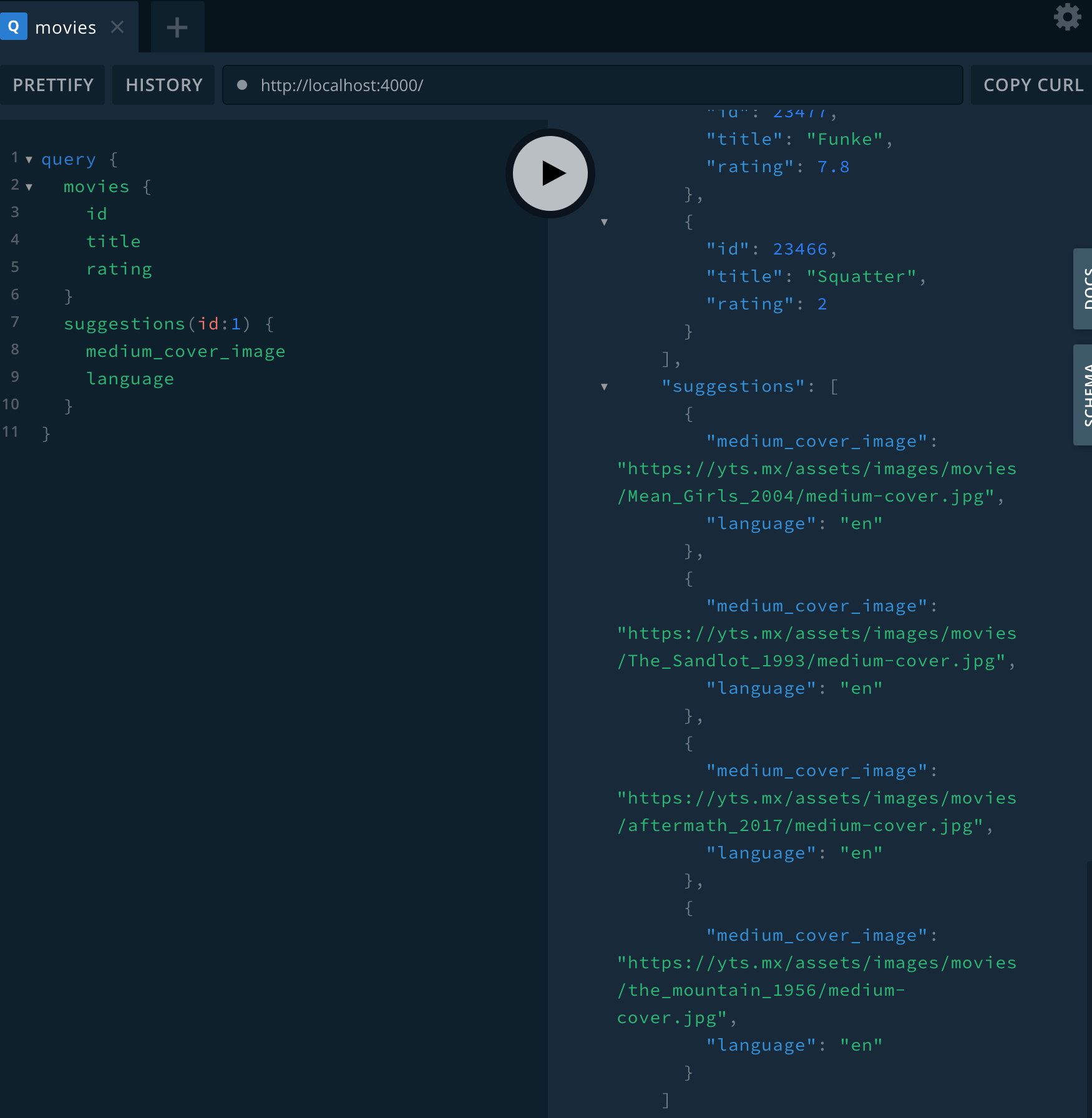
- GrapQL API는 기본적으로 위의 쿼리를 통해 데이터를 얻어온다.
- GrapQL은 Post요청만을 한다.
자바스크립트는 GraphQL을 이해하지 못한다.
import {gql} from 'apollo-boost';
/* 그래프큐엘을 임포트 해온다. */REST API와 다르게 그래프 큐엘로 해결 할 수 있는 2가지 방법
- Over-fetching: REST API를 사용하였을 경우 원하는 데이터만 테이터베이스에서 가져오는 것이 아니라 URI에 의해 할당된 데이터를 가져오기 때문에 Over-fetching하게 된다. 그에 반해 GraphQL은 자신이 원하는 정보를 쿼리문으로 정확하게 데이터를 가져올 수 있기 때문에 Over-fetching을 방지 할 수 있다.
- Under-fetching: 그와 반대로 fetching이 부족한 경우이다. 한번에 여러 데이터를 받아야 하는 경우 GraphQL에서 query로 해결이 가능하다.
GraphQL에서 URL은 존재하지 않는다. URL 체계가 없다. 하나의 end-point만이 존재 한다. 이 이유는 트리 핸들링이 가능하기 때문에 여러 데이터를 받아 올 수 있다.
즉 REST API에서 여러번 fetching 해야 하는 것을 GraphQL은 한번의 query와 end-point를 통해 원하는 데이터를 가져 올 수 있다.
3. GraphQL의 구조
쿼리/뮤테이션(query)
쿼리와 뮤테이션(업테이트, 변경) 그리고 응답의 구조는 직관적이다. 요청하는 쿼리문의 구조와 응답의 구조는 거의 일치합니다.
- GraphQL 쿼리문(좌측)과 응답 데이터 형식(우측)

gql에서는 굳이 쿼리와 뮤테이션을 나누지만 내부적으로 차이가 없다.
쿼리는 데이터를 읽는데(Read) 사용하고, 뮤테이션은 데이터는 변조(CUD) 하는데 사용한다는 개념적인 규약을 정해놓것 뿐입니다.
- query(R) : Read
- mutation(CUD): Create, Update, Delete
query getStudentInfomation($studentId: ID){
personalInfo(studentId: $studentId) {
name
address1
address2
major
}
classInfo(year: 2018, studentId: $studentId) {
classCode
className
teacher {
name
major
}
classRoom {
id
maintainer {
name
}
}
}
SATInfo(schoolCode: 0412, studentId: $studentId) {
totalScore
dueDate
}
}- 오퍼레이션 네임 쿼리는 매우 편리 합니다. 굳이 비유하자면 쿼리용 함수 입니다. 이 개념 덕분에 여러분은 REST API를 호출할때와 다르게, 한번의 인터넷 네트워크 왕복으로 여러분이 원하는 모든 데이터를 가져 올 수 있습니다.
- 데이터베이스의 프로시져는 DBA 혹은 백앤드프로그래머가 작성하고 관리 하였지만, gql 오퍼레이션 네임 쿼리는 클라이언트 프로그래머가 작성하고 관리 합니다.
- gql이 제공하는 추가 기능 덕분에 백엔드 프로그래머와 프론트엔드 프로그래머의 협업 방식 에도 영향을 줍니다. 이전 협업 방식(REST API)에서는 프론트앤드 프로그래머는 백앤드 프로그래머가 작성하여 전달하는 API의 request / response의 형식에 의존하게 됩니다. 그러나, gql을 사용한 방식에 서는 이러한 의존도가 많이 사라집니다. 다만 여전히 데이터 schema에 대한 협업 의존성은 존재합니다.
4. 스키마/타입 (schema/type)
object 타입과 필드
type Character {
name: String!
appearsIn: [Episode!]!
}- 오브젝트 타입: Character
- 필드: name,appearsIn
- 스칼라 타입: string, ID, Int 등
- 느낌표(!): 필수 값을 의미 (non-nullable)
- 대괄호([,]): 배열을 의미(array)
리졸버(resolver)
GraphQL(gql)에서는 데이터를 가져오는 구체적인 과정을 직접구현 해야 합니다. gql 쿼리문 파싱은 대부분의 gql라이브러리에서 처리, gql에서 데이터를 가져오는 구체적인 과정은 resolver가 담당하고, 이를 직접 구현 해야 합니다. 프로그래머는 리졸버를 직접 구현해야하는 부담이 있지만, 이를 통해 데이터의 source 종류와 상관없이 구현이 가능합니다. 예를 들어 resolver를 통해 데이터를 데이터 베이스에서 가져올 수 있고, 일반 파일에서도 가져 올 수 있습니다. 심지어 http,soap 와 같은 네트워크 프로토콜을 활용해서 원격 데이터 또한 가져올 수 있습니다. 이러한 특성을 사용하여 legacy 시스템을 gql 기반으로 바꾸는데에도 활용이 가능합니다.
gql 쿼리에서는 각각의 필드마다 함수가 하나씩 존재 한다고 생각하면 됩니다. 이 함수는 다음 타입을 반환합니다. 이러한 각각의 함수를 resolver라고 합니다. 만약 필드가 스칼라 값인 경우에는 실행이 종료됩니다. 하지만 필드의 타입이 스칼라 타입이 아닌 우리가 정의한 타입이라면 해당 타입의 리졸버를 호출되게 됩니다.
이러한 연쇄 리졸버 호출은 여러모로 장점이 있습니다. 연쇄 리졸버 특성을 잘 활용하면 DBMS의 관계에 대한 쿼리를 매우 쉽고, 효율적으로 처리 할 수 있습니다.
예를 들어 gql의 query에서 어떤 타입의 필드 중 하나가 해당 타입과 1:n의 관계를 맺고 있다고 가정해보겠습니다.
type Query {
users: [User]
user(id: ID): User
limits: [Limit]
limit(UserId: ID): Limit
paymentsByUser(userId: ID): [Payment]
}
type User {
id: ID!
name: String!
sex: SEX!
birthDay: String!
phoneNumber: String!
}
type Limit {
id: ID!
UserId: ID
max: Int!
amount: Int
user: User
}
type Payment {
id: ID!
limit: Limit!
user: User!
pg: PaymentGateway!
productName: String!
amount: Int!
ref: String
createdAt: String!
updatedAt: String!
}여기에서는 User와 Limit는 1:1의 관계이고 User와 Payment는 1:n의 관계입니다.
{
paymentsByUser(userId: 10) {
id
amount
}
}{
paymentsByUser(userId: 10) {
id
amount
user {
name
phoneNumber
}
}
}위 두 쿼리는 동일한 쿼리명을 가지고 있지만, 호출 되는 리졸버 함수의 갯수는 아래가 더 많습니다. 각각의 리졸버 함수에는 내부적으로 데이터베이스 쿼리가 존재합니다.
이 말인즉, 쿼리에 맞게 필요한 만큼만 최적화하여 호출 할 수 있다는 의미입니다. 내부적으로 로직 설계를 어떻게 하느냐에 따라서 달라 질 수 있겠지만, 이러한 재귀형의 리졸버 체인을 잘 활용 한다면, 효율적인 설계가 가능 합니다. (기존에 REST API 시대에는 정해진 쿼리는 무조건 전부 호출이 되었습니다.)
리졸버 함수는 다음과 같이 총 4개의 인자를 받습니다.
Query: {
paymentsByUser: async (parent, { userId }, context, info) => {
const limit = await Limit.findOne({ where: { UserId: userId } })
const payments = await Payment.findAll({ where: { LimitId: limit.id } })
return payments
},
},
Payment: {
limit: async (payment, args, context, info) => {
return await Limit.findOne({ where: { id: payment.LimitId } })
}
}- 첫번째 인자는 parent로 연쇄적 리졸버 호출에서 부모 리졸버가 리턴한 객체입니다. 이 객체를 활용해서 현재 리졸버가 내보낼 값을 조절 할 수 있습니다.
- 두번째 인자는 args로 쿼리에서 입력으로 넣은 인자입니다.
- 세번째 인자는 context로 모든 리졸버에게 전달이 됩니다. 주로 미들웨어를 통해 입력된 값들이 들어 있습니다. 로그인 정보 혹은 권한과 같이 주요 컨텍스트 관련 정보를 가지고 있습니다.
- 네번째 인자는 info로 스키마 정보와 더불어 현재 쿼리의 특정 필드 정보를 가지고 있습니다. 잘 사용하지 않는 필드입니다.
5. 인트로스펙션(introspection)
기존 서버-클라이언트 협업 방식에서는 연동규격서라고 하는 API 명세서를 주고 받는 절차가 반드시 필요 했습니다. 프로젝트 관리 측면에서 관리해야 할 대상의 증가는 작업의 복잡성 및 효율성 저해를 의미합니다. 이 API 명세서는 때때로 관리가 제대로 되지 않아, 인터페이스 변경 사항을 제때 문서에 반영하지 못하기도 하고, 제 타이밍에 전달 못하곤 합니다.
실제로 저도 Express와 React 실습을 할때 백엔드에서 Postman을 이용한 API doc를 제시하여 프론트 작업을 했는데 제 때 업데이트가 되지 않아 여러번 문의 했던 기억이 납니다.
이러한 REST의 API 명세서 공유와 같은 문제를 해결하는 것이 gql의 인트로스펙션 기능 입니다. gql의 인트로스펙션은 서버 자체에서 현재 서버에 정의된 스키마의 실시간 정보를 공유를 할 수 있게 합니다. 이 스키마 정보만 알고 있으면 클라이언트 사이드에서는 따로 연동규격서를 요청 할 필요가 없게 됩니다. 클라이언트 사이드에서는 실시간으로 현재 서버에서 정의하고 있는 스키마를 의심 할 필요 없이 받아들이고, 그에 맞게 쿼리문을 작성하면 됩니다.
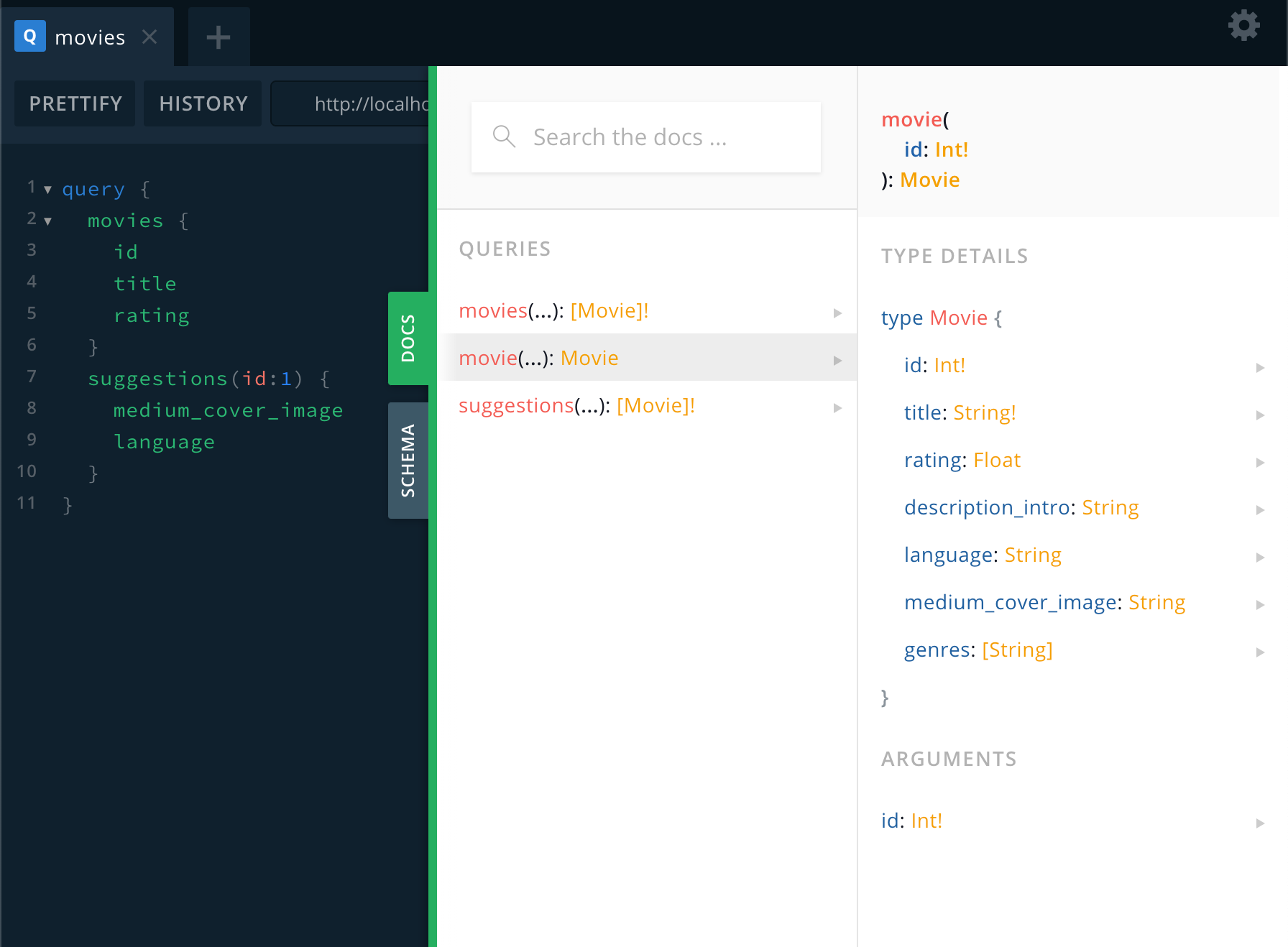
6. 실제 GraphQL로 비지니스 로직 작성하기
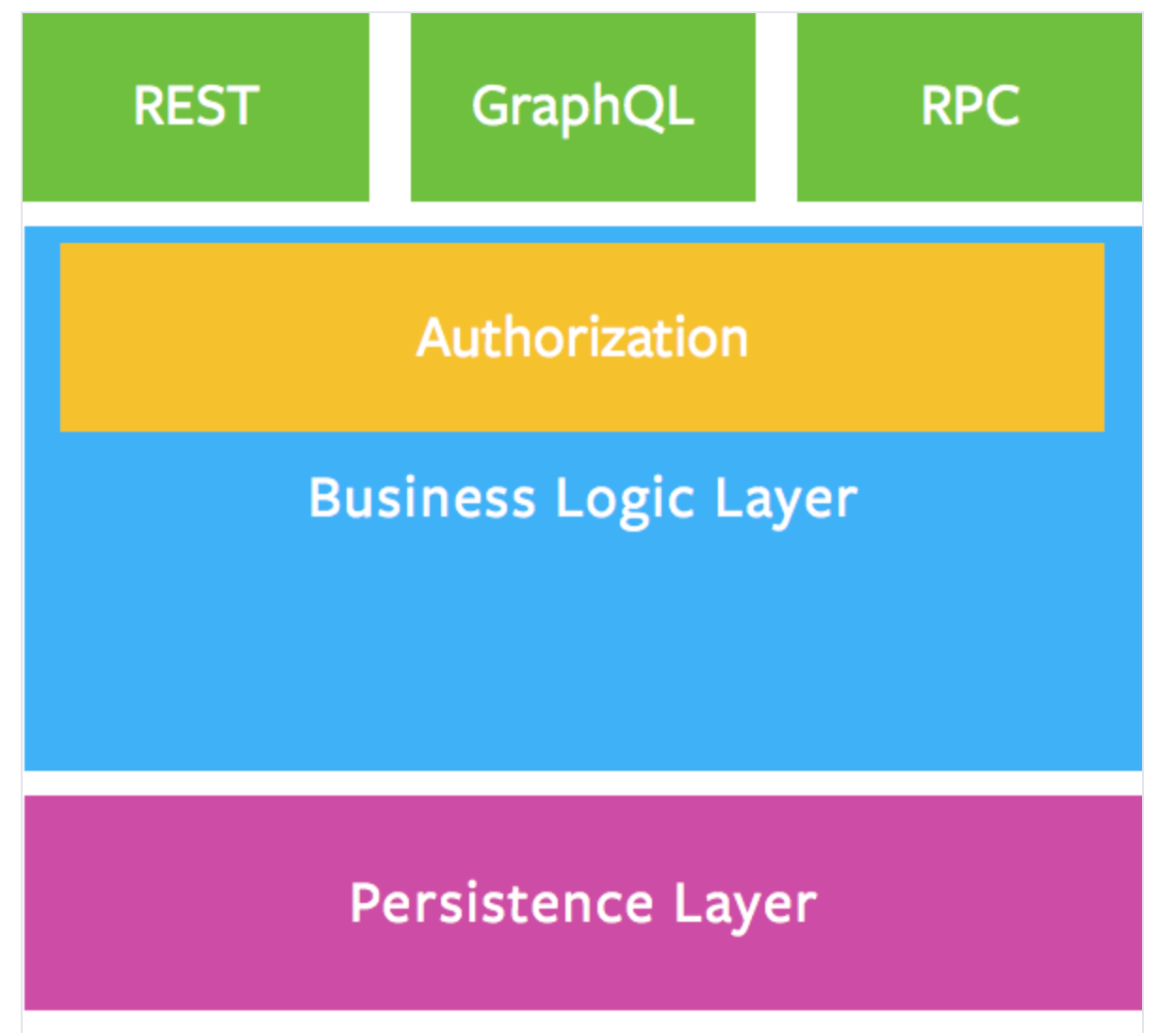
- 구현시, 비지니스 로직은 실제 리졸버 함수에 담지 않습니다.
requestPaymentSession: async (parent, {
pgId, name, sex, birthDay, phoneNumber, amount, productName, ref
}, context, info) => {
const ret = await requestPaymentSession({ pgId, name, birthDay, phoneNumber, sex, amount, productName, ref })
return removeSymbol(ret)
},
requestPaymentApprove: async (parent, {
sessionKey, authNumber
}, context, info) => {
const ret = await requestApprovePayment({ sessionKey, authNumber })
return removeSymbol(ret)
}7. 정리
-
GraphQL는 API를 만들 때 사용할 수 있는
쿼리언어입니다. 그와 동시에 쿼리에 대한 데이터를 받을 수 있는 런터임이기도 합니다. -
GraphQL은 SQL과 같은 쿼리언어지만 구조적으로 다르다.
- sql의 문장(statement)은 주로 백앤드 시스템에서 작성하고 호출 하는 반면, gql의 문장은 주로 클라이언트 시스템에서 작성하고 호출 -
GraphQL vs REST API
-
GraphQL은 하나의 엔드포인트를 가지며 POST요청으로 이루어져 있는 반면, REST API는 여러 개의 메소드를 가지고 있으며 여러 엔드포인트를 가진다.
-
REST API는 엔드포인트에 따라 데이터베이스의 쿼리가 바뀌며, gql은 스키마에 따라 쿼리가 바뀐다.
-
GraphQL의 구조는 크게 쿼리와 뮤테이션으로 이루어져 있으며 쿼리는 Read, 뮤테이션은 CUD를 담당한다. 각각의 구조는 비슷하며 역할만 다르다.
-
GraphQL-Resolver
- GraphQL(gql)에서는 데이터를 가져오는 구체적인 과정을 직접 구현 해야 한다. gql 쿼리문 파싱은 대부분의 gql라이브러리에서 처리해주고, gql에서 데이터를 가져오는 구체적인 과정은 resolver 담당한다. -
resolver를 통해 데이터를 데이터 베이스에서 가져올 수 있고, 일반 파일에서도 가져 올 수있다. 심지어 http,soap 와 같은 네트워크 프로토콜을 활용해서 원격 데이터 또한 가져올 수 있다.
-
resolver 특성을 통해 ****legacy 시스템을 gql 기반으로 바꾸는데에도 활용이 가능하다.
-
GraphQL의 인트로스펙션(introspection)을 통해 doc를 실시간 정보 공유가 가능하며 연동규격서를 따로 작성할 필요가 없어진다.
Reference
