메이플 주문서 시뮬레이터에 댓글 작성 기능이 추가되었습니다.
JPA 환경에서 댓글 엔티티(Comment)를 정의하고 사용자가 보내온 댓글 작성 요청에 맞추어 Comment 테이블에 댓글 정보가 저장됩니다. 댓글의 비밀번호는 SHA256 알고리즘으로 암호화되어 특정 자릿수 까지 잘라 데이터베이스에 저장되고, 댓글을 삭제하기 위해서는 이 암호화된 비밀번호 정보가 일치해야만 합니다.
댓글을 등록하는 기능은 간단했지만 고민되는 점은 조회부분에 있었습니다.
댓글의 정보를 한번에 불러오는 것이 아니라 페이지네이션을 통해서 일부분만 불러오고자 하였고, 그래서 초기에는 댓글창을 이동시킬 수 있는 페이지 번호를 부여하고 사용자가 직접 페이지를 이동시키도록 구현하였습니다. 하지만 이런 사소한 동작도 단지 댓글을 보기 위해서 사용자가 처리하기에는 귀찮을 수 있습니다. 그래서 무한 스크롤을 이용해서 특정 범위까지 사용자가 스크롤을 내리면 자동으로 다음 댓글을 불러오는 구조를 선택했습니다.
일반적인 페이지네이션
일반적으로 JPA, QueryDSL를 사용해서 페이지네이션을 한다고 하면 URI의 쿼리 스트링으로 page, size등의 정보를 넘기고, Controller에서 Pageable 타입으로 페이지네이션 정보를 받아 페이징 정보를 사용해 쿼리를 수행합니다. 그때 일반적으로 수행되는 쿼리는 다음과 같습니다.
SELECT Comment
FROM Comment
WHERE (조건문)
ORDER BY comment_id desc
LIMIT (페이지 사이즈)
OFFSET (페이지 번호)댓글은 가장 최근의 것부터 조회해야하기 때문에 comment_id를 기준으로 내림차순으로 정렬해 주었습니다.
하지만 이 쿼리의 문제점은 OFFSET, LIMIT 쿼리는 OFFSET부분 부터 행을 읽는 것이 아니라 처음부터 행을 읽어가기 때문에 테이블에 데이터가 많아질 수록 조회시간이 오래 걸립니다.
예를 들어서 OFFSET 100,000 LIMIT 40 과 같은 쿼리를 작성했을 때, 딱 100,000번째 행으로 찾아가서 그때부터 40개의 행을 읽는 것이 아니라 처음부터 100,000개의 행을 읽고 그제서야 응답에 사용할 40개의 행을 추가적으로 읽는 것입니다. 그러므로 읽어야할 데이터가 테이블의 뒤에 위치할 수록 조회시간이 많이 걸립니다.
No Offset
No Offset 방식은 마지막으로 읽은 데이터의 정보를 기억해두고, 그 정보와 인덱스를 활용해서 조회 시작지점을 빠르게 찾아내는 방법입니다. MySQL은 기본적으로 PK가 있으면 PK를 기준으로 클러스터 인덱스를 생성합니다. 즉 이전과는 다르게 처음부터 조회부분을 찾아가는 것이 아니라 인덱스를 이용해서 한번에 조회 시작 부분을 찾아갈 수 있기 때문에 성능이 향상됩니다.
SELECT Comment
FROM Comment
WHERE comment_id < (마지막으로 읽은 id) and item_id = (현재 item id)
ORDER BY comment_id
LIMIT (페이지 사이즈)10,000 번째 행부터 40개를 읽어야한다고 가정해보겠습니다.
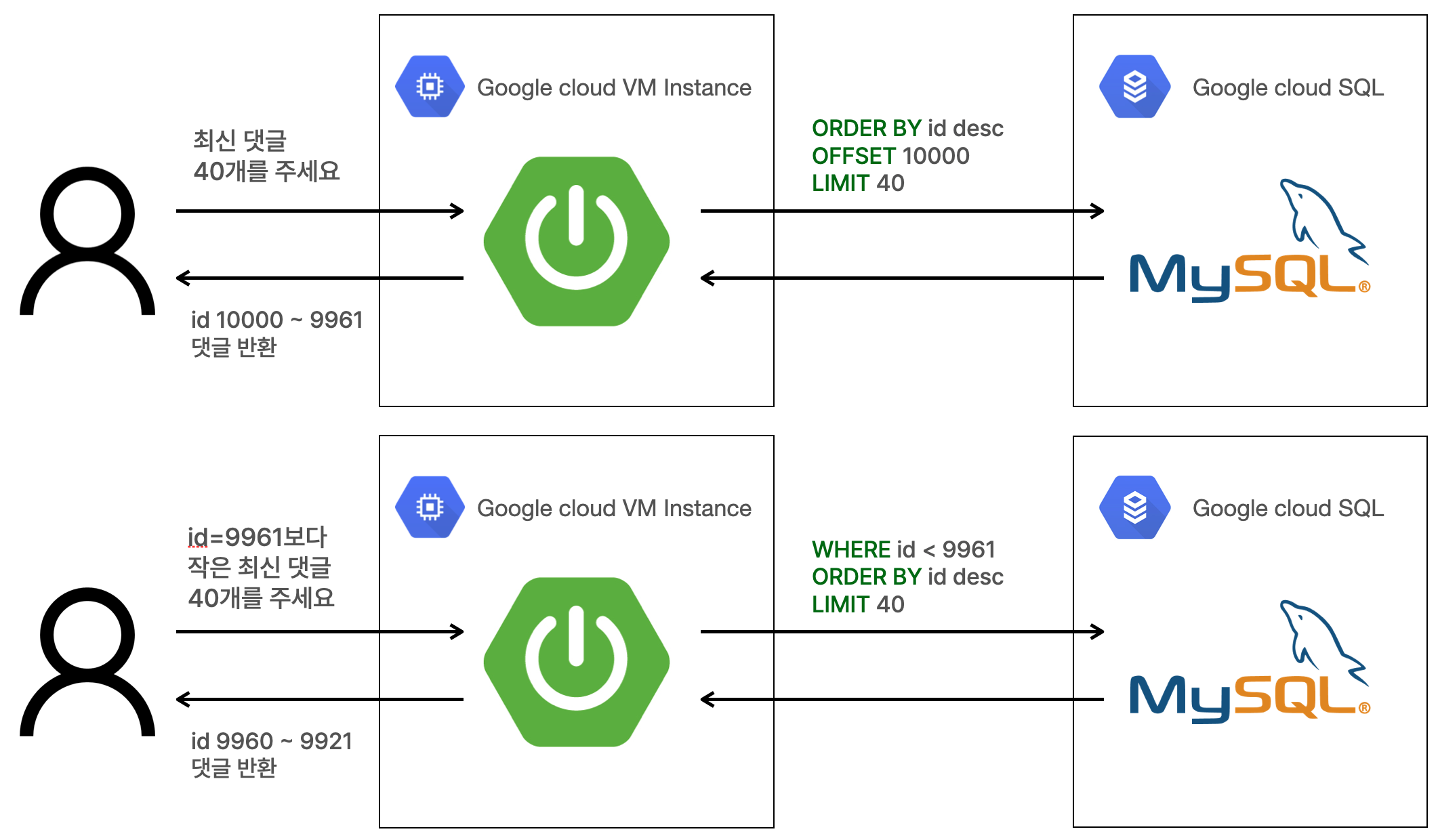
위의 방법에서 아래의 방법으로 수정된 것이고, 이를 QueryDSL 코드로 나타내면 다음과 같습니다.
실제 코드에서는 특정 아이템에 해당하는 댓글 정보만 가져와야하기 때문에 item_id의 일치 여부를 따지는 코드가 포함되었습니다.
public List<CommentResponse> paginationNoOffsetComment(
final Long commentId,
final Long itemId,
final int pageSize
) {
return queryFactory
.select(
Projections.fields(
CommentResponse.class,
comment.id.as("commentId"),
comment.name,
comment.content,
comment.createdDate
)
)
.from(comment)
.where(
ltCommentId(commentId),
comment.item.id.eq(itemId)
)
.orderBy(comment.id.desc())
.limit(pageSize)
.fetch();
}첫 페이지를 호출할 때는 마지막으로 읽은 comment_id를 전달할 수 없기 때문에 별도의 로직이 필요합니다. ltCommentId() 메서드를 살펴보면 요청으로 전달받은 commentId 정보가 null일 때 null을 반환합니다. QueryDSL의 where 함수에 null을 전달하면 조건이 무시되는 것을 특징을 활용해서 동적인 쿼리를 작성할 수 있습니다.
private BooleanExpression ltCommentId(Long commentId) {
if (commentId == null) {
return null;
}
return comment.id.lt(commentId);
}실제 성능차이
실제로 성능차이를 실험해보고 싶었지만 추가한지 얼마되지 않은 기능이고, 유의미한 성능차이를 보이려면 최소 수십만개 이상의 행이 추가되어야 하기 때문에 테스트 데이터베이스를 생성한 후 따로 실험을 진행했습니다.
테스트 환경
- 테스트 DB
-Google Cloude SQLvCPU 1개RAM 3.75GB - 테스트 테이블
- 컬럼 4개- 100만 row
먼저 테스트를 위해서 Comment 테이블을 만들었습니다. No Offset 조회 성능만 테스트할 것이기 때문에 Item 테이블을 따로 만들고 연관관계를 맺어주는 과정은 생략했습니다.
CREATE TABLE comment(
comment_id bigint NOT NULL AUTO_INCREMENT,
name varchar(255) not null,
content varchar(255) not null,
password varchar(255) not null,
PRIMARY KEY (comment_id)
);그 다음 프로시저를 사용해서 100만개의 댓글 행을 추가 해주었습니다.
delimiter $$
create procedure insertComments()
begin
declare i bigint default 1;
while (i <= 1000000) do
insert into comment(name, content, password)
values (concat('member', i), concat('content', i), '12345');
set i = i + 1;
end while;
end$$
delimiter ;
call insertComments();물론 클러스터링 인덱스로 PK인 comment_id에 대해서 인덱스가 걸려있습니다.

먼저 No Offset 방식이 아닌 일반적인 페이징쿼리의 처리 속도를 살펴보겠습니다.

다음은 No Offset 방식의 쿼리입니다.

No Offset 방식이 36ms 로 326ms인 일반적인 페이징 방식보다 대략 9~10배정도 더 빠른 것을 볼 수 있습니다. row의 갯수가 늘어나면 늘어날수록 성능의 차이도 더 늘어날 것입니다.
단점
- 조건문에 사용하는 key값에 중복이 존재하는 경우 정확한 결과를 반환할 수 없습니다.
- 서비스 운영상 무한 스크롤이나 더보기 방식이 아닌 페이지 버튼을 사용해야 한다면 No Offset을 사용할 수 없습니다.
- No Offset 방식은 순차적인 페이징만 가능합니다. 페이지를 여러개 건너뛰는 동작은 불가능합니다.
