LLM 의 이해
LLM(large language model)
LM(Lanugage Model)에서는 모델 네트워크의 hidden layer, node, 데이터의 parameter 조정 등으로는 월등한 성능 향상이 보이지 않았다. 이에, 모델의 parameter를 기하급수적으로 증가시켜 모델 성능을 테스트하였고, B(Billion)일 때, 모델의 성능이 월등히 향상된다는 것을 알 수 있었다. 이에 LLM(large language model)이 생겨났다.
- LM 의 성능은
매개 변수(Embedding layer) 제외,
학습 토큰 수(학습 자료 크기),
학습 계산량(학습 시간)에 따라 결정된다.
LLM History & Paradigm
Timeline
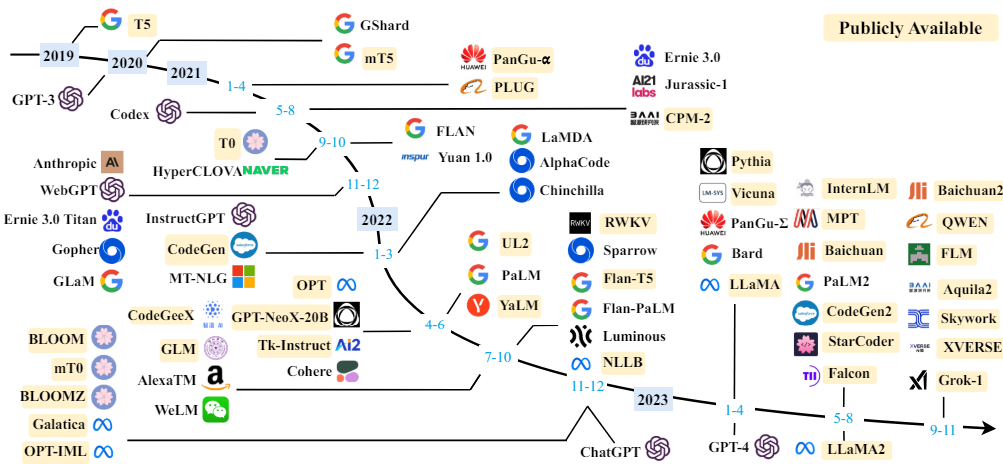
그림 : A timeline of existing large language models (having a size larger than 10B) in recent years.
(자료 : Wayne Xin Zhao, et al, A Survey of Large Language Models, 2023.)
Evloution
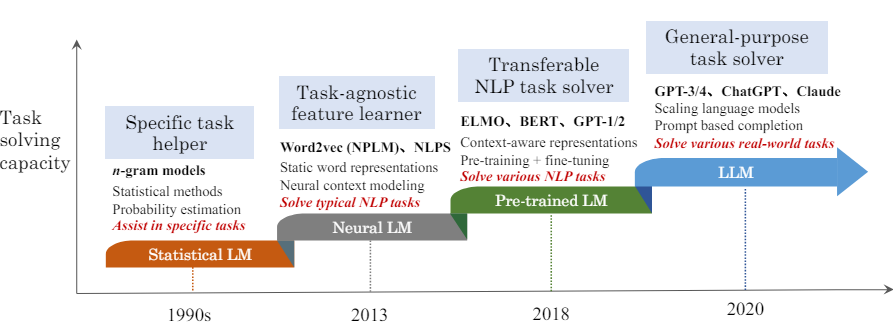
그림 : An evolution process of the four generations of language models (LM)
(자료 : Wayne Xin Zhao, et al, A Survey of Large Language Models, 2023.)
Paradaigm
| Pradaigm | Eneering | Task Relationships | Example |
|---|---|---|---|
| Fully supervised training (Machine Learning) | Feature Egineering | LS, LM, Tag, GEN | (general) Machine learning |
| Fully supervised training (Deep Learning) | Model Architecture | LS, LM, Tag, GEN | Deep Learning (Convoluiton, RNN, Transformer) |
| Pre-train, Fine-tune | Objective(MLM, NSP, etc) | LM to CLS, TAG, GEN | BERT, GPT-1 |
| Pre-train, Prompt, Predict | Prompt | LM to CLS, TAG, GEN | GPT-3 |
Comparison LLM
| Proprietray LLM | Open-weight LLM | |
|---|---|---|
| Service | OpenAI ChatGPT, Google Geminit/Bard | LLama3, StableLM, Mixtral |
| Quality | Very Good | Good |
| Price | 적은 초기 비용, (생각보다) 적당한 유지비용 | 많은 초기 비용, 적은 유지 비용 |
| Infra | 설비 구축 및 관리 최소화 | 자체 설비 구축 및 관리 |
| Security | 데이터 외부 유출 우려 | 데이터 유출 우려 없음 |
Scaling Law
더 큰 모델일 수록, 더 작은 샘플(데이터 셋)을 필요하다. 그리고, 일정 수준에 성능(loss)에 도달하면, 수렴하게(saturated) 된다. 최적의 모델 크기는 목표 loss 값과 학습 계산량에 따라 점진적으로 증가한다.
투입 계산량이 정해지면, 모델크기와 학습 자료의 크기는 최적의 값이 존재한다.
학습자료의 크기가 정해지면 최적 모델 크기가 결정된다.
In-context Learning
대형언어 모델에서 Fine-tuning 대신에 적용하는 방법론이다. 언어모델을 prompt와 함께 사용하여 목표 Task를 수행한다. 언어모델에 Prompt를 입력하여 목표 Task에 최적화하도록 한다.
언어모델 + Prompt = Target Task(Optimization)
이때, 예제(Example, Demonstraion)를 추가
- Few-shot : 여러 개의 예시와 Task 설명문(Description, Instruction)을 참고해 정답 예측.
One-shot이나 Zero-shot 보다 성능이 좋음 - One-shot : 하나의 예시와 Task 설명문을 참고해 정답 예측
- Zero-shot : 예시 없이, Task 설명문을 참고해 정답 예측
Incontext Learning을 적용하면, 모델의 응용, 이해 능력이 개선된다는 것을 알 수 있다.
또한, 매개 변수가 7B 이상부터는 몇몇 Task에서 정확도에서 우수한 성능을 보인다.
Ergent Abilities
이러한 대형 모델인, LLM에서는 이전의 작은 모델에서는 나타나지 않던 능력을 갑자기 발현(emergent)한다.
- Arithmetic
- Translitertae
- Word unscramble
- QA
- Grounded mappings
- Multi-task NLU
- Word in Context 등
Alignment Tuning
챗(chat)에 맞게 추가로 조금 더 학습 하는 것이다. LM의 문제점은 단순히 다음 다음 단어를 맞추는 모델이다. 그래서 랜덤 샘플링(random sampling)했지만 그때마다 답이 다르게 나올 수 있다.
즉, Prompt를 통해 특정 Task를 풀는 것에 최적화 되어 있지 않아서, zero-shot의 정확도가 크게 달라진다. 이러한 문제를 해결하기 위해서 모델이 사용자 의도에 맞게 Prompt를 해석하도록 만들게 되었다.
Instruct Tuning
많은 빈도로 질문될 것같은 내용들을 가져와서 추가로 학습하는 것이다. 이는 Alignment Learning에 포함된다. 즉, 다양한 Task를 Template을 통해 Prompt 형태로 학습한다.
예를 들면, Premise, Hypothesis, Target 각각의 내용을 하나의 Prompt에서 Template 처럼 묶어서 구성하도록 한다.
-
NLI(natural language inference) Task 예시
-
Premise전제 -
Hypothesis가정 (논리 관계: 내포, 모순, ...) -
Target목표↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓
-
Template 1- Premise, Hypothesis, Target
... -
Template n- Premise, Hypothesis, Target
-
Instruct Tuning을 위한 각 태스크별 데이터셋은 NLU/NLG로 구분할 수 있다. NLU Task 데이터셋을 학습하면, NLG task를 잘 수행하는 것을 확인할 수 있다.
-
NLU Task & Dataset
- NLI - ANLI, RTE, CB, SNLI, SNLI, WNLI, QNLI
- Commonsense - CoPA, HllaSwag, PiQA, StoryCLoze
- Sentiment - IMDB, Sent140, SST-2, Yelp
- Paraphrase - MRPC, QQP, PWS, STS-B
- Closed-book QA - ARC, NQ, TQA
- Reading Comprehension - BoolQ, OBQA, DROP, SQuAD, MultiRC
- Reding Comprehesion with Commonsense - CosmosQA, ReCoRD
- Conference - DPR, Winogrande, WSC273
- Miscellaneous- CoQA, TREC, QuAC, CoLA, WIC, Math, Fix Punctuation
-
NLG Task & Dataset
- Struct to Text - CommonGen, DART, E2ENLG, WEBNLG
- Summarization - AESLC, Mult-News, SamSum, AG News, Newsroom,
Wiki Lingua EN, CNN-Dm, Opin-Abs(iDebate, Movie), XSum, Gigaword - Translation - ParaCralw (EN/ES, EN/FR),
WMT-16(EN/CS, EN/DE, EN/FI, EN/RO, EN/RU, EN/TR)
이러한 기법을 적용하면, 한 번도 보지 못한 Task에 대해서 Zero-shot 정확도를 향상시킬 수 있다.
※Held-out Task : 한번도 보지 못한 Task
하지만, Instruction Tuning은 다음 단어를 예측하는 LM을 학습하기 때문에, 그럴듯하지만 (정답으로) 맞는 응답을 내서 Loss가 발생할 수 있다. 즉, 정답 외에는 모두 오답으로 간주하여 학습에 방해가 된다.
이를 해결하기 위해서 인간의 선호도를 반영한 Preference Tuning 기법을 적용하였다.
RLHF(Reinforcement Learning Human Feedback)
인간이 직접 정답을 만들고, 정답마다 점수를 다르게 매겨 모델이 출력에 리워드를 주어 강화학습하는 것이다.
- 01 SFT(Supervised Fine-Tunitng)
- 질의/응답 데이터를 모아서 지도학습 형태로 언어 모델을 훈련한다.
- 02 RM(Reward Modeling)
- 생성된 여러 답안에 대한 사람의 선호도 데이터를 수집하여 점수 측정 모델을 훈련한다.
- 03 RL(Reinforcement Learning)
- 점수 측정 모델은 언어 모델을 강화학습으로 훈련하도록 활용한다.
Keyword
SFT(Supervised Fine-Tunitng),
RM(Reinforcement Model),
RL(Reinforcement Learning)
DPO(Direct Preference Optimization)
그러나, 강화학습은 복잡하고 안정적이지 안다는 한계가 있다. 그래서 학습 과정 중에 LLM으로 Text Generation이 필요하다. 별도의 Reward Model을 학습하고, RL 학습시, RM을 추론해야한다.
이를 극복한 것이 DPO이다. RL 학습 없이 사전에 Prerence 데이터를 학습하여 확률적으로 예측하는 것이다. 수학적으로는 RLHF와 동등하지만, 직관적으로 학습할 수 있다. 즉, LLM이 Prefrence 학습 중에 스스로 암시적인 Reward를 학습한다. 하지만, 사람이나 모델의 평가가 반대될 수 있다.
Alignment Tuning 주의 사항
- Preference는 정의에 따라 다르다
- Down Stream Task의 정확도가 하락(Alignment tax)할 수 있다
- 모델에 새로운 지식이나 능력을 주입하지는 않지만,
모델 내에 있는 지식이나 능력을 이끌어 낸다.
Prompt Engineering
LLM은 단계적인 논리전개나 풀이를 생각하지 않는다. 그래서, 이를 해결하기 위해 Prompt를 잘 만들어서 해결해 나가는 방법이 필요하다.
COT(Chain-of Thought)
Prompt를 잘 구성하여 정답을 유도하도록 한다. COT는 사고의 체인이라고 볼 수 있다. Anser를 내기 전에 풀이나 과정을 주어서 답을 유도하고, LLM이 단계적인 논리 추론을 할 수 있도록 모사한다.
이를 통해서, LLM이 잘 풀지 못했던 Arimetic, Commonsense, Symbolic Reasoning 문제들의 정확도가 향상되었다. 몇몇 벤치마크는 supervised-learning 보다 좋은 나은 성능(정확도)을 보였다.
*Example
- Q. 아침에 3개를 먹고, 저녁에 사과 4개를 먹었다. 그럼 최종 몇 개의 사과를 먹은 것일까?
- COT.
아침에 3개, 저녁에 4개를 먹었으니까, 3+4=7 이다. - A. (그래서) 7개
- 특징
- Emegernt Ability
- Natural Lanauge로 상세히 작성(with Equation, Variable...)
- 답안 생성 결과는 이전 생성 과정에 영향을 주지 않음
Zero-shot COT
하나의 예시를 참조하여 답을 내기 때문에 풀이과정 중에 문제가 있을 수 있다.
- Q. 아침에 3개를 먹고, 저녁에 사과 4개를 먹었다. 그럼 최종 몇 개의 사과를 먹은 것일까?
A. 아침에 3개, 저녁에 4개를 먹었으니까, 3+4=7 이다. 정답은 7개이다. - Q. 요리하면서 당근을 2개는 수프에 넣고, 나머지 2개는 샐러드에 넣었다. 당근을 모두 몇 개 쓴 걸까?
A. 당근을 수프에 2개먹고, 샐러드에 2개를먹었으니까, 2+2=4 이다. 정답은 4개이다.
Self-Consistency
COT와 Zero-shot COT에서는 다양한 문제 풀이를 적용하기 어려울 수 있다. 이를 해결하고 좀 더 정확한 답을 내기 위해서, 다양한 풀이(sampling)와 교차 검증을 할 수 있다. 일종의 Ensenble 방법으로, Reasoning path를 제외하고 최종 답안을 얻기 위해 다수결에 투표하도록 한다.
- Example
- Q. 아침에 3개를 먹고, 저녁에 사과 4개를 먹었다. 그럼 최종 몇 개의 사과를 먹은 것일까?
A. 아침에 3개, 저녁에 4개를 먹었으니까, 3+4=7 이다. 정답은 7개이다.
↓ ↓ ↓ ↓ ↓ Sampling ↓ ↓ ↓ ↓ ↓
- Q. 아침에 3개를 먹고, 저녁에 사과 4개를 먹었다. 그럼 최종 몇 개의 사과를 먹은 것일까?
- Sampling
- sample 1
Q. 연필이 5개 있는데, 내일은 3개를 쓰고, 모래는 1개를 쓸것이다. 그럼 최종 몇 개의 연필을 쓸게 될까?
A. 오늘은 5개 가 있고, 내일과 모래 각각 3개와 1개를 쓰니까, 5-(3+1)=1 이다. 정답은 1개이다.
.... - sample
- sample 1
Least-to-Most Prompting
모델이 자기 자신을 활용할 수 있도록 정의하는 형태이다. 이는 주어진 문제를 풀기 위해서 문제를 분해하는 부분과 문제를 해결하는 부분으로 Prompt를 특화시킨다. 그리고 세부 질문들을 생성하여 문제를 풀어나가도록 한다.
- Problem Decomposition
↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ - Subproblem Solving
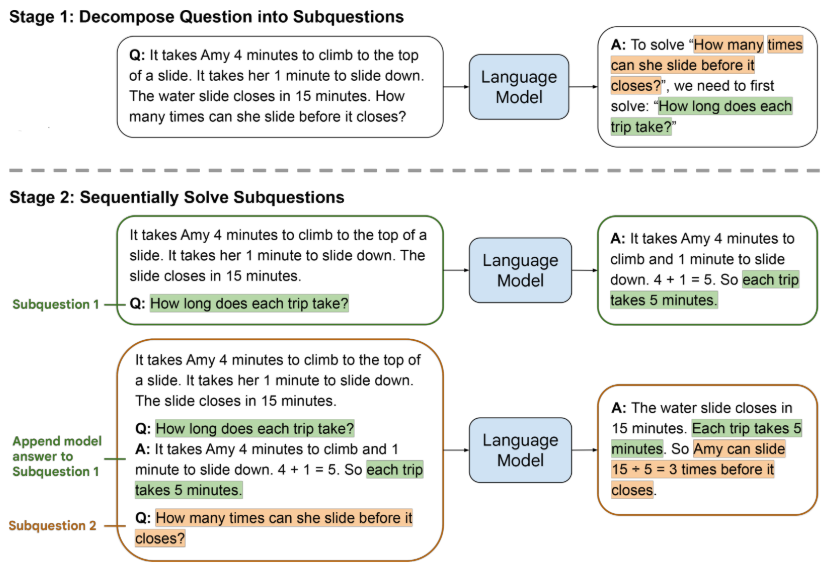
(자료:LEAST-TO-MOST PROMPTING ENABLES COMPLEX REASONING IN LARGE LANGUAGE MODELS, Denny Zhou et al, ICLR 2023, 2023.)
Zero-shot Least-to-Most Prompting
Decomposed Prompting
활용 가능한 작은 문제를 사전에 정의하고, 정의된 기능들과의 상호작용을 활용한다. 즉, 계획 시에 문제를 풀기 위한 Subtask를 만들어 해결하도록 계획한다.
-
Decomposer Prompt
↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ -
Sub-task Prompts
-
특징
- Hierachy (계층적)
- Recursive (재귀적)
-
Least-to-Most보다 정확도와 일반화 성능이 향상된다.
- 예제와 동일한 상황에서는 다른 비교 모델보다 정확도가 높고,
예제보다 어려운 문제에서는 정확도가 유지된다.
- 예제와 동일한 상황에서는 다른 비교 모델보다 정확도가 높고,
ReAct(Reason+Act)
명령어를 선택하고 인수를 생성하기 전에 명시적인 사고 과정을 생성한다. 각 단계마다 CoT를 진행하는 것과 유사하다. 다양하게 변형하여 응용할 수 있다.
단계 마다 추론 계획을 생성하거나 보완할 수 있고, 생선한 생각 등에 자기비판을 생성할 수 있다.
- 아래 내용을 포함하여 Prompt를 작성한다
- Search[entity] : entity는 위키피디아 첫 5개 문장, 페이지가 없다면 유사한 entity 반환
- Lookup[string] : string을 포함한 다음 문장을 반환, Ctrl+F와 유사
- Finish[answer] : answer 반환 및 종료

그림 :
(1) Comparison of 4 prompting methods, (a) Standard, (b) Chain-of-thought (CoT,
Reason Only), (c) Act-only, and (d) ReAct (Reason+Act), solving a HotpotQA (Yang et al., 2018) question.
(2) Comparison of (a) Act-only and (b) ReAct prompting to solve an AlfWorld (Shridhar et al., 2020b) game. In both domains, we omit in-context examples in the prompt, and only show task solving trajectories generated by the model (Act, Thought) and the environment (Obs).
(자료: REACT: SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELS, Shunyu Yao, et al, ICLR 2023, 2023.)
ETC.
Persona
LaaJ(LLM-as-a-Judge)
Prompt Pattern
Reference
[1] 주재걸(KAIST 김재철AI대학원), LLM의 이해 및 응용, 2024 인공지능 춘계 단기강좌, (사)한국인공지능학회, 2024.05.30.~31.
[2] Wayne Xin Zhao, et al, A Survey of Large Language Models, 2023.
