[AI] Deepfake(Deep learning+Fake)
Deepfake(Deep learning+Fake)
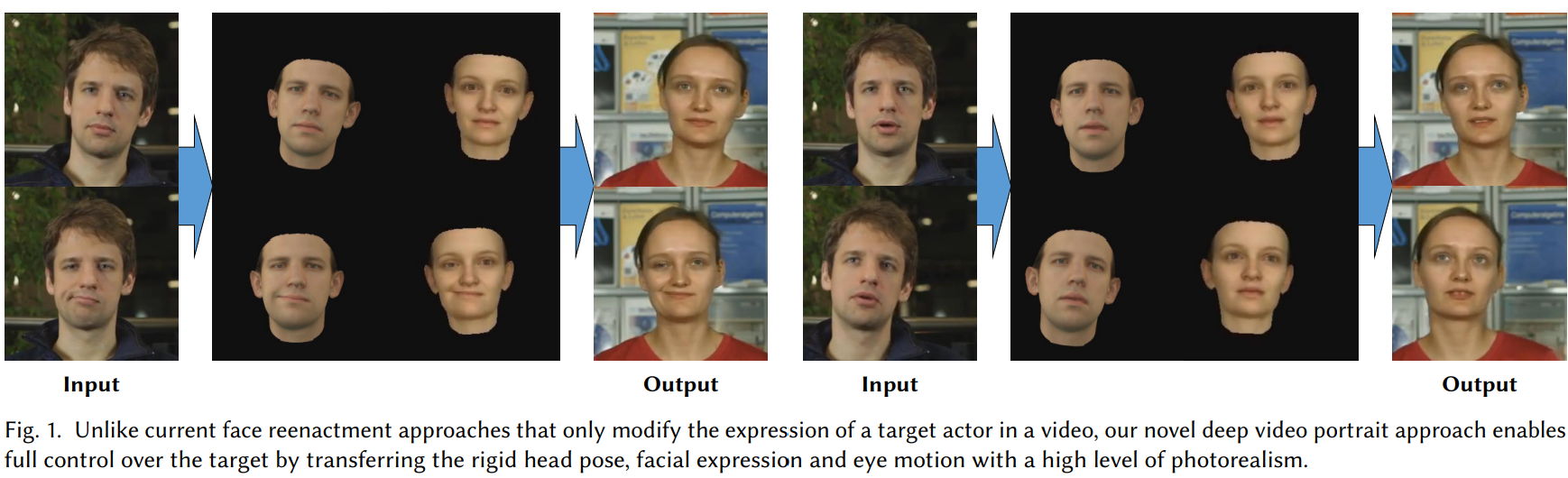
Target actor가 Source actor를 모사(mimic)하도록 비디오 영상을 합성하는 딥러닝 기술이다. 위의 이미지를 보면, source인 남성 영상을 input으로 주었을 때, taret인 여성의 비디오가 이를 mimic하여 ouput을 출력한다.
Deep Video Portraits
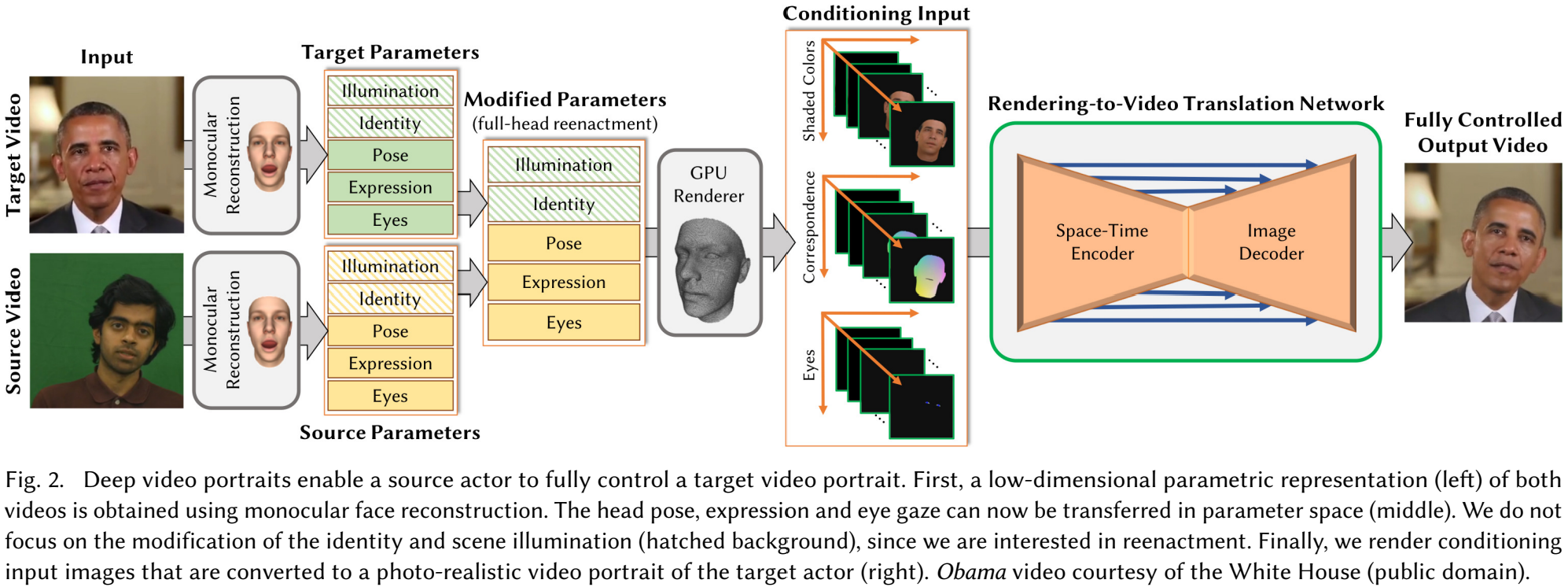
Deep video portraits는 source actor가 완전히 target actor를 제어할 수 있게 한다. 우선, 단안 얼굴 재구성을 통해 두 비디오의 저차원 파라메트릭 표현(왼)을 얻는다. 머리 포즈, 표정 및 눈 시선 정보를 파라메트릭 공간(중간)로 전달한다. 이떄, 재연에 관심이 있기 때문에 신원(identity)나 장면 조명(해킹된 배경)의 수정에는 초점을 두지 않는다. 마지막으로, 변환된 조건부 입력 이미지를 target actor의 사실적인 비디오(photo-realistic) 초상화로 렌더링한다(오른쪽).
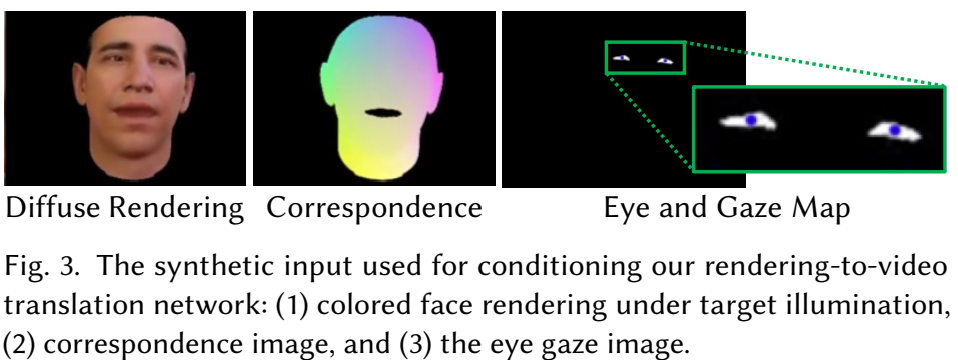
합성된 인풋은 조건부로 렌더링-비디오 변환 네트워크를 조절하는 데 사용한다.
(1) 대상 조명 아래에서 컬러 얼굴(colored face) 렌더링
(2) 대응 이미지
(3) 시선 이미지
Key points
핵심 기술은 Monocular Face Reconstruction, Sythetic Conditioning Input, Rendering-to-video Translation이다. 이 세 가지 기술은 모두 Deepfake 비디오 생성 과정에서 서로 연계되어 작동하며, 최종적으로 매우 현실적인 결과물을 낸다.
- Monocular Face Reconstruction:
- 단일 이미지에서 3D 얼굴 구조를 재구성
- Synthetic Conditioning Input: 얼굴 표정, 조명 등 특정 조건을 합성
- Rendering-to-Video Translation:
- 3D 렌더링된 얼굴이나 장면을 실사 같은 비디오로 변환
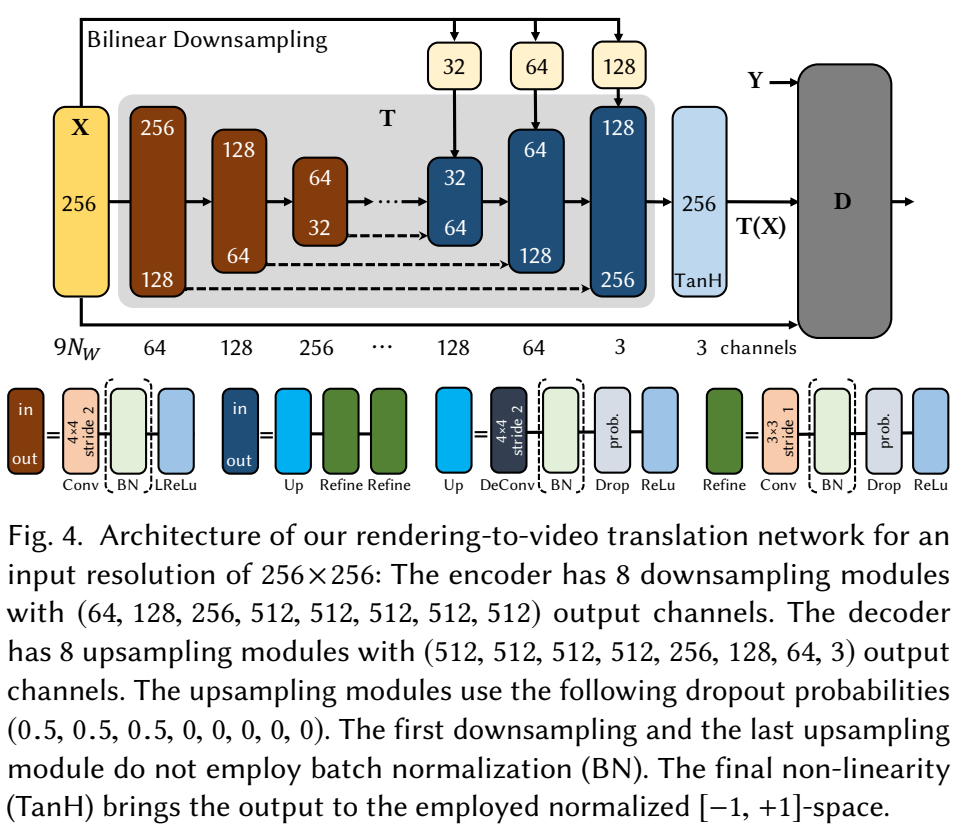
Rendering-to-Video Translation network는 아래와 같이 구성되어 있다. 256*256 해상도로, encoder가 8개의 다운샘플링 모듈로 구성되어, (64, 128, 256, 512, 512, 512, 512, 512)의 output channel을 갖고 있다. Decoder는 8개 업샘플링 모듈로 구구성되어(512, 512, 512, 512, 256, 128, 64, 3)의 output channel을 갖는다. 업샘플링 모듈은 dropout 확률로 (0.5, 0.5, 0.5, 0, 0, 0, 0, 0)을 갖는다. 첫번 째 다운샘플링과 마지막 업샘플링 모듀은 Batch normalization을 쓰지 않는다. 마지막 비선형성(non-liearity)는 TanH이고, 이는 정규화된 [-1, +1]의 공간을 갖는다.
[1] Deep Video Portraits, https://arxiv.org/pdf/1805.11714
