참고 사이트
순서
✅ DB에 데이터 저장 후 추출 vs API로 호출해오기 : 둘 중 더 효율적인 것은?
👉 DB에 데이터 저장하는 방법 고안 & 초기 세팅
⬜ json 값에서 원하는 정보만 추출해서 DB에 담기
2. DB에 데이터 저장하는 방법 고안 & 초기 세팅
DB에 데이터를 저장하는 방법을 어떻게 할까 고안해봤다.
첫 번째로 생각한 건 open API 로 값을 전부 다 불러와서 이를 차례차례 json 데이터 값으로 바꿔주는 거였다.
🔎 "사전 내려받기"로 JSON 데이터 얻기
근데, 첫 번째 방식 구현을 고민하다가 찾은 게 사전 내려받기 기능이었다!
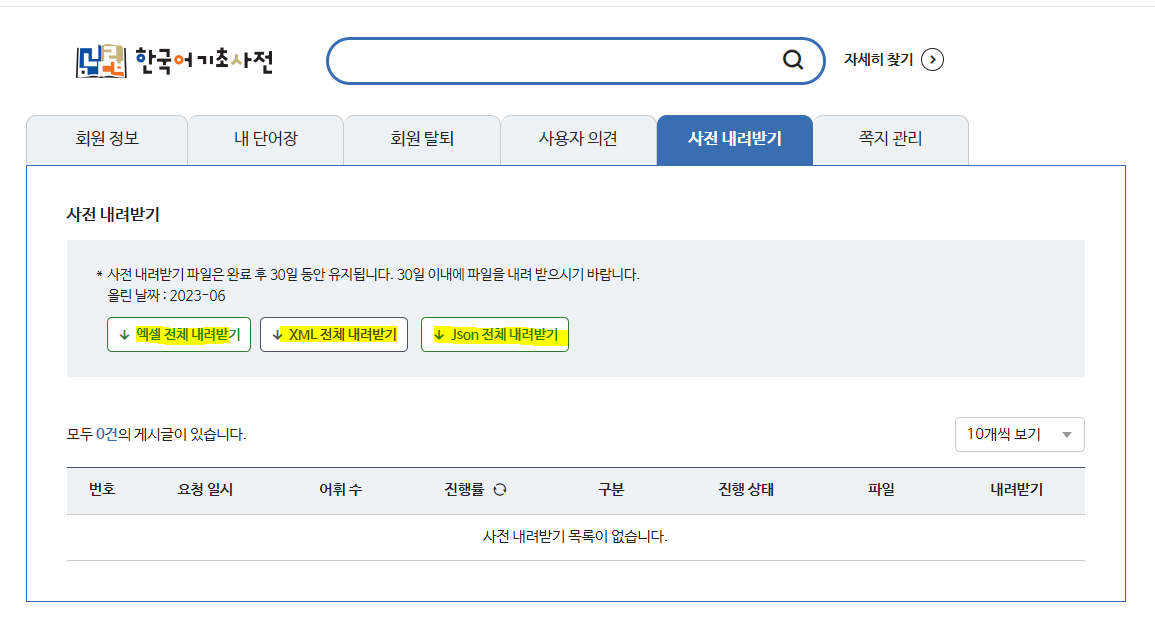
한국어 기초사전 홈페이지에서 가입하고 내 정보 관리를 들어가면 사전 데이터를 받을 수 있다!
심지어 json 형태로도 제공해서 여러모로 유용하게 사용할 수 있다.
다운 받아서 압축을 풀어준 뒤 사용해주면 된다.
🔎 json 형태 확인해보기
파일을 받은 뒤에는 내가 어떤 값을 추출해야 할 지 형태를 보고 체크해야 한다.

LexicalResource > Lexicon > LexicalEntry > Lemma > feat > val
에 단어가 있다.
LexicalEntry 는 리스트 형태로 이루어져 있는 것 같다.

LexicalResource > Lexicon > LexicalEntry > SenseExample > feat[n] > val[1]
에 단어 용례들이 있다.
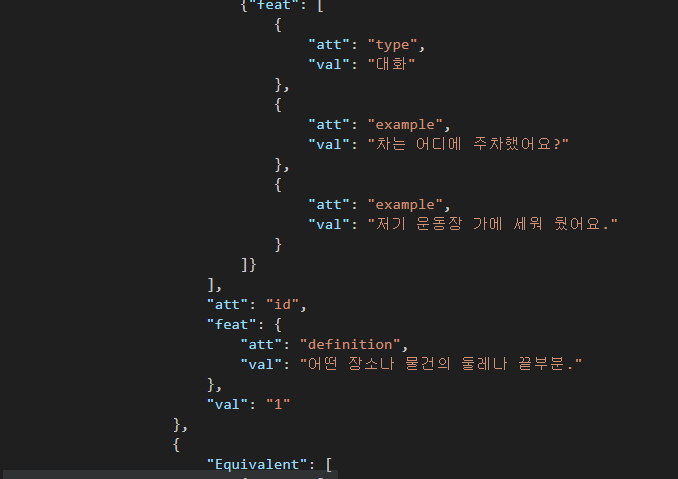
LexicalResource > Lexicon > LexicalEntry > feat > val 에 단어 뜻이 있다.
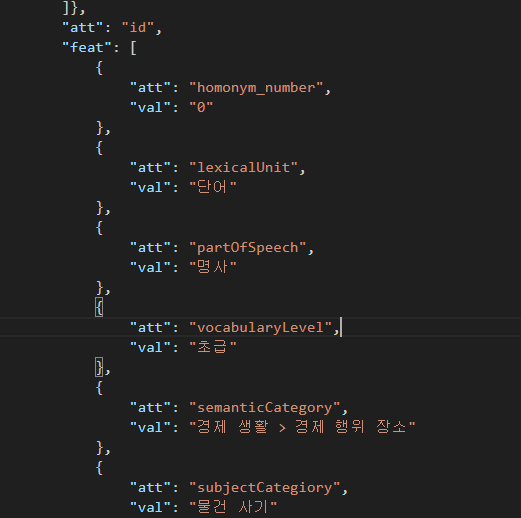
LexicalResource > Lexicon > LexicalEntry > feat > val 에 단계가 있는데, feat["att"]의 위치와 나란히 있다.
난이도는 단어에 따라 존재하는 것과 존재하지 않는 것이 있나보다.
없는 건 난이도를 미분류로 두면 될 것 같다.
.
우리가 필요한 것들의 위치, 그리고 구조를 대강 파악했다.
🔎 json 값 불러와보기 test
import json
with open(
"F:/nbc/final_project/전체 내려받기_한국어기초사전_JSON_20230612/1079331_5000.json",
"r",
encoding="utf-8",
) as file:
data = json.load(file)
print(data["LexicalResource"]["GlobalInformation"])이렇게 해서 json 값 안의 것이 잘 불러와지는지 한번 확인해보자.

잘 불러와진다.
경로를 잘 찾아서, 원하는 값을 추출한 뒤 다시 걸러주면 될 것 같다!
🔎 model 세팅
값이 잘 불러와졌으니, 단어를 담을 model을 세팅해주자.
기존에 만들어줬단 crawled_data 앱의 model에 추가해 줄 것이다.
# crawled_data/models.py
class KrDictQuiz(models.Model):
word = models.CharField(max_length=32)
difficulty = models.PositiveIntegerField()word에 단어,
difficulty에 단어의 난이도를 저장하려고 한다.
# crawled_data/models.py
class KrDictQuizExplain(models.Model):
dict_word = models.ForeignKey(
KrDictQuiz, on_delete=models.CASCADE, related_name="explains"
)
content = models.CharField(max_length=256)dict_word는 ForeignKey로 KrDictQuiz를 받아와준다.
content는 단어에 대한 설명을 저장해주려고 한다.
# crawled_data/models.py
class KrDictQuizExample(models.Model):
dict_word = models.ForeignKey(
KrDictQuiz, on_delete=models.CASCADE, related_name="example"
)
content = models.CharField(max_length=256)dict_word는 ForeignKey로 KrDictQuiz를 받아와준다.
content는 예시 문장을 저장해주려고 한다.
