2차 프로젝트 회고
목차
4. DB Dummy Data Automated Scripts
프로젝트 개요
2023.02.24 ~ 2023.03.10
서울지역을 중심으로 한 호텔 정보를 보여주는 웹 서비스.
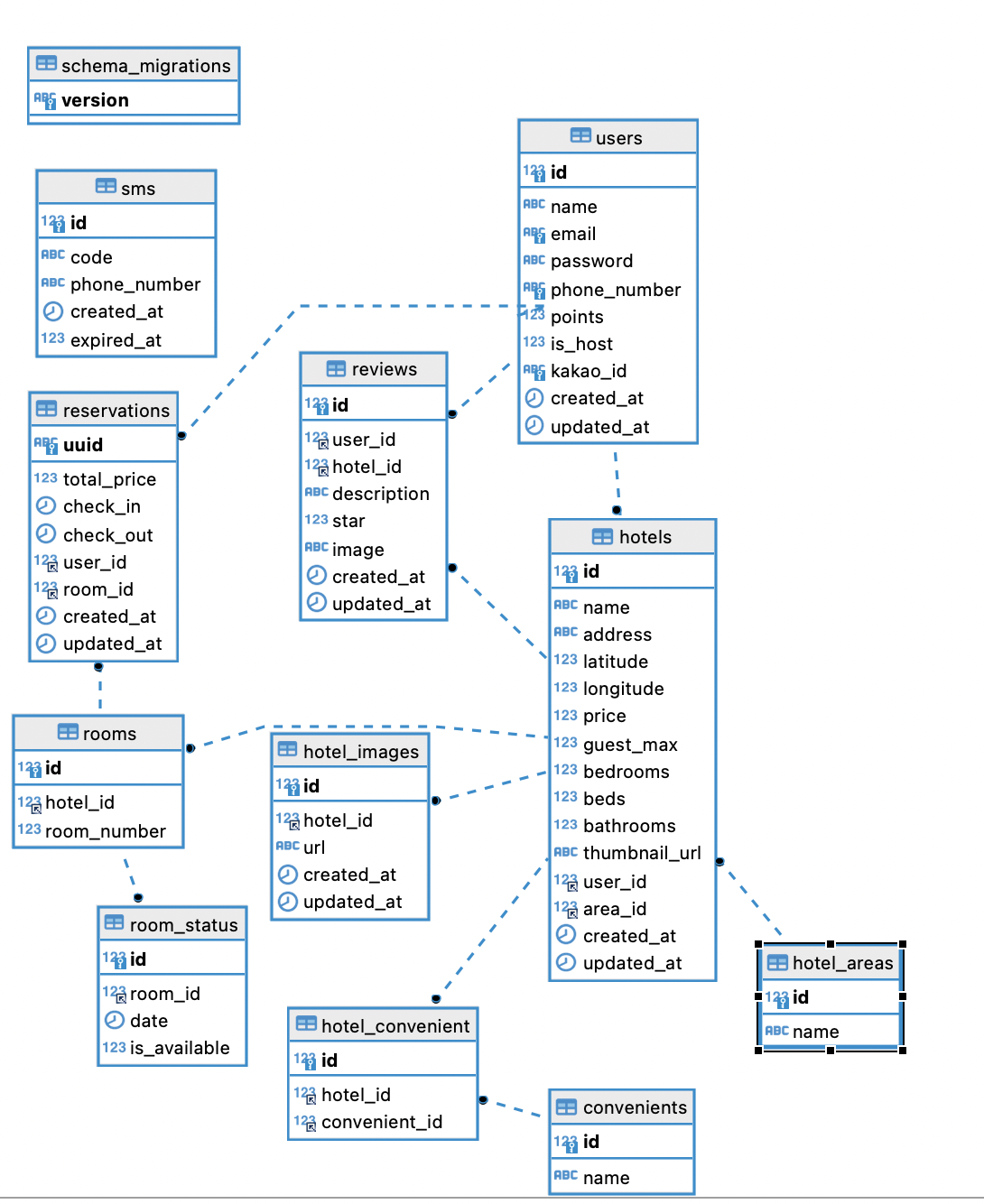
FrontEnd 3명, Backend 2명으로 구성.ERD
메인 페이지
1-1 호텔 목록 조회 기능
호텔 목록 조회 기능을 구현 하기 위해서 먼저 Dummy Data 가 필요하다고 생각하여
Dummy Data 를 넣기 위한 자동화 스크립트를 Node.js 로 작성하였다.
자동화 스크립트는 우선 hotels 라는 테이블에 대해서만 Dummy Data 를 30개 만 넣어놓고
호텔 목록 조회 기능을 구현 하였다.
사실 조회기능 자체는 Raw Query 로 특정 테이블에서 가져오고 싶은 필드에 대해서 SELECT
쿼리를 해주면 됬기 때문에 큰 Blocker 없이 진행할 수 있었다.
그리고 조회 기능 구현 할 때 class 를 사용해서 객체지향적으로 코드를 작성하려고
다음과 같은 클래스를 선언하여 작업하였다.
class HotelsQueryBuilder extends QueryBuilder {
constructor(tableNmae, columns, filters) {
super(tableName, columns)
...
}
build() {
const rawQueries = [
// build rawQueries
]
return rawQueries
}
}지금 시점에서 클래스를 사용하는 이유에 대해서 정리를 해보면
- 코드의 재사용성을 높이기 위함 -> 따라서 유지보수 하기 용이한 코드 작성.
- 각 기능별로 클래스를 나누어서 코드의 복잡도를 낮출 수 있다 -> 코드 가독성 UP
정도로 정리가 되는데
이번 프로젝트를 진행하면서 위에 언급한 클래스에 대한 이점을 활용하지 못한 것 같아
객체지향 프로그래밍에 대한 이해를 좀 더 높여야 할 것 같고
자바스크립트의 클래스와 상속에 대한 이해가 더 필요하다고 느꼇다.
1-2 호텔 필터링 기능
호텔 필터링 기능에 대해서는 다음과 같은 항목에 대해서 필터링이 가능 하도록 구현 하였다
지역, 가격, 옵션 (침대, 침실, 욕실), 편의시설
호텔 필터링 기능에서 구현에 어려웠었던 점은 편의시설에 대한 부분이었다.
Query String 으로 클라이언트로부터 입력값을 받으면 일치하는 편의시설에 대해서
포함하는 값들을 보여주는게 중요하다고 판단하였다.
처음에는 이 부분에 해당하는 로직을 SQL Raw Query 로 구현하려다가 작업이 너무 늘어지게 되어서
Service Layer 에서 비지니스 로직으로 구현을 하는 방식으로 하였다.
구현 내용에 대해 잠시 기록을 남겨보면.
-
편의시설에 대해 Query String 으로 요청 값을 받는다.
http://localhost:3000/hotels?convenients=1&convenients=2&convenients=3
-
먼저 호텔 목록과 호텔의 편의시설에 대한 목록을 DB 로 부터 가져와 Service Layer 에서 합친다.
-
호텔 목록 과 편의시설의 호텔 아이디가 일치 하는 것에 대해서 Array.prototype.filter 를 이용해 필터링 작업을 거친다.
-
이렇게 하다보니 한 페이지당 보여줘야 하는 호텔의 갯수가 5개 로 정해져 있는데 Service Layer 에서 비즈니스 로직으로 필터링을 하다보니 한 페이지에 보여지는 호텔의 갯수가 적어지는 문제점이 있었고 따라서 5개를 채워주기 위하여 서비스 레이어에서 Hotels 라는 배열의 갯수가 5개가 될때까지 DB 에 쿼리를 여러번 날리는 구조가 되었다.
-
또한 페이지네이션을 구현하기위해 서버에서 offset 을 전역적으로 관리해야 하는 필요성이 생겼고 javascript 의 global 오브젝트에 접근하여 global.OFFSET 과 같이 변수값을 지속적으로 유지해야하는 필요성이 있었다.
이렇게 해서 일단 구현을 하기는 했지만 분명히 하나의 API 요청에 대해서 DB 에 여러번 쿼리를 날리게 되면 불필요한 작업인게 확실하기도 하고 실제 많은 유저들이 사용하는 웹서비스에서 적용한다고 했을 때
트래픽이 늘어남에 따라 기하급수적으로 DB 와 웹서버에 큰 부하가 생길 것이라고 판단했다.
결국에 추후에 SQL 문으로 구현을 하게 되어서 관련한 SQL 문은 다음과 같다.
HAVING JSON_LENGTH(JSON_EXTRACT(convenients, "$")) = 5먼저 hotels 와 convenients 테이블을 결합하고 convenients 에 대해서 JSON_ARRAYAGG 로
hotels.id 에 대해서 배열로 만들어 주었고 그 이후에 위와 같은 HAVING 절을 이용하여 편의시설에 대해서 갯수가 유저가 요청한 편의시설의 갯수와 같은 것에 대해서 가져올 수 있도록 구성하였다.
1-3 호텔 검색 기능
먼저 숙박에 대한 웹서비스를 기획할 때 중요한 점은 체크인 체크아웃 날짜에 맞춰서 검색하는 기능은
굉장히 필요한 기능이라고 판단하였다.
if (this.checkin && this.checkout) {
const availableDateTable = `
INNER JOIN
(SELECT DISTINCT r.hotel_id, rs.availableDate FROM rooms r
INNER JOIN
(SELECT
room_id, JSON_ARRAYAGG(date) availableDate
FROM room_status rs
WHERE date
BETWEEN "${this.checkin}" AND "${this.checkout}" AND is_available = true
GROUP BY rs.room_id
HAVING JSON_LENGTH(JSON_EXTRACT(availableDate, "$")) = DATEDIFF("${this.checkout}", "${this.checkin}") + 1)
AS rs ON r.id = rs.room_id)
AS AD
ON h.id = ad.hotel_id`
joinTables.push(availableDateTable)
}이 로직도 먼저 체크인 체크아웃 날짜에 대해서 조건문을 구성하여 가져오고 예약 가능한 날짜에 대하여
HAVING 절에서 JSON_LENGTH 함수를 이용해서 date 의 배열 갯수와
유저의 checkin, checkout 기간동안의 일수를 DATEDIFF 함수로 가져오는데 date 의 갯수가 동일한 부분에 대해서만 가져오도록 한다.
호텔 상세 정보 페이지
1-1 호텔 상세 정보 조회 기능
호텔 상세 정보를 조회하는 기능에 대해서는 각 컬렴별로 테이블에서 조회해서 가져오면
되기때문에 큰 어려움은 없었다.
1-2 호텔 예약 가능한 날짜 조회 기능
이 부분에 대해서는 어려웠던 부분 중 하나가
호텔에 예약 가능한 날짜에 대한 정보를 어떤식으로 넣어야 할 지 고민이 있었고.
결론적으로 기획 의도 상 하나의 호텔에 5개의 객실이 있는것으로 합의를 하였고
5개의 객실중 각 객실마다 365일에 대하여 room_status 란 테이블에 date 데이터 형식으로
넣는 방식으로 구현하였다.
따라서 이렇게 하다 보니 room_status 란 테이블의 총 데이터의 갯수만
54750 개가 되어버려서 사실 이보다 더 나은 접근방식이 분명 있을거라고 생각하고 있었지만
Agile 프로세스에 입각하여 기능구현에 초점을 맞추다 보니 데이터가 불필요하게 많이 들어가는 방향으로 구현을 하게 되었다.

1-3 호텔 편의 시설 조회 기능
호텔 편의시설 조회기능에 대해서는 호텔 목록에서 편의시설을 조회 할 때 사용한
쿼리문을 이용하여 상세 페이지에서도 보여줄 수 있었다.
AWS EC2 서버 배포 With Docker
AWS 를 이용하여 Docker 에 배포 할 떄 알아두면 좋은 점에 대해서 정리해보면
Docker image 를 빌드할때 기본적으로 Docker 가 설치되어있는 Host OS 의 CPU Architecture 기반으로 Docker image 를 생성하는 듯 하였다.
무슨 말이냐면
애플의 CPU 인 M1 즉, Appli silicon 은 arm64 기반 Architecture 이고
AWS 의 EC2 Ubuntu 의 CPU 는 amd64 기반 Architecture 이다.
따라서 나의 로컬 맥북으로 Docker image 를 빌드하면 Docker container 를 띄울 때
arm64 기반의 CPU 에서만 실행이 가능하다.
그런 이유로 Ubuntu 에서 Docker container 를 실행하는 것이 불가능 했는데.
이에 대한 해결 방법은
docker image 빌드 할 때 --platform 옵션을 주어 호환 가능한 Architecture 를 지정할 수가 있고 Ubuntu 의 경우 다음과 같이 linux/amd64 로 지정해주면 된다.
docker buildx build --platform linux/amd64 -t jayhanjaelee/hyggesil:ubuntu .
DB Dummy Data Automated Scripts
프로젝트를 시작하기 전 부터 어떤 웹서비스를 기획 할 때 해당하는 기능이 유저에게 적절하게 표현 될 수 있는지를 파악하기 위하여 DB Dummy Data 를 준비하는건 아주 중요한 작업이라고 판단하였다.
따라서 1차 프로젝트에 이어서 2차 프로젝트에서 또한 DB Dummy Data 를 넣는데에 자동화 할 수 있는 Script 를 Node.js 로 작성하였다.
스크립트의 동작 원리는 다음과 같았다.
- csv 파일을 읽는다.
- csv 을 분석하여 실제 DB 의 테이블명과 column, values 를 가져온다.
- row 에 해당하는 값을 가져와 배열로 만들고
- rows 의 갯수만큼 반복문을 실행하여 DB 에 INSERT.
추가적으로 이미지 업로드가 필요한 hotel_images 테이블에 대해서는
S3 에 업로드 하는 과정이 필요했다.
DB Dummy Data Automated Script
부족한 부분
프로젝트 진행간 부족한 부분을 정리해보면
-
논리적인 사고의 부재
논리적인 사고 능력이 부족하다보니 SQL 쿼리문 작성, 서버 비즈니스 로직 작성, 유닛테스트 작성,
자동화 스크립트 작성시 작업이 지체되었던 부분도 논리적인 사고가 부족해서 계속 콘솔 로그를 활용하면서 작업하다보니 업무 효율이 안나오게 되었다.
논리력에 대한 부분은 알고리즘 문제를 더 자주 접하고 풀어보면서 향상을 시키는 방향으로 가면 될 것 같다. -
프론트엔드적 사고의 부재
프론트엔드에 대한 이해도가 낮다보니 커뮤니케이션 간에 서로의 Context 를 이해하는데 불필요하게 시간이 지체되는 경우도 있었다. 이부분은 React, HTML, CSS 에 대해 학습 해 보면서 개선해 나가면 될 것 같다.
