자바와 객체지향
캡슐화가 깨진 CalculateCommand
public class Client {
public int someMethod(CalculateCommand calculateCommand) {
CalculateType calculateType = calculateCommand.getCalculateType();
int num1 = calculateCommand.getNum1();
int num2 = calculateCommand.getNum2();
int result = calculateType.calculate(num1, num2);
return result;
}
}직전 게시글에 작성했던 Client 코드입니다. 이 코드에는 객체지향적인 관점으로 봤을 때는 문제가 있습니다. 여러분은 어떤 것인지 아시겠나요?
public class CalculateCommand {
private CalculateType calculateType;
private int num1;
private int num2;
public CalculateCommand(CalculateType calculateType, int num1, int num2) {
if (calculateType == null) {
throw new RuntimeException("calculateType는 필수 값입니다.");
}
if (calculateType.equals(CalculateType.DIVIDE) && num2 == 0) {
throw new RuntimeException("0으로 나눌 수 없습니다.");
}
this.calculateType = calculateType;
this.num1 = num1;
this.num2 = num2;
}
public CalculateType getCalculateType() {
return calculateType;
}
public int getNum1() {
return num1;
}
public int getNum2() {
return num2;
}
}CalculateCommand를 Client가 너무 잘 알고 있다는 문제입니다. 내부에 어떤 필드가 있는지를 알고 있다는 것입니다. 하지만 현재 코드에서는
private CalculateType calculateType;
private int num1;
private int num2;
public CalculateType getCalculateType() {
return calculateType;
}
public int getNum1() {
return num1;
}
public int getNum2() {
return num2;
}내부 필드는 private로 선언하였고 getter를 사용하여 외부에는 메서드로 공개하였는데 왜 문제가 되는 것일까요? 바로 간접적으로 내부 필드를 알고 있는 상태가 되기 때문입니다. 만약 필드의 이름이 바뀐다거나 삭제된다면 그것은 바로 Client 코드에 전달될 겁니다.
이런 문제를 어떻게 해결해야 할까요?
- getter 제거
- Client에 있던 계산 로직을 CalculateCommand 안으로 넣기
CalculateCommand 캡슐화하기
public class CalculateCommand {
private CalculateType calculateType;
private int num1;
private int num2;
public CalculateCommand(CalculateType calculateType, int num1, int num2) {
if (calculateType == null) {
throw new RuntimeException("calculateType는 필수 값입니다.");
}
if (calculateType.equals(CalculateType.DIVIDE) && num2 == 0) {
throw new RuntimeException("0으로 나눌 수 없습니다.");
}
this.calculateType = calculateType;
this.num1 = num1;
this.num2 = num2;
}
public int getCalculateResult() {
CalculateType calculateType = this.calculateType;
int num1 = this.num1;
int num2 = this.num2;
int result = calculateType.calculate(num1, num2);
return result;
}
} public class Client {
public int someMethod(CalculateCommand calculateCommand) {
int result = calculateCommand.getCalculateResult();
return result;
}
}Client는 더 이상 CalculateCommand에 어떤 필드들이 있는지 모릅니다. 오직 getCalculateResult라는 메서드만 알고 있습니다.
이제 CalculateCommand는 캡슐화가 잘 되어있다고 말할 수 있게 되었습니다.
캡슐화에 대해
캡슐화는 Client 코드에게 서버코드에 정보를 숨기는 것을 의미합니다. 물론 모든 것을 숨길 수는 없습니다. 하지만 CalculateCommand의 내부 요소를 외부에 공개를 하지는 않게 되고, 제한된 요소 즉 getCalculateResult 메서드만 외부에 공개를 하는 것입니다.
물론 생성자에는 CalculateCommand가 어떤 필드들을 가지고 있는지 간접적으로 공개되기는 합니다. 그러나 생성의 경우 제한적인 영역에서 사용되기 때문에 문제가 되지는 않습니다. 만약 생성 역시 영향을 받는 코드를 제한하고 싶다면 팩토리 관련 디자인패턴을 적용하면 됩니다.
캡슐화된 코드를 다른 말로 얘기하자면 결합도는 낮추고 응집도는 높아진 코드라고 말할 수 있습니다.
결합도와 응집도
결합도
기존의 코드에서는 Client는 CalculateCommand 내부 필드에 대해 잘 알고 있었습니다. Client는 CalculateCommand의 작은 변화에도 그대로 노출됩니다. 이런 상황을 Client 와 CalculateCommand의 결합도가 높다고 표현합니다. 구체적으로는 Client가 CalculateCommand에게 지나치게 의존하고 있다고 표현할 수 있습니다.
결합도가 높은 코드는 코드 변경을 어렵게 만들고 한쪽에서 일어난 변경을 다른쪽으로 전파하는 문제가 있습니다.
응집도
응집도는 관련있는 것들끼리 얼마나 모여있는가를 의미합니다. 기존의 코드에서는 CalculateCommand에는 필드가 있고 계산로직은 Client에 있었습니다. 이것을 응집도가 낮은 코드라고 할 수 있습니다.
리펙토링 후에는 CalculateCommand에 필드도 있고 계산 로직도 존재합니다. 이것을 응집도가 높다고 표현할 수 있습니다.
생성자와 setter
public class CalculateCommand {
private CalculateType calculateType;
private int num1;
private int num2;
public CalculateCommand(CalculateType calculateType, int num1, int num2) {
if (calculateType == null) {
throw new RuntimeException("calculateType는 필수 값입니다.");
}
if (calculateType.equals(CalculateType.DIVIDE) && num2 == 0) {
throw new RuntimeException("0으로 나눌 수 없습니다.");
}
this.calculateType = calculateType;
this.num1 = num1;
this.num2 = num2;
}
public int getCalculateResult() {
CalculateType calculateType = this.calculateType;
int num1 = this.num1;
int num2 = this.num2;
int result = calculateType.calculate(num1, num2);
return result;
}
}해당 코드에 생성자쪽 코드를 변경해도록 하겠습니다. 유효성 검사는 잠시 생략하도록 하겠습니다.
public class CalculateCommand {
private CalculateType calculateType;
private int num1;
private int num2;
public void setCalculateType(CalculateType calculateType) {
this.calculateType = calculateType;
}
public void setNum1(int num1) {
this.num1 = num1;
}
public void setNum2(int num2) {
this.num2 = num2;
}
public int getCalculateResult() {
CalculateType calculateType = this.calculateType;
int num1 = this.num1;
int num2 = this.num2;
int result = calculateType.calculate(num1, num2);
return result;
}
}위의 코드의 문제는 무엇일까요? CalculateCommand의 내부필드가 외부에 그대로 노출되는 문제도 있고, 하지만 더 큰 문제는 불완전한 CalculateCommand 객체가 생성된다는 문제가 있습니다.
public class SetterCodeExample {
public static void main(String[] args) {
CalculateCommand calculateCommand = new CalculateCommand();
// 실수로 아래 코드를 누락했다면 ?
// calculateCommand.setCalculateType(CalculateType.ADD);
calculateCommand.setNum1(100);
calculateCommand.setNum2(3);
Client client = new Client();
int result = client.someMethod(calculateCommand);
System.out.println(result);
}
}기본 생성자로 생성을 하고, 아래에서 setter로 값을 초기화 하고 있습니다. 여기서는 어떤 연산을 해야하는지 정의되지 않고 someMethod가 실행될 것입니다. 즉 CalculateCommand는 불완전한 상태로 실행된 것입니다. 모든 필드를 초기화해야하는 생성자가 있다면 불완전하지 않은 완전한 상태의 CalculateCommand 객체를 생성할 수 있습니다. setter 보다는 생성자를 적극적으로 활용하는 것이 좋습니다.
getter와 setter를 지우는 것은 객체지향적인 코드로 가는 방법입니다. 하지만 상황에 따라서 getter를 없애게 불가능한 경우가 있습니다.
기술적인 문제로 getter가 필요한 경우
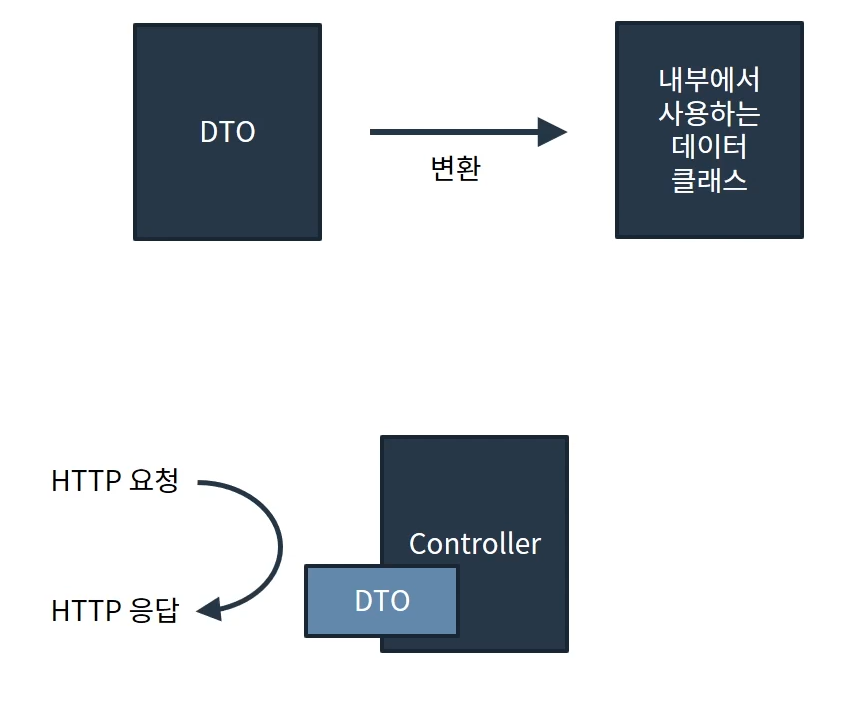
외부와 접점이 있는 DTO와 내부에서 사용하는 데이터 클래스가 변환 과정을 거칠 경우 DTO에 getter가 필요합니다.
또 컨트롤러에 DTO로 HTTP 응답을 하는 경우입니다. 반환하는 DTO에 getter가 없다면 해당 필드는 HTTP 응답에 포함되지 않습니다. DTO에 getter가 하나도 없다면 HTTP 요청이 실패하게 됩니다.
결론
객체지향적인 코드는 결합도는 낮고, 응집도는 높은 코드 = 유지보수하기 좋은 코드
결론은 우리는 객체지향적인 코드를 만들어야 합니다.
해당 게시글은 프로그래머스 스쿨 강의
"실무 자바 개발을 위한 OOP와 핵심 디자인 패턴(푸)"
를 정리한 내용입니다. 쉽게 잘 설명해주시니 여러분도 강의를 듣는 것을 추천드립니다.
