0. Intro
- Dropout 의 기법에 대해 서술한 논문을 리뷰입니다.
- 출처 : Journal of Machine Learning Research 2014
- 논문
1. Abstract & Intro
- 드랍아웃은 overfitting 을 해결하기 위한 테크닉 입니다.
- Noise 가 심한 Train data 의 경우, 즉 Train data 에만 존재하고 Test data 에서는 존재하지 않는 데이터의 특징이 있는 경우, NN 이 학습이 많이 될 경우, 해당 Noise 를 일반적인 규칙 이라고 생각하고 학습이 될 수 있습니다.
- Train accuracy 는 올라가는데 Val accuracy 는 떨어지는 현상
- 이러한 현상은 데이터의 분포가 고르더라도 발생 가능.
- 위의 경우, 가장 이상적인 해결책은 가능한 모든 세팅 (ML Grid Search 같이 모든 경우의 수) 에 대한 결과값 (prediction) 에 대한 평균값을 내는 것입니다.
- 하지만 오랜 시간과 연산 시간이 엄청 깁니다.
- 엄청난 COST
- 혹은 여러 다른 모델을 사용해보는 것입니다. (model combination)
- 다른 모델이란 즉 모델의 구조가 다르던가, 모델의 architecture 가 다른 것을 말합니다.
- 결국은 데이터가 엄청 많아야 하고 (각 모델을 다른 데이터로 학습시켜야 하니) 또한 각 모델을 학습시켜야하기 때문에 여전히 HIGH COST입니다.
- 드랍아웃은 이러한 것들을 해결하기 위한 테크닉입니다.
1-1. At training time, 학습할 때 드랍아웃
- 드랍아웃의 핵심 아이디어는 학습 중 랜덤하게 unit 을 제거하는 것 입니다.
- unit 이 드랍될 확률을 p (probability) 라고 표시함
- 이 확률은 고정되어있으며 설정한 시점으로부터 training 중 변하지 않습니다.
- 하여, unit 끼리 과도하게 의존하는 것을 방지할 수 있습니다.
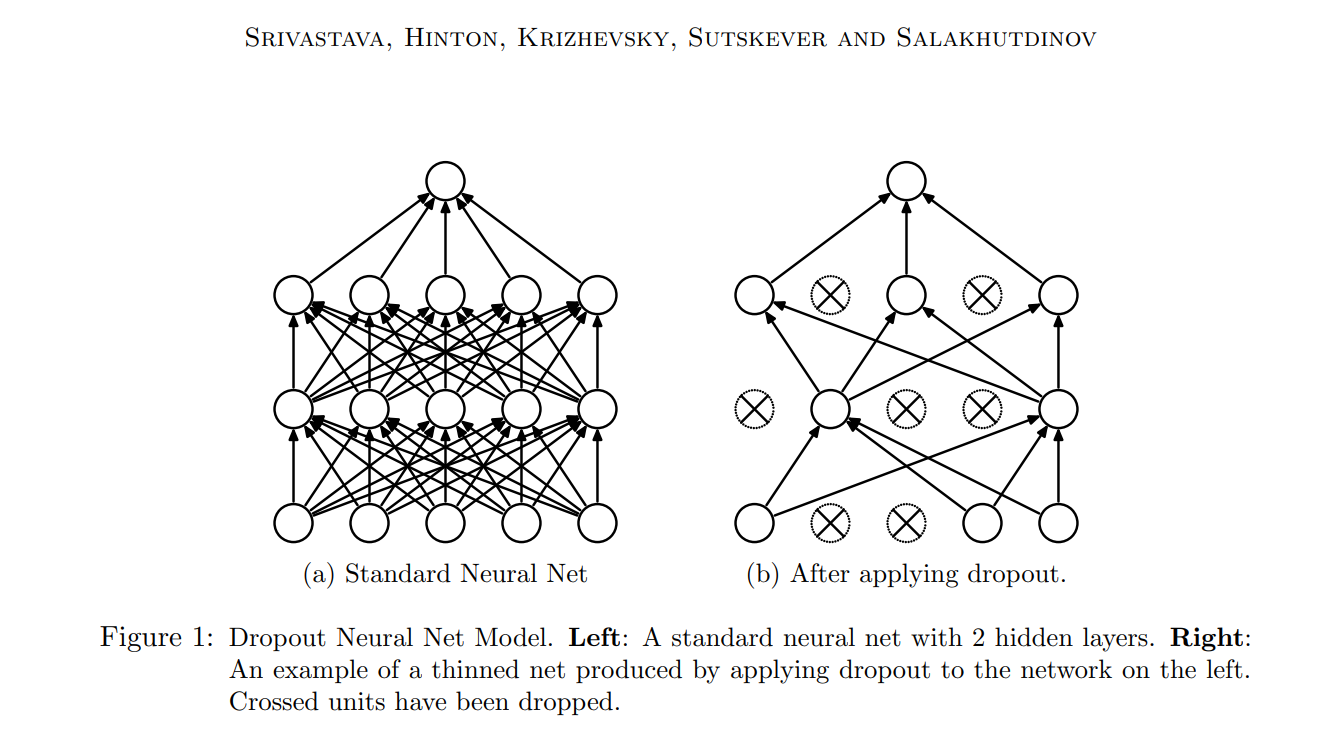
- Figure 1 을 보면 왼쪽은 기존의 모델, 오른쪽은 드랍아웃 된 모델입니다.
- 드랍아웃이 매번 확률적으로 다른 노드를 드랍아웃하기 때문에 여러 thinned model 이 만들어지는 효가가 있습니다.
- 예를들어, n 개의 노드가 존재한다면, 각 노드를 사용할지 말지 (1,0) 에 따라 2^n 개의 thinned model.
- 참고) 드랍아웃된 모델을 “Thinned model” 이라고 함. 즉, 중간중간 node connections 들이 사라짐으로써 얇아진 것이라 이해하면 좋을 것 같습니다.
- 각 thinned model 은 가중치를 공유, 즉 매번 드랍아웃으로 인하여 다른 노드들의 조합이더라도 전체 네트워를 구성하는 노드의 값이 많이 변하지는 않습니다.
- 결국 드랍아웃 때문에 가중치 자체가 크게 변하지 않습니다.
1-2. At test time, validation 할 때 드랍아웃

- 학습된 2^n 개의 모델을 합친다는 것입니다.
- 만약 이 모든 모델의 예측한다면, (prediction) 을 가져다 평균을 내는 작업은 여전히 cost inefficiency 가 좋지 않습니다. (위에 이야기한 여러 다른 모델들의 결과를 내서 평균값을 내는것과 다를게 없습니다. 드랍아웃에 의미가 없음)
- Training 시, 드랍아웃에서 각 노드는 확률 p 에 따라 전달이 될 수, 안될 수 있습니다. 논문에서는 이 드랍아웃을 Testing 시에는 하고있지 않습니다.
- 논문에서는 fully connected model 을 가져와 approximating 하는 예시를 다루고 있습니다. (Figure 2)
- approximate averaging method: 학습 중에 가중치 업데이트를 평균화하는 방법
- 위의 Approximate averaging method 는, 모든 뉴런을 사용합니다. (드랍아웃 X)
- 대신에 각 뉴런에 확률 p 를 곱해서 기댓값을 얻는 방식으로 여러개의 thinned model 을 하나로 합친 가상의 final model 로 추정할 수 있습니다. (Figure 2 확인)
- p * w → scaled-down
- 즉, 모든 weight 에 확률 p 를 곱하여 2^n 개의 (weight 를 공유하는) thinned model 들을 하나로 합친 하나의 (가상의) final model 로 추정할 수 있습니다.
2. Model description
Neural Network with L hidden layers
- l 은 hidden layers 의 index 이며, 1 부터 L 까지입니다.
- z(l) 은 layer l 에 들어가는 input 이고, y(l) 은 layer l 의 ouput 입니다.
- y(0) = x 이며, first input
- W(l), b(l) = l 의 가중치(weight) 과 편향(bias)
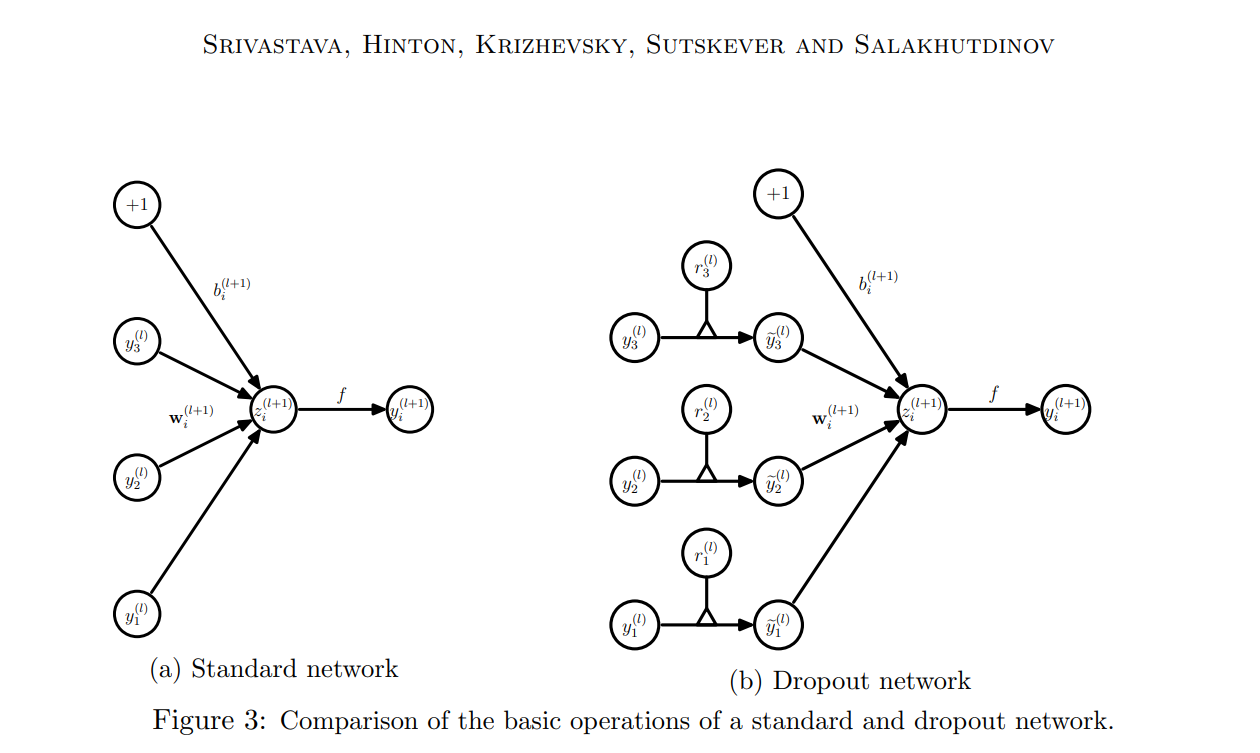
2-1. Standard feed forward
- L-1 개의 레이어와 임의의 뉴런 i 에 대한 standard feed forward
- f = activation function
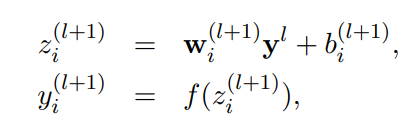
2-2. Standard feed forward with dropout
- L-1 개의 레이어와 임의의 뉴런 i 에 대한 standard feed forward with dropout
- = element-wise product
- f = activation function
- r(l) = a vector of independent Bernoulli random variables each of which has probability p if being 1
- 독립 베르누이 확률 변수 = 베르누이 분포를 따르는 확률 변수로, 두 가지 값 중 하나를 갖는 이산 확률 변수. 0 또는 1의 값
- 즉, 확률적으로 뉴런을 쓸지 말지 구함.
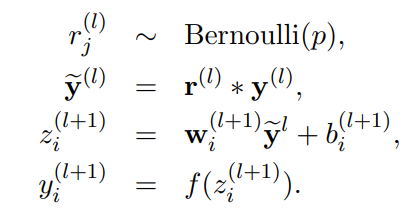
3. Learning dropout nets
- training dropout neural nets 의 과정을 설명입니다.
3-1. Backpropagation
- SGD (Stochastic Gradient Descent) 확률적 경사 하강법으로 학습할 수 있습니다.
- SGD?
- 함수의 최솟값을 찾기 위해 현재 위치에서의 기울기(경사)를 계산하고, 그 기울기의 반대 방향으로 이동하는 최적화 알고리즘
- 일반적인 경사 하강법과 달리 각각의 훈련 데이터 포인트에 대해 기울기를 계산하고 파라미터를 업데이트함.
- 따라서 각 단계에서 사용되는 데이터가 무작위로 선택되기 때문에 "확률적"이라는 용어가 사용.
- 전체 데이터셋을 사용하는 일괄적인 경사 하강법과 비교하여 계산 비용이 낮음.
- 매 mini batch마다 드롭아웃을 실행
- 해당 thinned network 단위로 forward/backward가 진행됨
- 각 파라미터의 가중치는 각각의 미니배치에서 학습한 weights를 평균내서 구함
- 당연하게도, 미니배치 학습 시 사용되지 않은 뉴런은 해당 파라미터의 가중치를 구하는데 관여하지 않음
- SGD 를 향상시키기 위해 Momentum, Annealed learning rates, L2 weight decay 같은 것들이 주로 사용되는데 이것들과 dropout 을 함께 사용해도 좋은 결과가 있었다고 함.
- L2 decay: 모델의 가중치(weight)를 학습 과정에서 정규화하기 위한 기법 중 하나
- Although dropout alone gives significant improvements, using dropout along with max-norm regularization, large decaying learning rates and high momentum provides a significant boost over just using dropout.
- Max-norm regularization?
- 머신러닝 모델에서 가중치의 크기를 제한하여 과적합을 줄이는 정규화 기법
- 각각의 가중치 벡터의 크기가 특정 임계값을 초과하지 않도록 제한
- DNN 에서 기울기 소실 문제 (vanishing gradient problem) 나 폭주 문제 (exploding gradient problem) 를 완화하고 안정적인 훈련을 돕기 위한 하나의 방법
- 논문에서 Max-norm regularization 과 dropout 이 함께 사용되면 좋은지 제시한 가설
- Max-norm regularization 을 하면 large learning rate 를 사용해도 학습 과정이 불안정 하지 않음.
- dropout 에 의해 추가되는 noise 는 원래라면 도달하지 못했을 다양한 region 을 탐색함.
- 즉, max-norm 을 통하여 dropout 의 단점을 예방.
- 이와 함께 learning rate decay 를 통하여 learning rate 를 감소시켜 minimum 에 도달할 수 있게 도와줌.
3-2. Unsupervised Pretraining
Pretraining
- 모델을 초기화하거나 사전에 학습시키는 과정
- Unlabeled data 를 활용하여 학습시킬 때 사용됨.
Fine tuning
- 모델을 사전 훈련된 가중치로 초기화한 후, 특정 작업이나 도메인에 맞게 모델을 미세 조정하는 과정
- 전이 학습(Transfer Learning)의 한 형태
- 이미 학습된 모델의 일부 또는 전체를 새로운 작업에 재사용하는 방법
Dropout can be applied to finetune nets that have been pretrained
- pretrained weight에 1/p 를 곱하여 fine tunning 에서 사용 가능
- 단 드랍아웃 기법의 확률적 특성 때문에 pretrained weight 가 변형되는 것을 막기 위해 가중치를 임의로 초기화했을 때 보다 더 작은 learning rate 를 사용해야 함.
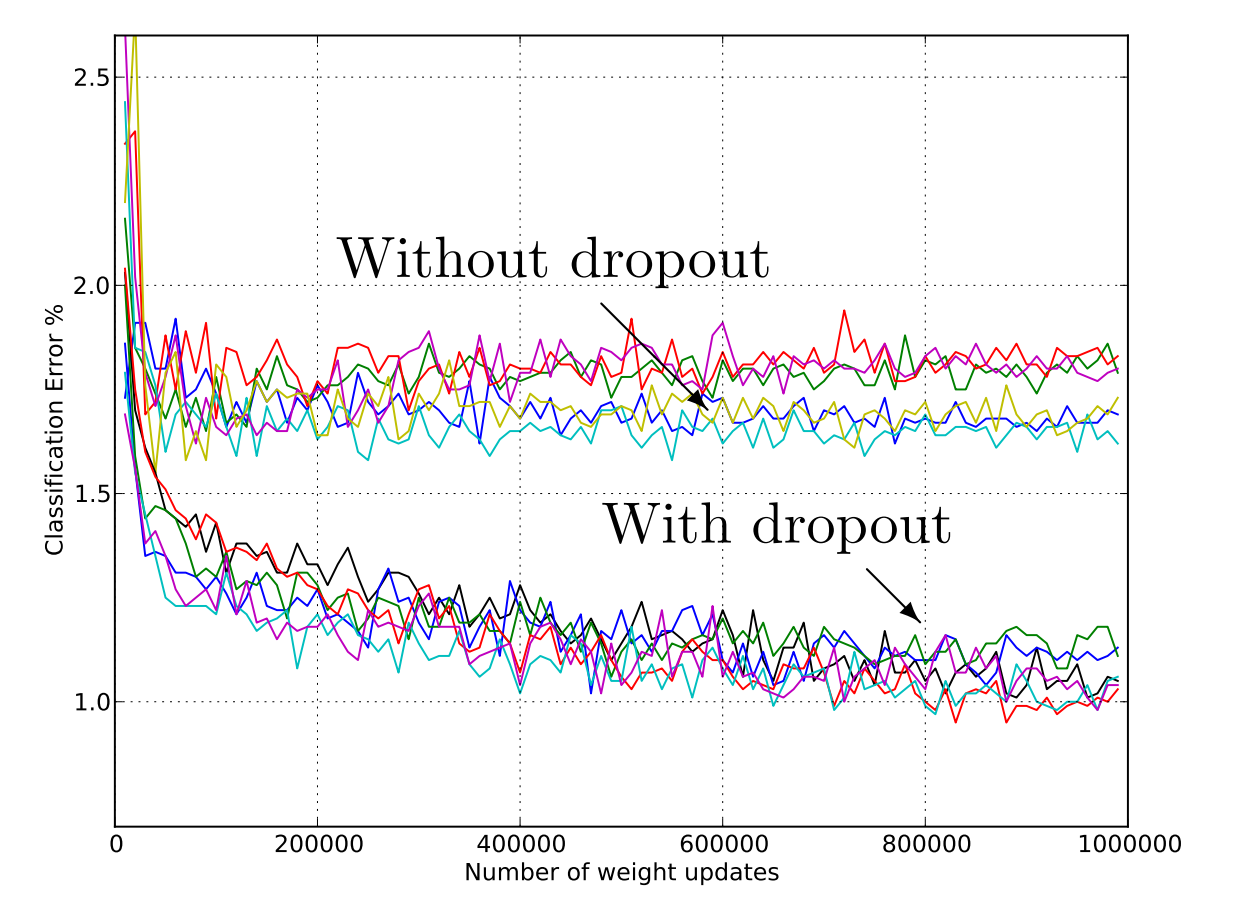
Experimental Results
- 실험 결과는 카테별로 있는 논문에서 확인 가능합니다.

AI (ML/DL) 학습