사내에서 진행하는 자바 스터디 2주차 주제입니다.
- 기본형(Primitive type) & 참조형(Reference type)
- 값에 의한 호출(Call by value) & 참조에 의한 호출(Call by reference)
- equals & hashCode
- 오토 박싱 & 언박싱
- checked exception & unchecked exception
기본형(Primitive type) & 참조형(Reference type)
- 기본형 (Privitive type) : 계산을 위해 실제 값을 저장합니다.
- 참조형 (refrence type) : 객체의 주소를 저장합니다. null 또는 객체의 주소를 갖습니다.
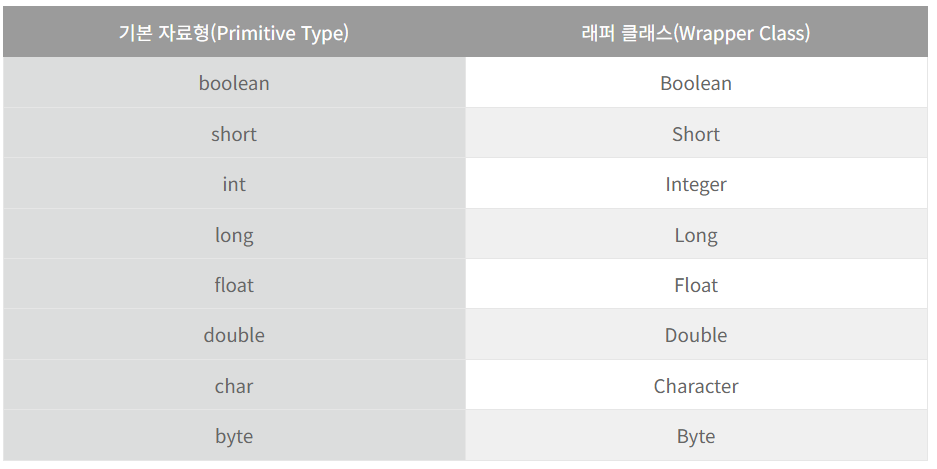
기본형 타입 (Primitive Type)
기본형 타입은 논리형 (boolean), 문자형 (char), 정수형 (byte, short, int, long), 실수형 (float, double) 으로 나뉩니다.
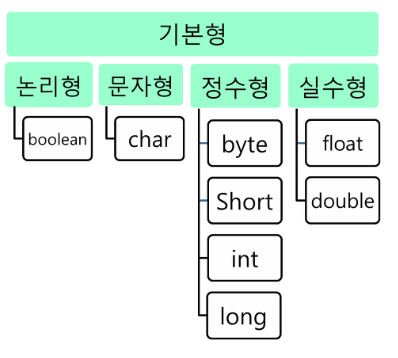
기본형 타입의 특징
- 모두 소문자로 시작된다.
- 비객체 타입이므로 null을 가질 수 없다. (기본 값이 정해져 있음)
- 변수 선언과 동시에 메모리 생성.
- 모든 값 타입은 메모리의 Stack에 저장됨.
- 저장 공간에 실제 자료값을 가진다.
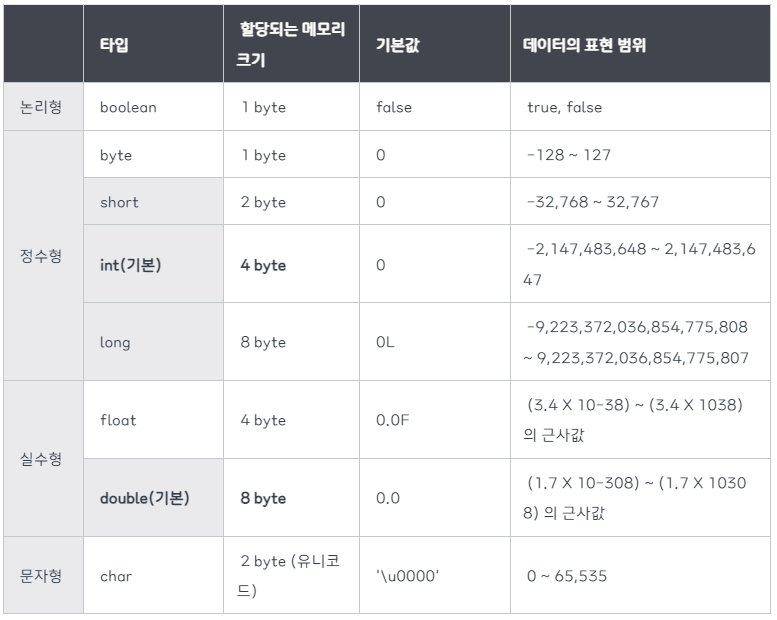
값에 의한 호출(Call by value) & 참조에 의한 호출(Call by reference)
자바는 오직 Call by Value 입니다. Call by value는 메서드를 호출할 때 값을 넘겨줍니다. 메서드를 호출하는 호출자의 변수와 호출 당하는 수신자의 파라미터는 복사된 서로 다른 변수입니다. 값만 전달하기 때문에 파라미터를 수정해도 호출된 변수에는 아무런 영향이 없습니다.
누군가는 이렇게 생각합니다.
참조형 변수를 넘겼을 때 값을 변경했을 때 호출부에서도 변경 되는데?!JVM 메모리에 변수가 저장되는 위치
원시 타입은 Stack 영역에 변수와 함께 저장되고,
참조 타입은 객체는 Heap 영역에 저장되고 Stack 영역에는 변수가 객체의 주소값을 가지고 있습니다.
이제 파라미터로 해당 변수들을 넘겨주는 과정을 보도록 하겠습니다.
@Getter
@RequiredArgsConstructor
public class User {
private final String name;
private final int age;
}객체를 넘길 때 사용할 User 입니다.
public class CallByValue {
public static int printAndChange(int value) {
System.out.println("들어온 값 = " + value);
value += 10;
return value;
}
public static String printAndChange(String value) {
System.out.println("들어온 값 = " + value);
value += " Change";
return value;
}
public static User printAndChange(User user) {
System.out.println("들어온 유저 = " + user);
User newUser = new User("newName", user.getAge() + 10);
user = newUser;
return user;
}
}CallByValue 클래스에는 int, String, User 파라미터를 받아 출력하고 값을 변경한 후 변경한 값을 return 해주는 간단한 클래스 입니다.
public class CallByValueTest {
@Test
void callByTestValue_int() {
int value = 1;
int result = CallByValue.printAndChange(value);
assertThat(value).isEqualTo(1); // true
assertThat(value).isNotEqualTo(result); // true
}
@Test
void callByTestValue_string() {
String value = "값";
String result = CallByValue.printAndChange(value);
assertThat(value).isEqualTo("값"); // true
assertThat(value).isNotEqualTo(result); // true
}
@Test
void callByTestValue_object() {
User user = new User("name", 10);
User newUser = CallByValue.printAndChange(user);
assertThat(user.getName()).isEqualTo("name"); // true
assertThat(user.getAge()).isEqualTo(10); // true
assertThat(user.getName()).isNotEqualTo(newUser.getName()); // true
assertThat(user.getAge()).isNotEqualTo(newUser.getAge()); // true
}
}테스트 코드를 작성해 보았습니다. 마지막 세번째 테스트를 보면 분명 호출된 함수 안에서 새로운 User를 만들어서 변수에 담아주었지만 호출부의 user에는 영향을 주지 못한 것을 볼 수 있습니다. 이것을 이해하려면 매개변수가 어떻게 전달되는지 알아야 합니다.
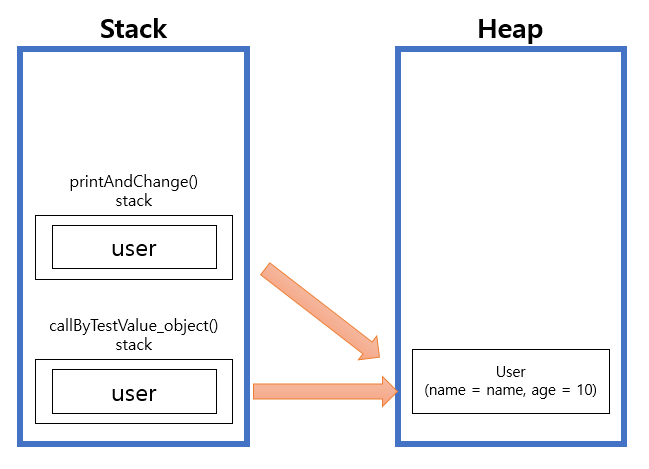
printAndChange 함수에서 user의 값을 변경하기 전의 메모리 상태입니다. 넘겨 받은 파라미터는 Stack 영역에 생성되고 넘겨 받은 주소값을 똑같이 바라봅니다.
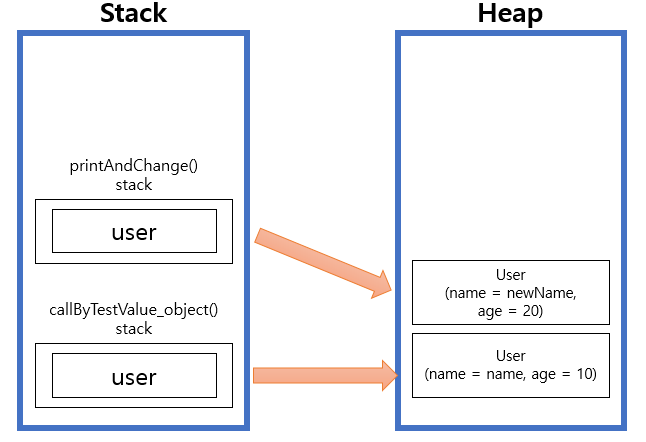
printAndChange 함수에서 새로운 객체를 생성, 할당했기 때문에 새로운 객체를 바라보게 됩니다.
호출부 쪽의 user에는 영향을 주지 않습니다.
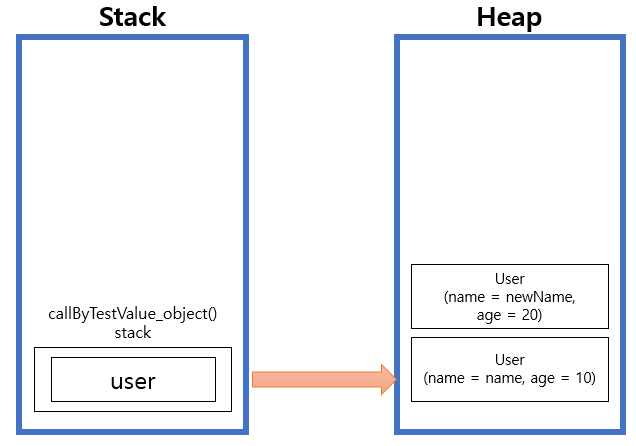
printAndChange 함수가 stack에서 제거된 후에는 heap 영역의 객체는 가비지 콜렉터에 의해서 제거가 됩니다.
자바는 Call by value 라는 것을 증명해 보았습니다.
equals & hashCode
equals와 hashCode는 object의 함수입니다. equals와 hashCode에 알아보기 전에 동등성과 동일성을 알아야 합니다.
동일성
동일성은 동일하다는 뜻으로 두 객체가 완전히 같은 경우를 의미합니다. 같은 객체 즉 같은 메모리의 주소값을 가진다는 뜻입니다.
@Test
void 동일성_테스트() {
String a = "123";
String b = a;
int ih1 = System.identityHashCode(a); // 객체 주소값 1046665075
int ih2 = System.identityHashCode(b); // 객체 주소값 1046665075
assertThat(a == b).isTrue(); // true
assertThat(ih1).isEqualTo(ih2); // true
}동등성
동등성은 동등하다는 뜻으로 두 개의 객체가 같은 정보를 가지고 있는 경우를 의미합니다. 두 객체의 주소값이 달라도 내용이 같으면 동등하다고 할 수 있습니다.
@Test
void 동등성_테스트() {
String a = new String("a");
String b = new String("a");
assertThat(a == b).isFalse(); // 동일성 비교 false
assertThat(a.equals(b)).isTrue(); // 동등성 비교 true
}Object의 equals
/**
* Indicates whether some other object is "equal to" this one.
* <p>
* The {@code equals} method implements an equivalence relation
* on non-null object references:
* <ul>
* <li>It is <i>reflexive</i>: for any non-null reference value
* {@code x}, {@code x.equals(x)} should return
* {@code true}.
* <li>It is <i>symmetric</i>: for any non-null reference values
* {@code x} and {@code y}, {@code x.equals(y)}
* should return {@code true} if and only if
* {@code y.equals(x)} returns {@code true}.
* <li>It is <i>transitive</i>: for any non-null reference values
* {@code x}, {@code y}, and {@code z}, if
* {@code x.equals(y)} returns {@code true} and
* {@code y.equals(z)} returns {@code true}, then
* {@code x.equals(z)} should return {@code true}.
* <li>It is <i>consistent</i>: for any non-null reference values
* {@code x} and {@code y}, multiple invocations of
* {@code x.equals(y)} consistently return {@code true}
* or consistently return {@code false}, provided no
* information used in {@code equals} comparisons on the
* objects is modified.
* <li>For any non-null reference value {@code x},
* {@code x.equals(null)} should return {@code false}.
* </ul>
*
* <p>
* An equivalence relation partitions the elements it operates on
* into <i>equivalence classes</i>; all the members of an
* equivalence class are equal to each other. Members of an
* equivalence class are substitutable for each other, at least
* for some purposes.
*
* @implSpec
* The {@code equals} method for class {@code Object} implements
* the most discriminating possible equivalence relation on objects;
* that is, for any non-null reference values {@code x} and
* {@code y}, this method returns {@code true} if and only
* if {@code x} and {@code y} refer to the same object
* ({@code x == y} has the value {@code true}).
*
* In other words, under the reference equality equivalence
* relation, each equivalence class only has a single element.
*
* @apiNote
* It is generally necessary to override the {@link hashCode hashCode}
* method whenever this method is overridden, so as to maintain the
* general contract for the {@code hashCode} method, which states
* that equal objects must have equal hash codes.
*
* @param obj the reference object with which to compare.
* @return {@code true} if this object is the same as the obj
* argument; {@code false} otherwise.
* @see #hashCode()
* @see java.util.HashMap
*/
public boolean equals(Object obj) {
return (this == obj);
}실제 Object 클래스의 equals 메서드입니다. 메서드 위의 주석을 정리하자면 아래와 같습니다.
- 다른 개체가 이 개체와 "동일"한지 여부를 나타냅니다.
- null이 아닌 개체 참조에 대해 동등성 관계를 구현합니다.
- equals 메서드를 오버라이딩하면 hashCode 메서드도 오버라이딩 해야 합니다.
String 클래스에서는 equals 메서드, hashCode 메서드를 오버라이딩하고 있습니다.
static final boolean COMPACT_STRINGS;
static {
COMPACT_STRINGS = true;
}
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
return (anObject instanceof String aString)
&& (!COMPACT_STRINGS || this.coder == aString.coder)
&& StringLatin1.equals(value, aString.value);
}- 만약에 동일한 객체라면 true를 반환합니다.
- anObject가 String클래스의 인스턴스인지 확인합니다.
- COMPACT_STRINGS (문자열 저장 및 처리 방식에 대한 최적화 플래그), coder(문자열 인코딩 방식) 을 확인합니다.
- StringLatin1.equals() 객체 value 비교 (문자열의 값을 비교)
/** Cache the hash code for the string */
private int hash; // Default to 0
private boolean hashIsZero; // Default to false;
public int hashCode() {
int h = hash;
if (h == 0 && !hashIsZero) {
h = isLatin1() ? StringLatin1.hashCode(value)
: StringUTF16.hashCode(value);
if (h == 0) {
hashIsZero = true;
} else {
hash = h;
}
}
return h;
}- hash 변수는 문자열의 해시코드를 저장하기 위한 변수입니다.
- hashIsZero는 hash 값이 0인지 여부를 나타냅니다.
- isLatin1() 메서드를 사용하여 현재 문자열이 Latin-1 문자열 형식인지 UTF-16 형식인지 확인합니다.
- Latin-1 형식이라면 StringLatin1.hashCode(value) 를 호출합니다, UTF-16 형식이라면 StringUTF16.hashCode(value)를 호출합니다.
- 반환된 값을 변수 h에 할당합니다.
- 변수 h의 값이 0이면 hashIsZero를 true로 설정하여 나중에 동일한 문자열에 대한 해시 코드를 다시 계산하지 않도록 합니다.
- 그렇지 않으면 hash 변수에 h 값을 할당합니다.
- 변수 h를 반환합니다.
hashCode 메서드는 문자열의 해시 코드를 계산하고 해시 코드를 hash 변수에 캐시하여 동일한 문자열에 대한 해시 코드를 여러번 계산하는 것을 피합니다.
엄밀히 말하면 해시코드는 주소값이 아니고 주소값으로 만든 고유한 숫자값입니다.hashCode가 존재하는 이유?
equals 메서드만 있어도 모든 객체를 비교할 수 있는데, 왜 hashCode 메서드가 있을까요?
객체를 비교할 때 드는 비용을 낮추기 위함이다.HashCode를 사용하는 HashSet, HashMap, HashTable 등등에서 Key값을 통해 value 값을 꺼내는 기능, 동일한 객체는 중복해서 추가할 수 없게끔 하는 기능, 객체를 매핑해서 동일한 객체를 찾는 기능 등의 경우에서 서로의 객체가 다른지 비교를 해나가야 합니다.
- equals 메소드로 일일히 객체를 비교하게 되면 모든 객체들을 하나하나 해당 객체의 인스턴스 변수의 값들로 비교하게 됩니다.
- hashCode 메서드보다 더 많은 비용, 시간이 들어가게 됩니다.
- 즉, Hash는 자료구조의 좋은 성능을 위해 존재합니다.
Hash 자료구조에서 equals()와 hashCode()의 동작원리
- hashCode가 같은지 비교
- hashCode가 같다면 equals가 같은지 비교
둘 다 같아야 true를 반환합니다. hashCode가 같아도 equals 결과가 다를 수 있습니다. 하지만 hashCode가 다르면 equals는 호출조차 하지 않기 때문에 성능을 향상 시킬 수 있습니다.
예시
HashSet에 객체를 담아보도록 하겠습니다.
@RequiredArgsConstructor
public class User {
private final Long id;
private final String name;
private final int age;
}아직 equals 메서드와 hashCode 메서드를 오버라이딩 하지 않았습니다.
@Test
void HashSet에_User_데이터_추가하기_equals_hashCode_오버라이딩하지_않음() {
User user1 = new User(1L, "jay", 12);
User user2 = new User(2L, "min", 13);
User user3 = new User(1L, "jay", 12);
HashSet<User> userHashSet = new HashSet<>();
userHashSet.add(user1);
userHashSet.add(user2);
userHashSet.add(user3);
assertThat(userHashSet).hasSize(3); // true
}user1과 user3은 중복된 데이터이지만 다른 객체로 판단되어 hashSet의 size는 3으로 출력되는 것을 확인할 수 있습니다.
@RequiredArgsConstructor
public class User {
private final Long id;
private final String name;
private final int age;
@Override
public boolean equals(Object o) {
System.out.println("equals 호출");
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
User user = (User) o;
if (age != user.age) return false;
if (id != null ? !id.equals(user.id) : user.id != null) return false;
return name != null ? name.equals(user.name) : user.name == null;
}
}equals만 재정의 후 테스트 해보았습니다. equals 메서드 안에는 호출되었는지 확인할 수 있게 print를 남겨보았습니다.
@Test
void HashSet에_User_데이터_추가하기_equals_hashCode_오버라이딩하지_않음() {
User user1 = new User(1L, "jay", 12);
User user2 = new User(2L, "min", 13);
User user3 = new User(1L, "jay", 12);
HashSet<User> userHashSet = new HashSet<>();
userHashSet.add(user1);
userHashSet.add(user2);
userHashSet.add(user3);
assertThat(userHashSet).hasSize(3); // true
}여전히 사이즈는 3으로 다른 객체로 판단되어 그대로 값이 들어가집니다.
hashCode를 호출할 때 값이 다르기 때문에 결과적으로 equals는 호출되지 않았을 것입니다.
equals를 호출하지 않은 것을 확인할 수 있습니다.
@RequiredArgsConstructor
public class User {
private final Long id;
private final String name;
private final int age;
@Override
public boolean equals(Object o) {
System.out.println("equals 호출");
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
User user = (User) o;
if (age != user.age) return false;
if (id != null ? !id.equals(user.id) : user.id != null) return false;
return name != null ? name.equals(user.name) : user.name == null;
}
@Override
public int hashCode() {
System.out.println("hashCode 호출");
int result = id != null ? id.hashCode() : 0;
result = 31 * result + (name != null ? name.hashCode() : 0);
result = 31 * result + age;
return result;
}
}이제 hashCode 또한 재정의 하여 테스트 해보도록 하겠습니다.
@Test
void HashSet에_User_데이터_추가하기_equals_hashCode_오버라이딩하지_않음() {
User user1 = new User(1L, "jay", 12);
User user2 = new User(2L, "min", 13);
User user3 = new User(1L, "jay", 12);
HashSet<User> userHashSet = new HashSet<>();
userHashSet.add(user1);
userHashSet.add(user2);
userHashSet.add(user3);
assertThat(userHashSet).hasSize(2); // true
}size가 2로 예상한대로 user1과 user3을 같은 객체로 판단하고 HashSet에 추가가 되지 않았습니다.
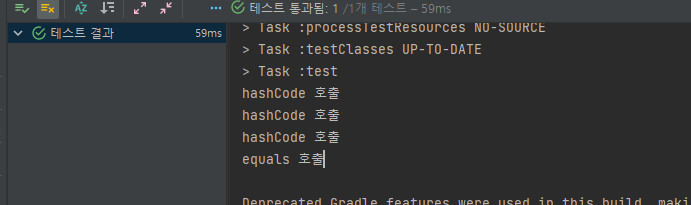
consle 창에도 user3을 넣을 때 equals가 호출된 것을 확인할 수 있습니다.
왜 처음에 값을 넣을 때 hashCode가 호출될까?
- HashSet은 요소들을 해시 테이블이라는 자료 구조에 저장합니다. 해시 테이블은 해시 코드를 기반으로 각 요소를 저장하고 검색하는데 사용됩니다.
- 객체를 HashSet에 추가할 때, 먼저 해당 객체의 hashCode 메서드를 호출하여 객체의 해시코드를 얻습니다.
- 얻은 해시코드를 사용하여 해당 객체를 해시 테이블의 적절한 위치에 저장합니다.
- 나중에 같은 객체 또는 동일한 해시 코드를 가진 객체를 HashSet에서 검색하려고 할 때, 해당 객체의 hashCode 메서드를 호출하여 저장된 위치를 찾고, 이를 통해 검색을 빠르게 수행할 수 있습니다.
해시코드 메서드를 이해해보자
@Override
public int hashCode() {
int result = id != null ? id.hashCode() : 0;
result = 31 * result + (name != null ? name.hashCode() : 0);
result = 31 * result + age;
return result;
}인텔리제이가 default하게 만들어준 hashCode 메서드입니다. 각 필드들의 hashCode값을 얻어서 계산을 합니다. 여기서 왜 31을 곱할까요?
- 31은 소수이며, 소수는 해시코드 계산에서 무작위성을 더해줄 수 있습니다. 더해진 소수가 비교적 큰 값이기 때문에 결과적으로 다양한 속성 조합에 대한 고유한 해시코드를 얻을 수 있습니다.
- 31은 2^5-1로 표현할 수 있는데, 컴파일러에서 2의 거듭제곱을 곱셈연산으로 처리할 때 최적화를 할 수 있어서 성능을 향상시킬 수 있습니다. 즉 31 * result 연산은 컴퓨터에서 효율적으로 수행될 수 있습니다.
이러한 이유로 31은 자주 사용되는 해시코드 계산에서의 상수값으로 선택되고 있으며, 객체의 속성을 고유하게 조합하여 해시코드를 생성하는데 효과적입니다.
오토 박싱 & 언박싱
오토박싱(Autoboxing)과 언박식(Unboxing)은 java 1.5 Version에 도입된 기능으로, 원시타입에서 래퍼 클래스 타임으로 또는 반대로 자동 변환하는 것을 말합니다.
@Test
void 박싱() {
int a = 1;
Integer i = new Integer(a);
assertThat(i).isEqualTo(1);
}JDK17 버전에서는 해당 코드는 아래 에러를 나타냅니다.
warning: [removal] Integer(int) in Integer has been deprecated and marked for removal
Integer i = new Integer(a);@Test
void 박싱() {
int a = 1;
Integer i = a;
assertThat(i).isEqualTo(1); // true
}이렇게 코드를 변경하면 오토 박싱이 일어나서 변수 i에 담기게 됩니다. 여기서 궁금한 부분이 생겼습니다.
assertThat(i).isEqualTo(1); // true이 코드에서 변수 i는 1과 비교하기 위해 오토 언박싱이 일어날까요? 아닙니다. 이 메서드는 내부적으로 equals 메서드를 사용하여 i와 1을 비교합니다. Integer 클래스에는 equals가 오버라이딩 되어있기 때문에 i의 값과, 1이 같은지를 비교하고 같으면 true를 반환합니다. 결론은 오토 언박싱이 일어나지 않습니다.
int b = i;해당 코드가 추가된다면 오토 언박싱이 일어나게 됩니다.
성능
편의성을 위해서 자바에서는 오토 박싱과 언박싱을 제공하고 있습니다. 내부적으로 추가 연산 작업이 이루어지기 때문에 성능에 영향을 줍니다.
@Test
void 오토박싱_성능_테스트() {
long t = System.currentTimeMillis();
Long sumL = 0L;
for (int i = 0; i < 1000000; i++) {
sumL += i;
}
long autoBoxingTime = System.currentTimeMillis() - t;
t = System.currentTimeMillis();
long sum = 0L;
for (int i = 0; i < 1000000; i++) {
sum += i;
}
long notAutoBoxingTime = System.currentTimeMillis() - t;
System.out.println("AutoBoxingTime =" + autoBoxingTime + "ms");
System.out.println("notAutoBoxingTime =" + notAutoBoxingTime + "ms");
assertThat(autoBoxingTime - notAutoBoxingTime).isPositive(); // true
}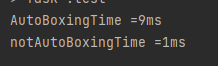
100만건 기준으로 약 9배의 성능 차이가 나고 있습니다. 서비스 개발 시에 이 부분을 주의하여 개발하여야 합니다.
wrapper 클래스를 사용하는 이유
기본 자료형의 값을 단순히 값으로 사용하지 않고, 그 값에 대한 메서드, null 값을 사용하기 위해 사용합니다.
JPA에서 Entity 설계 시 ID 값을 Long으로 지정하는 이유
long으로 사용 시 primitive type 이므로 값이 없을 경우 0으로 초기화 됩니다. 따라서 id가 없어서 0으로 세팅된 것인지, 실제 값이 0인 것인지 판별이 될 수 없습니다. Long은 wapper type으로 값이 없을 경우 null로 초기화 됩니다. 따라서 값이 0이라면 id가 0으로 저장된 것을 확인할 수 있습니다.
checked exception & unchecked exception
제 블로그 게시글에 작성되어 있습니다.
https://velog.io/@jay_be/JAVA-%EC%98%88%EC%99%B8
일부 발췌, 참조 블로그
https://bcp0109.tistory.com/360
https://steady-coding.tistory.com/534
https://tjdtls690.github.io/studycontents/java/2022-07-27-equals_hashcode/
https://developer-talk.tistory.com/504
