사내에서 진행하는 자바 스터디 3주차 주제입니다.
- 쓰레드
- 리플렉션
- 직렬화, 역직렬화
- Java 동기 vs 비동기
- 클래스, 객체, 인스턴스
쓰레드
프로그램 & 프로세스 & 쓰레드
 https://www.youtube.com/watch?app=desktop&v=4rLW7zg21gI
https://www.youtube.com/watch?app=desktop&v=4rLW7zg21gI
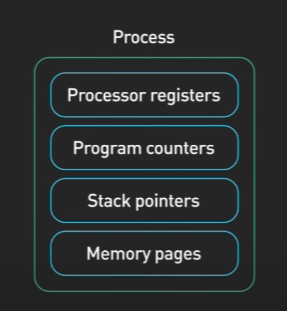
프로그램은 실행 파일입니다. 여기에는 디스크에 파일로 저장되는 코드 또는 프로세서 명령 세트가 포함되어 있습니다. 프로그램의 코드가 메모리에 로드되고 프로세서에 의해 실행되면 프로세스가 됩니다. 활성 프로세스(실행중인 프로그램)에는 프로그램을 실행하는데 필요한 리소스도 포함됩니다.

이러한 리소스들은 운영체제에 의해 관리됩니다. 예를 들어 프로세서 레지스터, 프로그램 카운터, 스택 포인터, 힙 및 스택용 프로세스에 할당된 메모리 페이지 등이 있습니다.
각 프로세스에는 자체 메모리 주소 공간이 있습니다. 한 프로세스는 다른 프로세스의 메모리 공간을 손상시킬 수 없습니다. 즉 한 프로세스가 오작동 해도, 다른 프로세스는 문제없이 계속 실행됩니다.
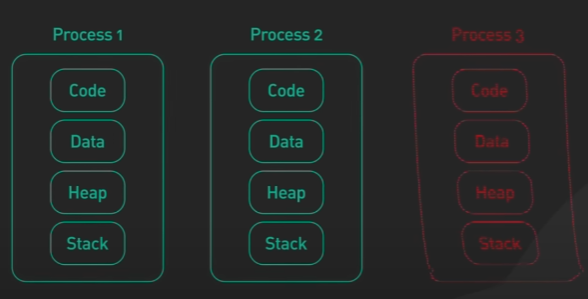
Chrome은 프로세스의 대표적인 예시입니다. 각 탭을 자체 프로세스에서 실행하며 프로세스의 격리를 활용하는 것으로 유명합니다. 버그나 악의적인 공격으로 인해 탭 하나가 오작동하더라도 다른 탭은 영향을 받지 않습니다.

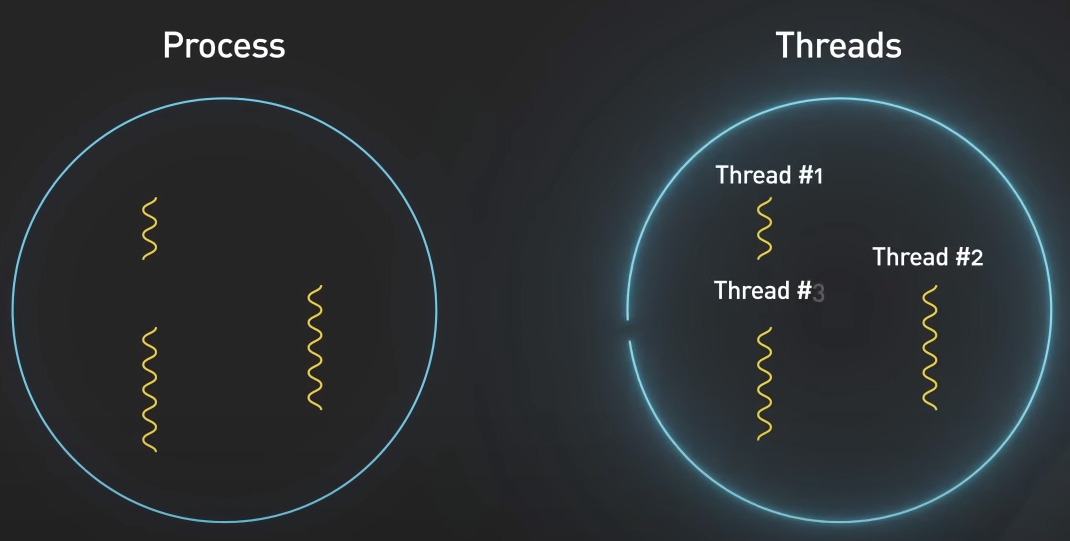
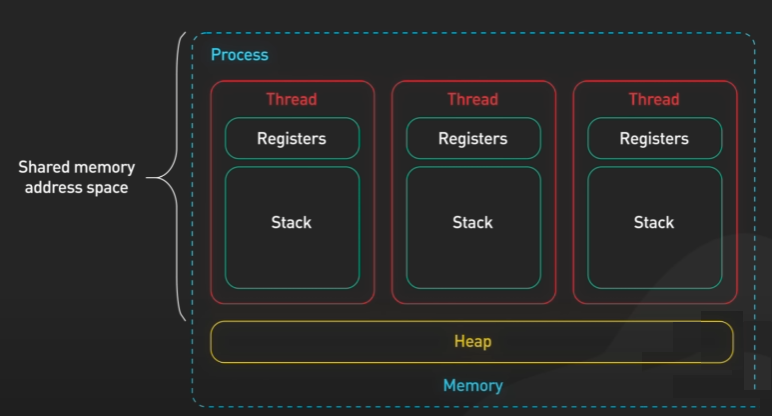
스레드는 프로세스 내 실행 단위입니다. 프로세스에는 하나 이상의 스레드가 있습니다. 이를 메인 스레드라고 합니다. 프로세스에는 스레드가 많이 존재할 수 있습니다.
각 스레드에는 자체 스택이 있습니다. 앞에서 레지스터, 프로그램 카운터, 스택 포인터가 프로세스의 일부라고 하였지만, 이것은 스레드에 속한다고 말하는 것이 더 정확합니다.
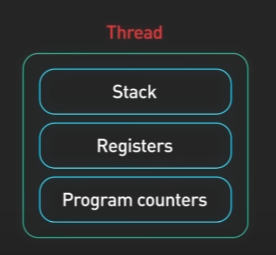
프로세스 내의 스레드는 메모리 주소 공간을 공유합니다. 해당 공유 메모리 공간을 사용하여 스레드 간에 통신이 가능합니다. 공유된 공간을 사용하기 때문에 하나의 잘못된 스레드로 인해 전체 프로세스가 중단될 수도 있습니다.
운영체제는 CPU에서 스레드나 프로세스를 어떻게 실행할까?
컨텍스트 전환을 통해 처리됩니다. 컨텍스트 전환 후에 한 프로세스가 CPU에서 전환되며 다른 프로세스가 실행될 수 있습니다. 운영체제는 현재 실행중인 프로세스의 상태를 저장하므로 프로세스를 복원하고 나중에 실행을 재개할 수 있습니다. 그런 다음 이전에 저장된 다른 프로세스의 상태를 복원하고, 해당 프로세스의 실행을 재개합니다.
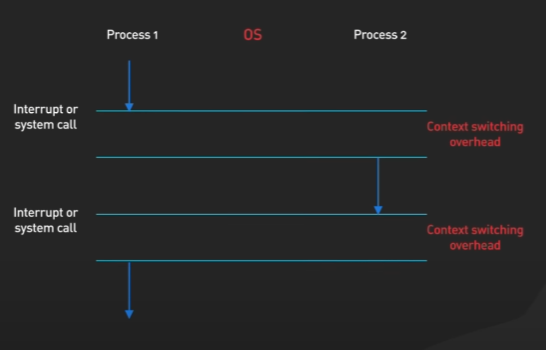
컨텍스트 전환은 많은 비용이 듭니다. 여기에는 레지스터 저장, 로드, 메모리 페이지 전환, 다양한 커널 데이터 구조 업데이트가 포함됩니다. 스레드 간 실행을 전환할 떄에도 컨텍스트 전환이 필요합니다.
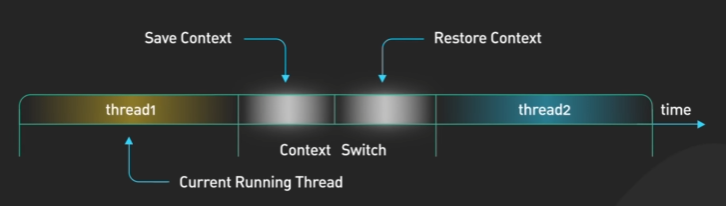
일반적으로 프로세스 간 컨텍스트 전환보다 스레드 간에 컨텍스트 전환하는 것이 더 빠릅니다. 추적해야하는 상태가 적고, 더 중요한 것은 스레드가 동일한 메모리 주소 공간을 공유하기 때문에 컨텍스트 전환 중 가장 비용이 많이 드는 작업 중 하나인 가상 메모리 페이지 전환할 필요가 없다는 것입니다. 컨텍스트 전환은 비용이 많이 들기 때문에 이를 최소화 하기 위한 다른 메커니즘이 있습니다. 이 부분에 관심이 있으신 분들은 더 찾아보시면 될 것 같습니다.
용어 정리
프로세서
중앙처리장치(CPU)라고도 하는 프로세서는 기본적인 산술, 논리, 제어, 입출력(I/O) 연산을 수행하여 컴퓨터 프로그램의 명령을 수행하는 컴퓨터 핵심 구성요소입니다. 흔히 컴퓨터의 두뇌로 간주됩니다.
프로세서 레지스터
프로세서 레지스터는 프로그램 실행 중에 데이터를 일시적으로 저장하는 CPU내의 작고 빠른 저장 위치입니다. CPU 작업에 대한 중간 결과와 피연산자를 저장하는데 사용됩니다. 레지스터는 데이터에 대한 빠른 액세스를 제공하여 계산 속도를 향상시키는데 도움이 됩니다.
프로그램 카운터
프로그램 카운터는 다음에 실행될 명령어의 메모리 주소를 추적하는 CPU의 레지스터입니다. 프로그램 실행 중에 PC는 순차적으로 다음 명령어를 가르키도록 증가됩니다.
스택 포인터
스택 포인터는 컴퓨터 메모리의 스택 상단을 가르키는 레지스터입니다. 스택은 함수 호출 정보, 지역 변수, 반환 주소 등 임시 데이터를 저장하는데 사용되는 메모리 영역입니다. 스택 포인터는 데이터가 스택에 푸시되거나 스택에서 팝될 때 조정됩니다.
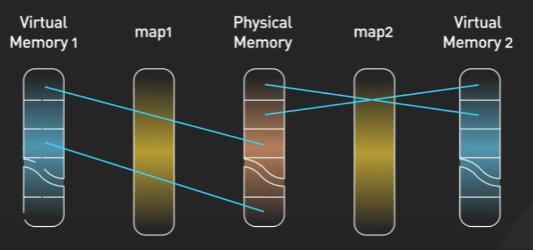
가상 메모리
크기가 다른 물리 메모리에서도 일관되게 프로세스를 실행할 수 있도록 도와주는 것이 가상 메모리 기술입니다. 물리 메모리 크기와 상관없이 메모리를 이용할 수 있도록 지원해주는 기술입니다.
3GB인 프로세스를 2GB의 메모리에도 실행 가능하게 하는 기술입니다.
프로세스
프로세스는 CPU에 의해 메모리에 올려져 실행중인 프로그램을 말하며, 자신만의 메모리 공간을 포함한 독립적인 실행 환경을 가지고 있습니다. 자바 JVM은 주로 하나의 프로세스로 실행되며, 여러 작업을 수행하기 위해서 멀티 스레드를 지원하고 있습니다.
스레드
스레드는 프로세스 안에서 실질적인 작업을 수행하는 단위를 말하며, 자바에서 JVM에 의해 관리됩니다. 프로세스는 적어도 한개 이상의 스레드가 있으며, Main 스레드 하나로 시작하여 스레드를 추가 생성하게 되면 멀티 스레드 환경이 됩니다. 이러한 스레드들은 프로세스의 리소스를 공유하기 때문에 효율적이긴 하지만 잠재적인 문제점에 노출될 수 있습니다.
자바 프로세스 vs 자바 쓰레드
자바 프로세스
자바에서 프로세스란 실행중인 프로그램입니다. JVM은 OS로 부터 실행에 필요한 자원(메모리)를 할당 받아 프로세스를 실행시킵니다. 프로세스는 프로그램을 수행하는데 필요한 데이터, 메모리 등의 자원 그리고 스레드로 구성되어 있으며 프로세스의 자원을 이용하여 실제로 작업을 수행하는 것이 스레드입니다.
자바 스레드
자바는 다중 스레드 프로그래밍 언어입니다. 단인 프로그램 내에서 여러 스레드의 동시 실행을 지원합니다. 이 기능을 통해 개발자는 여러 작업을 동시에 수행하여 성능과 응답성을 향상 시킬 수 있는 프로그램을 작성할 수 있습니다.
스레드 생성
- Thread 클래스 상속
- Runnable 인터페이스 구현
자바는 다중 상속을 허용하지 않기 때문에 Thread 클래스를 상속 받게 되면 다른 클래스를 상속 받을 수 없기 떄문에 Runnable 인터페이스를 구현하는 것을 보통으로 합니다.
스레드를 생성하고 동작시킴에 있어서 알아두어야 할 점은 사용자가 스레드 객체를 생성하고 실행 요청을 하더라도 스레드가 실행되는 것은 전적으로 JVM에 의한 스케줄러를 따른다는 것입니다.
public class MyThread implements Runnable{
@Override
public void run() {
System.out.println("myThread start");
System.out.println(Thread.currentThread().getName());
System.out.println("myThread finish");
}
}Runnable 인터페이스를 구현한 클래스입니다.
public class ThreadTest {
public static void main(String[] args) {
System.out.println("main start");
System.out.println(Thread.currentThread().getName());
Runnable runnable = new MyThread();
Thread thread = new Thread(runnable);
thread.start();
System.out.println("main finish");
}
}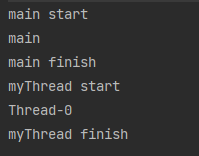
결과적으로 main 함수와 run 함수는 다른 스레드를 사용하는 것을 알 수 있습니다. 실무에서 이렇게 스레드를 생성하여 코드를 작성하는 일은 드물었을 것이라고 생각이 듭니다.
최근에 인프런 강의 "실습으로 배우는 선착순 이벤트 시스템" 를 학습하면서 테스트 코드에 멀티스레드를 활용하여 1000명이 멀티스레드를 사용하여 쿠폰 발급을 요청한다는 가정으로 코드를 작성해보았습니다.
@Test
void 여러명_응모() throws InterruptedException {
int threadCount = 1000; // thread 수
ExecutorService executorService = Executors.newFixedThreadPool(32); // thread pool 32개 생성
CountDownLatch latch = new CountDownLatch(threadCount); // 모든 작업자 스레드와 메인스레드를 동기화 하는 대 사용
for (int i = 0; i < threadCount; i++) {
long userId = i;
executorService.submit(() -> {
try {
applyService.apply(userId); // 쿠폰 발급 로직
} finally {
latch.countDown();
}
});
}
latch.await(); // 래치 수가 0이 될 때까지 차단
long count = couponRepository.count();
assertThat(count).isEqualTo(100);
}간단하게 코드 설명을 해보자면 32개의 스레드 풀을 생성하고 생성된 스레드로 1000개의 쿠폰 생성 요청을 합니다. CountDownLatch를 사용하여 작업 스레드들이 작업을 완료할 때까지 기다리게 하여 메인 스레드와 작업자 스레드를 동기화 한 후 결과를 테스트하는 코드입니다.
멀티 스레드를 개발자가 직접 컨트롤 하는 것은 굉장히 어렵습니다. 현재 이 코드에도 많은 문제가 발생할 수 있기 때문에 동시성에 대한 것은 웹 개발자로서 깊게 공부해야하는 분야라고 생각이 듭니다.
추가 키워드
- 레이스 컨디션
- 레디스
- 카프카
- DB Lock
리플렉션
리플렉션이란 ?
런타임에 클래스와 인터페이스 등을 검사하고 조작할 수 있는 기능입니다.
런타임 시점에 어떻게 클래스와 인터페이스를 검사하고 조작할 수 있을까요?
이것을 알기 위해서는 JVM 동작 방식을 이해해야 합니다.
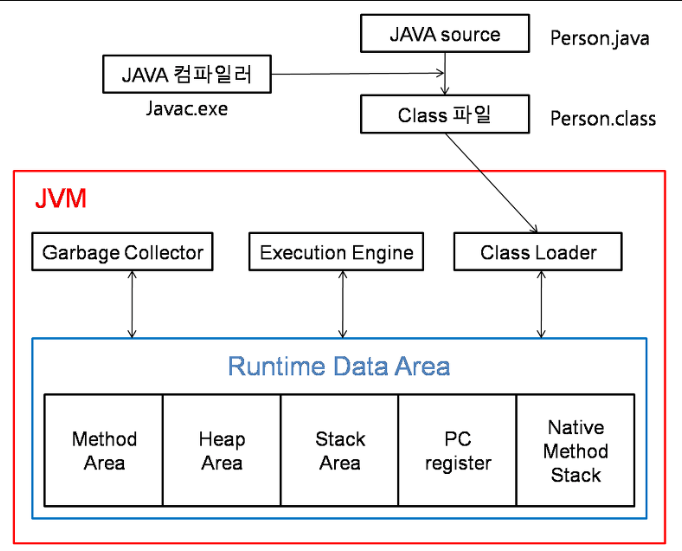
JVM의 클래스 로더는 Runtime Data Area에 올려주게 됩니다. 그중 Method Area에 클래스 수준의 메타 정보를 올려주게 됩니다. 리플렉션은 그 Method Area에 접근합니다.
Class 클래스
클래스는 메서드 영역의 클래스 및 인터페이스 정보를 가져오는 클래스입니다.
public class Main {
public static void main(String[] args) throws ClassNotFoundException {
final Class<Main> class1 = Main.class;
final Main mainObj = new Main();
Class<? extends Main> class2 = mainObj.getClass();
final Class<?> class3 = Class.forName("클래스 풀 패키지 경로");
}
}리플렉션으로 가져올 수 있는 정보
- 필드
- 메서드
- 생성자
- Enum
- Annotation
- 배열
- 부모 클래스와 인터페이스
등이 있습니다.
사용 예시
- DI
- Proxy
- ModelMapper
- MVC : view에서 넘어오는 데이터를 객체에 바인딩 할 때 사용
- Hibernate : @Entitiy 클래스에 setter가 없으면 해당 필드에 값을 바로 주입
- JUnit ReflectionUtils라는 클래스를 내부적으로 정의하여 사용
- Eclipse : 메소드 자동완성
- Tomcat : web.xml 파일에 있는 클래스 이름을 가지고 웹의 요청을 처리할 서블릿
리플렉션을 언제 사용해야 할까?
런타임에 지금 실행되고 있는 클래스를 가져와서 실행해야 하는 경우에 사용을 합니다.
리플렉션 단점
- 보안 취약점
- 코드 복잡도 증가
- 성능 저하
- 최적화 방해
- 타입 안정성 X
- 호환성
왜 사용할까?
자바는 정적인 언어라 동적인 문제를 해결하기 위해 리플렉션을 사용합니다. 일반적인 사용 사례 중 하나는 런타임까지 클래스 구조를 알 수 없는 프레임워크, 라이브러리 또는 시나리오를 처리할 때 사용됩니다.
사실 리플렉션은 일반 개발자들은 되도록이면 사용을 지양해야 합니다. 하지만 필요한 경우에 적절하게 사용하는 것은 강력한 도구가 될 수 있습니다.
프레임워크 및 라이브러리 제공자들은 런타임에 사용자와 상호작용하면서 기능을 제공하고 싶은 경우에 한정적으로 사용합니다.
직렬화, 역직렬화
자바 직렬화란?
- 자바 직렬화란 자바 시스템 내부에서 사용되는 객체 또는 데이터를 외부의 자바 시스템에도 사용할 수 있도록 바이트(byte) 형태로 데이터를 변환하는 기술과 바이트로 변환된 데이터를 다시 객체로 변환하는 기술(역직렬화)를 말합니다.
- 시스템적으로 설명하자면 JVM의 메모리의 상주되어 있는 객체 데이터를 바이트 형태로 변환하는 기술과 직렬화된 바이트 형태의 데이터를 객체로 변환하여 JVM으로 상주시키는 형태를 말합니다.
자바 직렬화 조건
자바 기본타입과 java.io.Serializable 인터페이스를 상속 받은 객체는 직렬화를 할 수 있습니다.
public class User implements Serializable {
private final String name;
private final int age;
public User(final String name, final int age) {
this.name = name;
this.age = age;
}
}직렬화 방법
자바 직렬화 방법은 java.io.ObjectOutputStream 객체를 사용합니다.
public class SerializeTest {
public static void main(String[] args) throws IOException {
User user = new User("jjj", 10);
byte[] serializeUser;
ByteArrayOutputStream baos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(baos);
oos.writeObject(user);
serializeUser = baos.toByteArray();
System.out.println(Arrays.toString(serializeUser));
// [-84, -19, 0, 5, 115, 114, 0, 14, 115, 101, 114, 105, 97,
// 108, 105, 122, 101, 46, 85, 115, 101, 114, -33, 8, 17, 81, -124, 110,
// -92, -7, 2, 0, 2, 73, 0, 3, 97, 103, 101, 76, 0, 4, 110, 97, 109, 101,
// 116, 0, 18, 76, 106, 97, 118, 97, 47, 108, 97, 110, 103, 47, 83, 116, 114, 105,
// 110, 103, 59, 120, 112, 0, 0, 0, 10, 116, 0, 3, 106, 106, 106]
oos.close();
baos.close();
}
}만약 User 클래스에 참조형 필드가 추가된다면 해당 클래스 또한 Serializable를 구현해야 에러가 발생하지 않습니다.
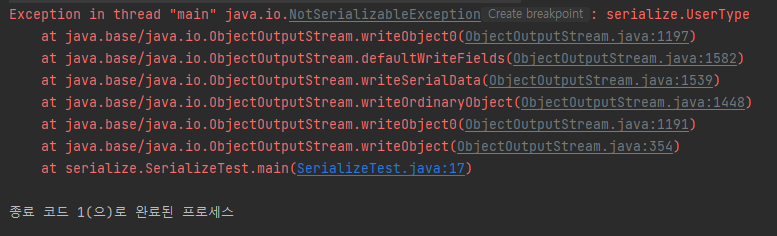
역직렬화 조건
- 직렬화 대상이 된 객체의 클래스가 class path에 존재해야하고 import 되어야 합니다.
- 자바 직렬화 대상 객체는 동일한 serialVersionUID를 가지고 있어야 합니다.
public class TableName implements Serializable {
/**
* This field was generated by Apache iBATIS ibator. This field corresponds to the database column
* @ibatorgenerated Mon Nov 20 12:31:29 KST 2023
*/
private String name;
/**
* This field was generated by Apache iBATIS ibator. This field corresponds to the database column
* @ibatorgenerated Mon Nov 20 12:31:29 KST 2023
*/
private String org;
/**
* This field was generated by Apache iBATIS ibator. This field corresponds to the database table
* @ibatorgenerated Mon Nov 20 12:31:29 KST 2023
*/
private static final long serialVersionUID = 1L;
// getter setter 생략
} 현재 실무에서 사용중인 Apache iBATIS ibator의 결과 모델을 가져와봤습니다.
/**
* This field was generated by Apache iBATIS ibator. This field corresponds to the database table
* @ibatorgenerated Mon Nov 20 12:31:29 KST 2023
*/
private static final long serialVersionUID = 1L;Apache iBATIS ibator는 serialVersionUID를 1L 고정값을 사용하고 있습니다. 그 이유는 serialVersionUID를 따로 설정해주지 않으면 클래스의 기본 해쉬값을 사용하기 때문에 값이 변경됩니다.
자바 직렬화는 상당히 타입의 변화에 엄격하기 때문에 필드의 변경이 일어나면 serialVersionUID는 변경되므로 타입 에러가 발생할 수 있습니다.
- 특별한 문제가 없으면 자바 직렬화 버전 serialVersionUID는 개발자가 직접 관리해야 합니다.
- serialVersionUID가 동일하다면 멤버 변수 및 메서드 추가는 크게 문제가 없습니다. 멤버 변수 제거 및 이름 변경은 오류가 발생하지 않지만 데이터는 누락됩니다.
역직렬화 예제
public class SerializeTest {
public static void main(String[] args) throws IOException, ClassNotFoundException {
User user = new User("jjj", 10);
byte[] serializeUser = serialize(user);
ByteArrayInputStream bais = new ByteArrayInputStream(serializeUser);
ObjectInputStream ois = new ObjectInputStream(bais);
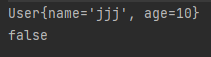
User newUser = (User) ois.readObject();
System.out.println(newUser.toString());
System.out.println(user == newUser);
ois.close();
bais.close();
}
private static byte[] serialize(User user) throws IOException{
ByteArrayOutputStream baos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(baos);
oos.writeObject(user);
return baos.toByteArray();
}
}
왜 자바 직렬화가 있을까?
직렬화에는 많은 종류가 있습니다.
문자열 직렬화
- CSV
- JSON
- XML 등
이진 직렬화
- Protocol Buffer
- Apache Avro 등
위의 직렬화들은 시스템의 고유 특성과 상관 없는 대부분의 시스템에서 데이터 교환 시 많이 사용됩니다. 자바 직렬화는 "자바 시스템 간의 데이터 교환을 위해 존재한다" 라고 생각하면 됩니다.
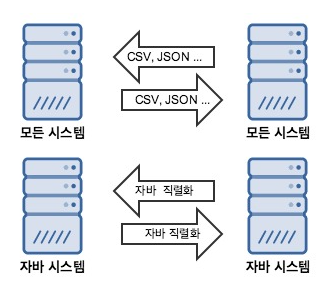
자바 직렬화 장단점
자바 직렬화의 장점은 아래와 같습니다.
- 플랫폼 독립성 : Java를 지원하는 모든 플랫폼에서 역직렬화 가능
- 사용 편의성 : 자바에서 직렬화는 사용하기 쉽습니다.
등등
자바 직렬화의 단점은 상당히 많습니다.
- 보안
- 유지보수성
- 테스트
- 싱글톤 문제
등등
결론
필요에 따라 잘 사용하면 되지만, 커스텀 직렬화, 직렬화 프록시, 역직렬화 필터링, 직렬 버전관리 등등 해야할 일이 굉장히 많기 때문에 장단점을 잘 생각하여 사용해야 합니다.
Java 동기 vs 비동기
동기
작업이 순차적인 방식으로 하나씩 실행됩니다. 각 작업은 시작되기 전에 이전 작업이 완료될 때까지 기다려야 합니다. 자바는 기본적으로 동기식 호출을 사용합니다.
public class Test {
public static void main(String[] args) {
int result1 = add(1, 3);
System.out.println(result1); // 4
int result2 = add(result1, 3);
System.out.println(result2); // 7
}
private static int add(int a, int b) {
return a + b;
}
}이 코드는 실행시켜 보지 않더라도 결과값을 예상할 수 있습니다. 바로 코드가 순차적으로 진행되기 때문입니다.
비동기
비동기 작업에서는 작업이 기본 프로그램 흐름과 독립적으로 실행될 수 있습니다. 한 작업을 시작하기 전에 다른 작업이 완료될 때까지 기다릴 필요가 없습니다. 비동기 작업은 성능과 응답성을 향상하기 위해서 자주 사용됩니다.
public class Test {
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(32);
for (int i = 0; i < 10; i++) {
final int taskId = i;
executorService.submit(() -> {
System.out.println(taskId);
});
}
}
}이 코드의 결과를 예상할 수 있을까요? 없습니다. 해당 코드의 결과는 순서 보장도 안되고, 실행 할 때마다 달라지는 것을 알 수 있습니다.
실무에서 이렇게 스레드를 생성해서 로직을 수행하는 일은 많지 않을 것이라고 생각이 듭니다. 그렇다면 실무에서는 자바를 어떻게 비동기로 사용하는 경우가 많을까요?
- 파일 I/O :Java New I/O API 사용시 메인 스레드를 차단하지 않고 파일 작업을 수행 할 수 있습니다. (스프링에서 제공하는 Webflux와 Netty 서버는 자바의 NIO 기반으로 만들어져 있습니다.)
- 네트워크 통신 : HTTP 요청 만들기 또는 소켓 처리와 같은 네트워킹 작업은 비동기 프로그램의 이점을 누릴 수 있습니다. Netty와 같은 라이브러리는 확장 가능하고 성능이 뛰어난 네트워크 어플리케이션을 구축하기 위한 네트워킹 기능을 제공합니다.
- 메시징 프로그램 : JMS(Java Message Service)와 같은 비동기 메시징 시스템은 메시지를 비동기적으로 보내고 받는 작업을 포함합니다.
- 스케줄러 및 타이머 : Java ScheduledExecutorService를 사용하면 작업이 주기적으로 또는 지정된 지연 후에 실행되도록 예약할 수 있습니다.
- 미들웨어 : 미들웨어 또는 타사 서비스와 통합하는 경우 기본 애플리케이션 스레드가 차단하지 않도록 비동기 통신을 사용합니다. 메시지큐, 기타 분산 시스템 등이 포함됩니다.
정리
기본적으로 웹 개발을 하다보면 동기적으로 코드를 작성하게 됩니다. 상황에 맞게 비동기 코드를 작성한다면 성능적 이점을 가져올 수 있습니다. 추후에 webflex, Netty 등을 공부하고 싶어지네요.
클래스, 객체
클래스
객체 생성을 위한 설계도, 템플릿 입니다. 생성될 객체를 특성화하는 일련의 속성, 메서드를 정의합니다.
객체
객체는 클래스의 인스턴스입니다. 클래스가 정의한 것들을 실제로 구현한 것입니다. 동일한 하나의 클래스로 여러 개의 객체를 만들 수 있습니다.
클래스를 객체로 만드는 것을 "인스턴스화 한다"라고 합니다.
메모리적 관점에서의 클래스, 객체
public class Main {
public static void main(String[] args) {
Car myCar = new Car("Toyota Camry", 2022);
Car anotherCar = new Car("Honda Accord", 2021);
// ...
}
}- Car 클래스의 메타 데이터 정보는 프로그램이 시작될 때 Calss Loader에 의해 JVM 메모리 (메서드 영역)에 올라가게 됩니다.
- myCar, anotherCar 객체를 생성하면 메모리가 힙 영역에 동적으로 할당되게 됩니다.
참조 블로그
https://kadosholy.tistory.com/121
https://velog.io/@p1atina/%EC%9E%90%EB%B0%94%EC%9D%98-%EC%A0%95%EC%84%9D-%ED%94%84%EB%A1%9C%EC%84%B8%EC%8A%A4%EC%99%80-%EC%93%B0%EB%A0%88%EB%93%9C
https://kadosholy.tistory.com/121
https://techblog.woowahan.com/2550/
https://techblog.woowahan.com/2551/
참고 영상
https://www.youtube.com/watch?app=desktop&v=4rLW7zg21gI
https://www.youtube.com/watch?v=RZB7_6sAtC4
https://www.youtube.com/watch?v=3iypR-1Glm0&t=653s
