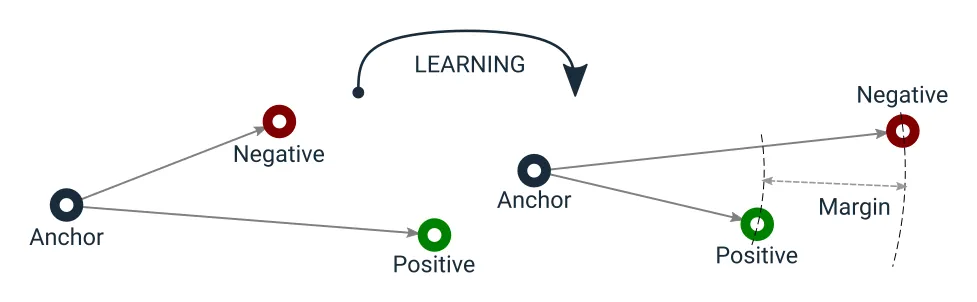
0. 개요
- 나비 종류 구분 찾는 도중 추천 받아 작성하였으며,
- 비슷한 application 으론 얼굴인식, fine-grained classification, 유사 이미지 검색, 추천시스템 등이 있습니다.
1. 무엇
- loss function 입니다.
- 이미지 인식, 얼굴 인식, 객체 구별하는 작업에서 사용됩니다.
- 왜 인지는 밑에서 더 작성하겠습니다.
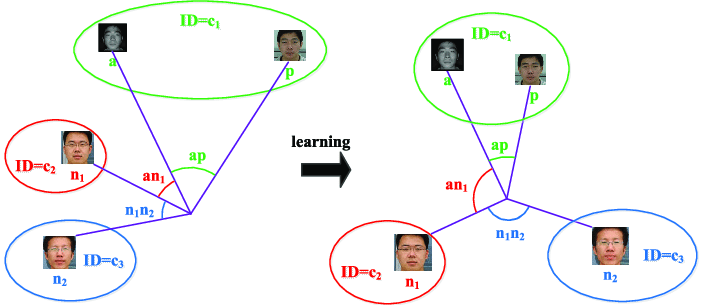
- 학습 과정에서 모델이 세 개의 데이터 포인트를 사용하여 학습하는 것 입니다.
- Anchor: 기준점
- Positive: 긍정적 예시 (Anchor 와 같은 범주에 속하는 데이터 포인트)
- Negetive: 부정적 예시 (Anchor 와 다른 범주에 속하는 데이터 포인트
1-1. 방식
- Anchor 와 Positive 사이의 거리를 최소화하고, 동시에 Anchor 와 Negative 의 거리를 최대화 하는 것 입니다.
- 이를 통하여 모델은 동일한 범주의 데이터는 가깝게, 다른 범주의 데이터는 멀리 배치하도록 학습됩니다.
- 식은 아래와 같습니다.
- 여기서 d(A, X) 는 Anchor 와 X 사이의 거리를 의미합니다.
- d 는 Euclidean distance, 유클리드 거리, 두 점 사이의 직선 거리
- margin 은 두 거리 사이의 최소차이를 정의합니다.
- 하여, loss 는 0 혹은 0 초과의 수치로 나오게 됩니다.
2. CrossEntropy 와 차이점
- Triplet loss 는 데이터 포인트 간의 상대적인 관계를 학습하는 것에 초점을 맞춘 반면, CrossEntropy loss 는 분류 문제에서 개별 클래스의 정확한 예측에 더 초점을 맞춥니다.
- 즉, 클래스의 종류가 여러개인 coco dataset 혹은 voc dataset 과 같은 경우엔 CrossEntropy 가 더 적합할 겁니다.
- 반면에 제가 수업시간에 사용했던 나비 분류 데이터셋과 같은 경우, 나비의 종류 별 같은 특징들이 있겠지만 사진의 구도, 나비의 포즈 혹은 무늬의 미세한 차이들이 있을 수 있습니다. 이와 같은 경우, triplet loss 가 더 적합할 수 있겠습니다.
3. Triplet loss 의 활용
3-1. Face recognition
- 얼굴 인식 시스템에서 모델이 같은 사람의 얼울을 유사하게, 다른 사람의 얼굴을 다르게 인식하도록 학습하는데 사용됩니다.
3-2. Similar Image Retrieval
- 이미지 검색 시스템에서 모델이 주어진 이미지와 유사한 이미지를 찾아내도록 학습할 수 있습니다.
3-3. Recommendation systems
- 제품이나 콘텐츠 추천에서 사용자의 행동이나 선호도에 기반하여 유사한 항목을 추천하는데 사용될 수 있습니다.
3-4. Multidimensional data visualization
- 고차원 데이터를 저차원으로 축소하여 시각화 할 때 데이터 포인트간의 상대적인 관계를 보존하는데 도움을 줄 수 있습니다.
3-4-1. 예시
- 생물정보학 또는 유전체학 데이터에서 triplet loss 를 사용할 수 있습니다.
- 수만은 유전자, 단백질 또는 세포 표현형을 포함하는데, 이러한 고차원 데이터를 2차원 또는 3차원 공간으로 축소하는데 triplet loss 를 사용할 수 있습니다. → 인사이트 도출 가능
- 간단하게 설명하자면, 생물학적 관계를 쉽게 이해하고 해석하기 위함
- 그만큼 구분을 잘한다 뭐 이런 뜻 같습니다.
3-5. NLP
- 자연어 처리에서 문장, 문서, 또는 단어를 임베딩하여 유사한 의미를 가진 항목을 가깝게 배치하는데 사용됩니다.
4. Triplet loss 와 비슷한 loss
4-1. Contrastive loss
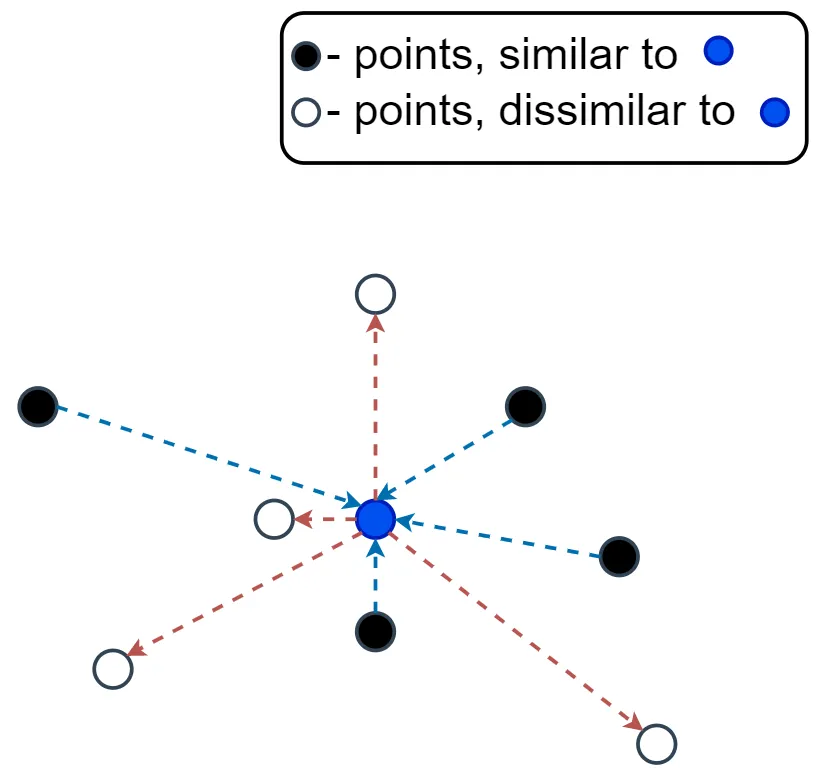
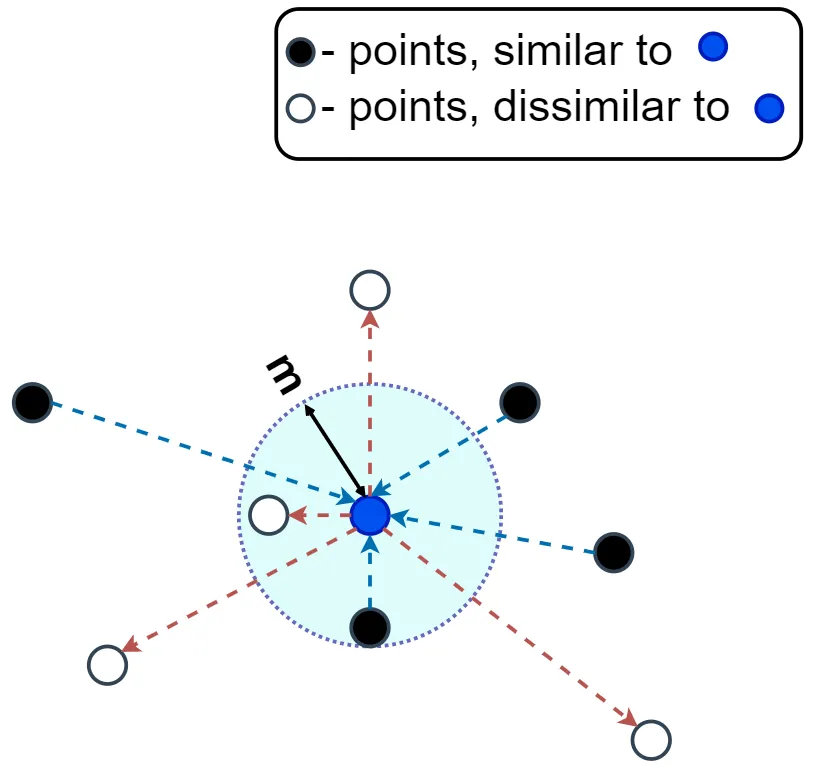
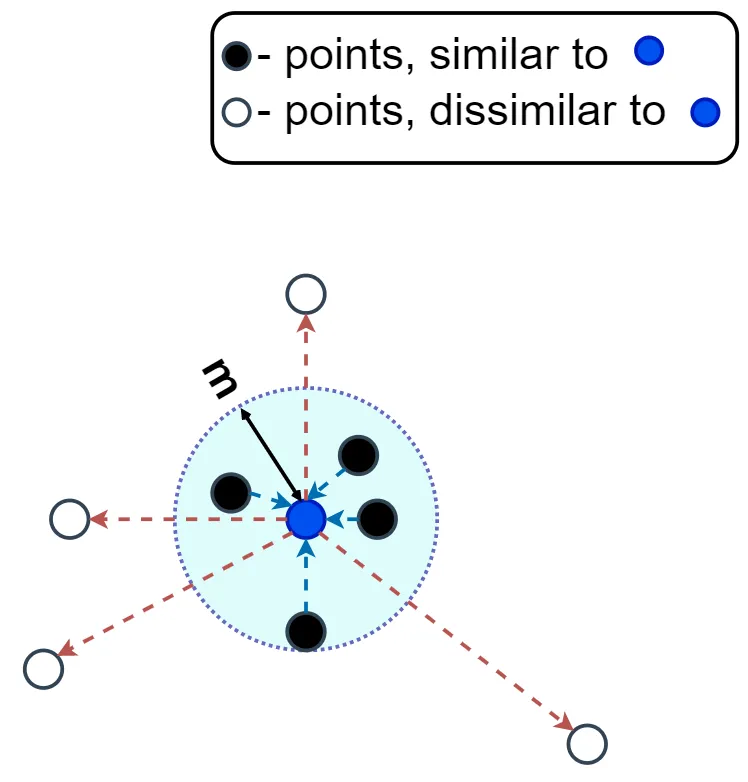
- Pair 에 기반한 학습 접근법을 사용합니다. 각 쌍은 두 데이터 포인트로 구성되며, 이들이 같은 클래스에 속하는지, 또는 다른 클래스에 속하는지에 따라 학습됩니다.
- 유사한 쌍(Pair)의 데이터 포인트 간 거리를 최소화하고, 다른 쌍의 데이터 포인트 간 거리를 최대화 하는데 목적을 둡니다.
- triplet 과의 차이점은, triplet 의 경우, anchor, positive, negative 이 세개의 데이터 포인트를 두고 본다면 contrastive 는 anchor 과 the other one (either positive or negative) 두개의 데이터 포인트만 두고 본는 것 입니다.
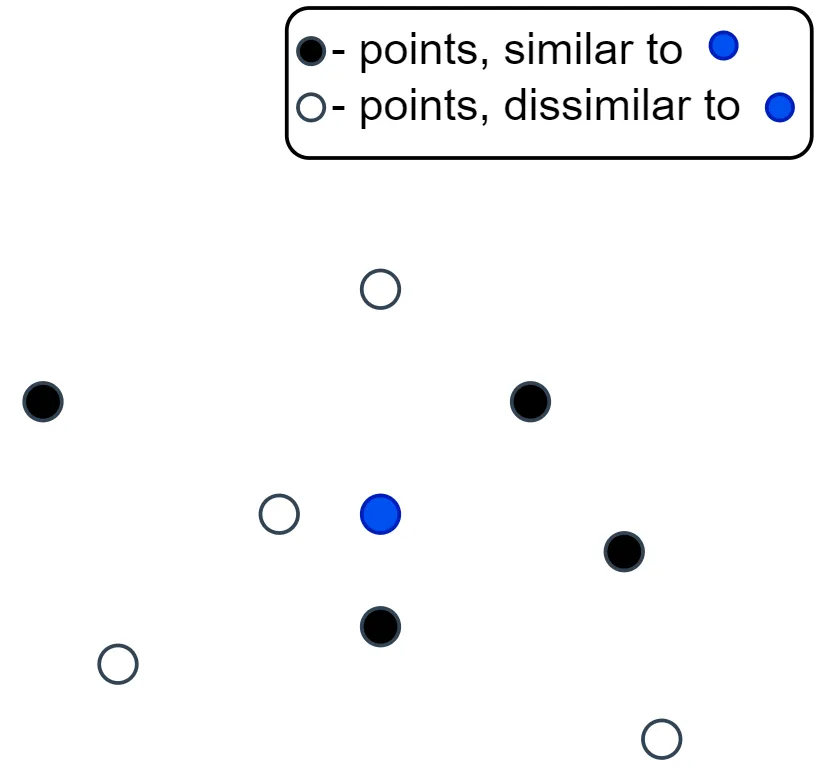
4-2. Center loss
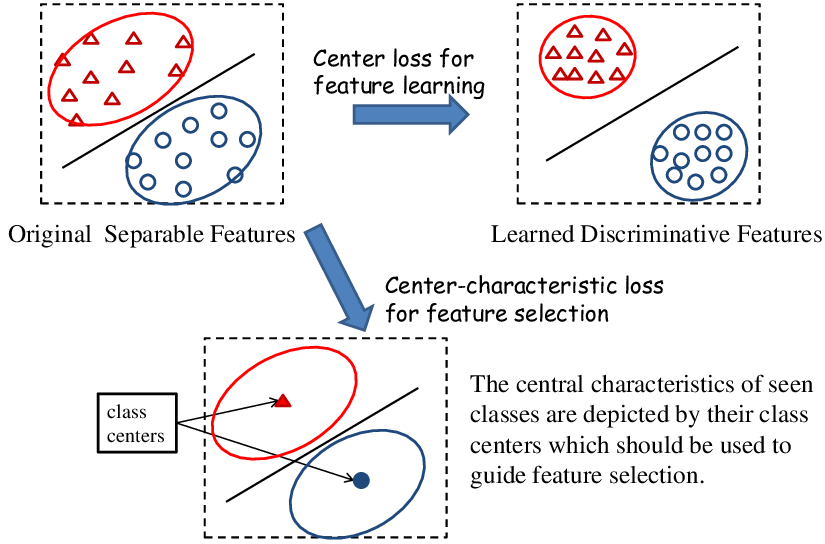
- 각 클래스에 대한 중심(centroid)을 학습하고, 클래스 내 데이터 포인트가 해당 중심에 가까이 위치하도록 합니다.
- 이는 클래스 간 분산을 최대화하고 클래스 내 분산을 최소화 하는데 도움이 되며, 주로 얼굴 인식과 같은 임베딩 문제에 사용됩니다.
4-3. Quadruplet Loss
- Triplet loss 의 확장판
- 네 개의 데이터 포인트 (Anchor, Positive, Negative1, Negative2) 를 사용합니다.
- Triplet loss 와 유사하게 작동하지만 Negative data point 를 두 개를 갖고있습니다. 이것은 모델이 더 복잡한 데이터 구조를 학습할 수 있도록 합니다.
4-4. Siamese Networks with Pairwise Loss
- 시아미즈 네트워크(Siamese Networks)는 쌍으로 구성된 입력을 처리하고, 각 쌍이 유사한지 또는 다른지를 판별합니다.
- 이 네트워크는 주로 이미지 검증, 서명 검증 등의 작업에 사용되며, 각 쌍의 유사성 또는 차이를 학습하는 데 사용됩니다.
4-4-1. Siamese Networks(시아미즈 네트워크)
- 신경망 구조입니다.
- 두 입력을 동시에 처리할 수 있는 두 개의 동일한 서브 네트워크로 구성됩니다. 이 두 서브네트워크는 가중치를 공유하며, 동일한 구조와 매개변수를 가지고 있습니다.
- 주요 목적은 두 입력 사이의 관계나 유사도를 학습하는 것 입니다.
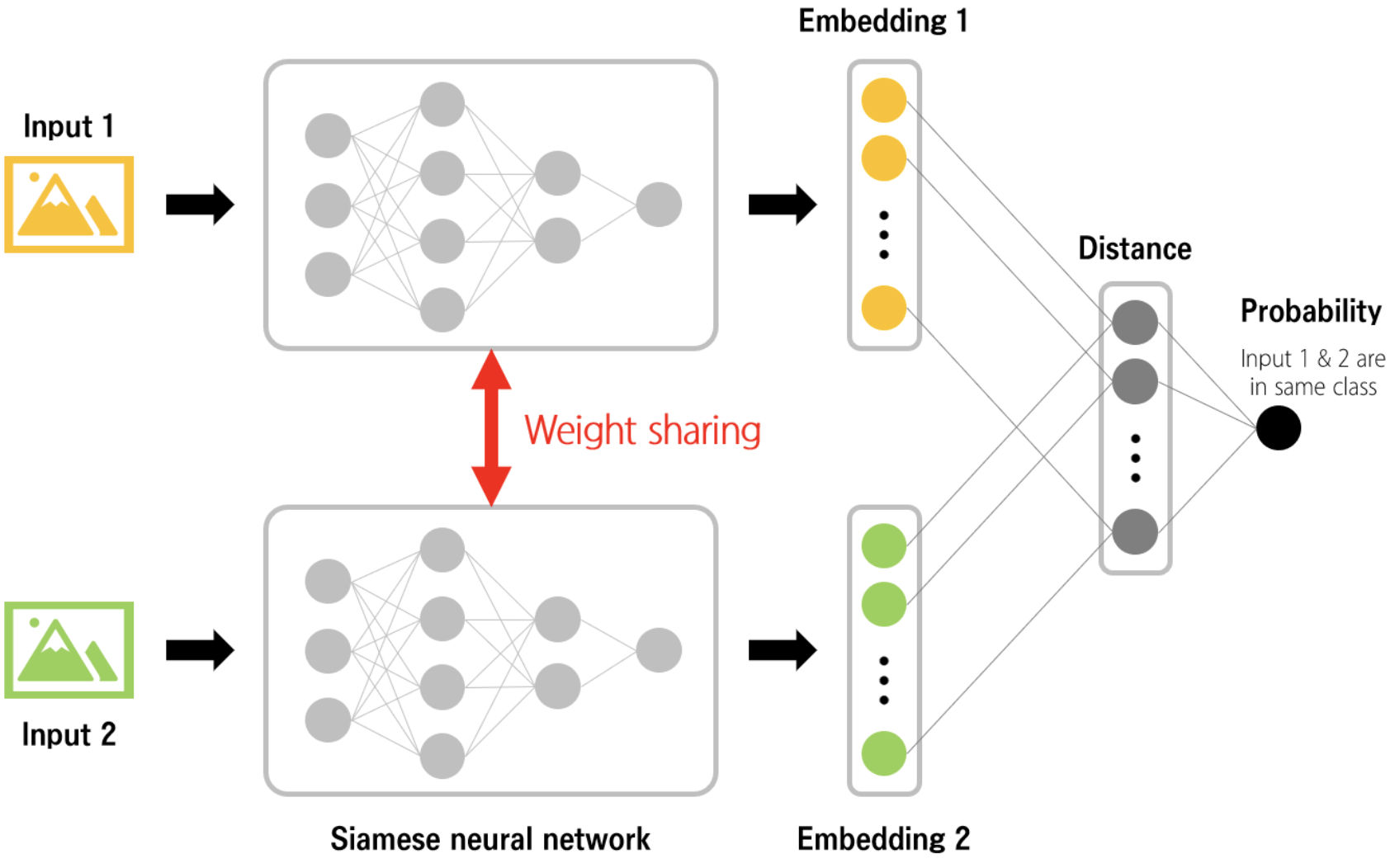
주요 특징과 활용
- 가중치 공유
- 두 서브네트워크가 동일한 가중치를 공유하기 때문에, 네트워크는 두 입력 사이의 유사도를 효율적으로 학습할 수 있습니다.
- 유사도 학습
- 두 데이터 포인트가 유사한지 도는 다른지를 판단
- 응용분야
- 얼굴인식, 서명 검증, 의료 이미지 분석 등
작동 원리
- 두 입력 샘플을 받아 각각의 서브네트워크를 통과 시킵니다. 두 서브네트워크의 출력(임베딩 또는 특성 벡터)은 유사도 측정을 위해 비교됩니다.
- 이 비교는 보통 거리 함수(e.g. 유클리드 거리)나 유사도 메트릭을 사용하여 수행됩니다. 학습 과정에서는 이 유사도 점수를 기반으로 네트워크의 가중치를 조정하여, 유사한 샘플은 가깝게, 불유사한 샘플은 멀게 배치하도록 합니다.
4-4-2. Pairwise loss
- RankNet Loss: RankNet은 순위화 작업에 사용되는 Pairwise Loss의 한 예입니다. RankNet은 주로 검색 엔진 최적화에서 사용되며, 두 항목의 순위를 비교하여 올바른 순서를 학습합니다.
- Contrastive Loss: 앞서 설명한 Contrastive Loss도 Pairwise Loss의 한 형태로 볼 수 있습니다. 두 데이터 포인트가 같은 클래스에 속하면 거리를 최소화하고, 다른 클래스에 속하면 거리를 최대화하도록 학습합니다.
5. Triplet loss 의 변형
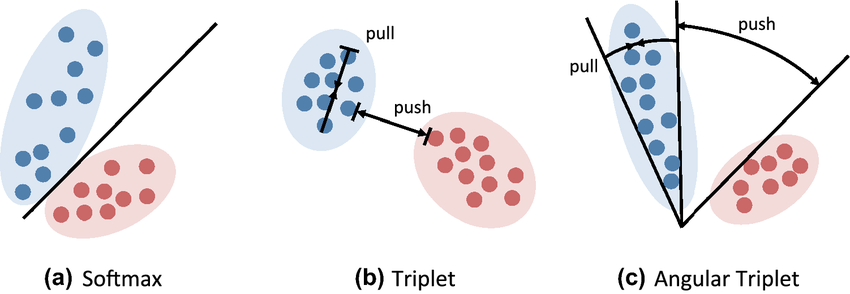
5-1. Angular Triplet loss
- 데이터 포인트간의 각도를 기반으로 학습합니다.
- 기존의 Triplet Loss가 유클리드 거리를 사용하여 anchor, positive, 그리고 negative 사이의 거리를 조절하는 데 집중한다면, Angular triplet loss는 각도를 중심으로 이러한 관계를 최적화합니다.
- +) 유클리드 거리가 무엇인가?
- Euclidean distance, 기하학에서 두 점 사이의 직선 거리를 측정하는 방법입니다. 두 점 간의 최단 경로를 나타냅니다. 피타고라스의 정리를 사용하여 계산할 수 있습니다. (자세한 내용은 구글에 검색해보세요)
장점
- 향상된 구별력: 각도를 기반으로 한 접근 방식은 유클리드 거리 만을 사용하는 것보다 더 미묘한 패턴과 구조를 학습할 수 있게 해줍니다.
- 강인한 특성 학습: 데이터 포인트의 방향성에 초점을 맞춥니다. 그러므로 크기 변화나 회전 같은 변형에 대한 모델의 강인성이 향상될 수 있습니다.
6. 마무리
- Triplet loss code example
import torch
import torch.nn.functional as F
def euclidean_distance(x, y):
"""
Compute Euclidean distance between two tensors.
"""
return torch.pow(x - y, 2).sum(dim=1)
def compute_distance_matrix(anchor, positive, negative):
"""
Compute distance matrix between anchor, positive, and negative samples.
"""
distance_matrix = torch.zeros(anchor.size(0), 3)
distance_matrix[:, 0] = euclidean_distance(anchor, anchor)
distance_matrix[:, 1] = euclidean_distance(anchor, positive)
distance_matrix[:, 2] = euclidean_distance(anchor, negative)
return distance_matrix
def batch_all_triplet_loss(anchor, positive, negative, margin=0.2):
"""
Compute triplet loss using the batch all strategy.
"""
distance_matrix = compute_distance_matrix(anchor, positive, negative)
loss = torch.max(torch.tensor(0.0), distance_matrix[:, 0] - distance_matrix[:, 1] + margin)
loss += torch.max(torch.tensor(0.0), distance_matrix[:, 0] - distance_matrix[:, 2] + margin)
return torch.mean(loss)이후 스터디 목차에 올라오는 내용은 스터디에서 다른 분들과 학습한 내용을 기재하였습니다.

AI (ML/DL) 학습