하둡(Hadoop)이란 무엇인가?
하둡은 고가용성 분산형 객체 지향적 플랫폼(High Availability Distributed Object Oriented Platform)의 약자로 오픈소스, Java 기반의 빅데이터 어플리케이션용 데이터 처리와 스토리지를 관리하는 빅데이터 분산 플랫폼이다. 컴퓨터 여러대를 연결하여 하나의 클러스터를 구성하고 클러스터 내 여러 노드에 걸쳐 하둡 빅데이터와 분석 작업을 분배하며, 그 과정에서 작업을 병렬식으로 실행한다.
하둡의 구성요소
하둡은 크게 4대의 주요 모듈로 구성됩니다.
- Hadoop Common
- 하둡의 다른 모듈을 지원하기 위한 공통 컴포넌트 모듈
- Hadoop HDFS
- 분산 저장을 처리하기 위한 모듈
- 여러개의 서버(노드)를 하나의 서버(클러스터)처럼 묶어서 데이터를 저장
- Hadoop YARN
- 병렬처리를 위한 클러스터 자원관리 및 스케줄링 담당
- Hadoop MapReduce
- 분산되어 저장된 데이터를 병렬 처리할 수 있게 해주는 분산 처리 모듈
하둡의 구조 v1
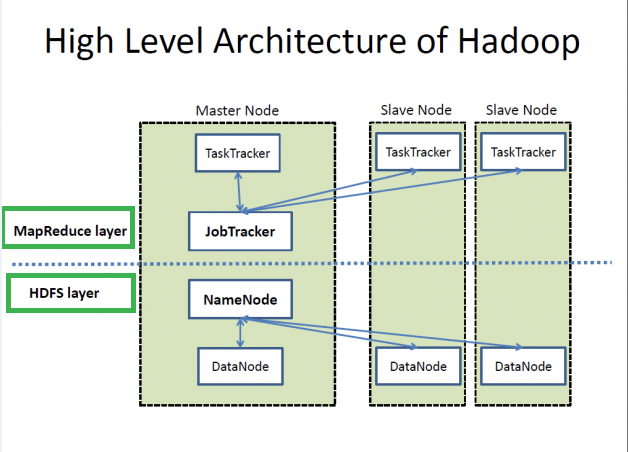
Hadoop에서 수행하는 역할은 크게 HDFS에 파일을 저장하는 역할과 데이터를 처리하는 역할로 나누어진다. 이에 맞게 Hadoop은 2개의 Layer로 분류할 수 있다.
MapReduce Layer
MapReduce를 사용하여 병렬처리를 수행하기 위한 Layer로 Master-Slave 아키텍쳐로 구현되었다. Job 제출, Job 초기화, 태스크 할당, 진행 상황 갱신, 잡 완료 연관 활동을 포함하여 Job Tracker에 의해 관리되고, Task Tracker에 의해 실행된다.
HDFS Layer
분산 데이터 저장 환경을 제공하는 Layer로 이 또한 Master-Slave 아키텍쳐로 구현되었다. HDFS 마스터를 네임 노드(NameNode)라고 하고 슬레이브를 데이터 노드(DataNode)라고 한다.
NameNode는 파일 시스템 이름공간을 관리하고 클라이언트의 파일 접근을 관리한다. 입력 데이터는 블록들로 나뉘며 어느 블록이 어떤 데이터 노드에 저장될 것인지를 알려준다.
DataNode는 분할된 데이터셋 복제본을 저장하고, 요청에 대해 데이터를 제공해주며 블록 생성과 삭제도 수행한다.
HDFS의 내부적인 메커니즘에 의해서 파일은 하나 이상의 블록으로 나뉘고, 이 블록들은 데이터 노드 그룹에 저장된다. 복제 계수를 3으로 하는 일반적인 환경에서, HDFS 정책은 첫 번째 복사본은 해당 노드에, 두 번째 복사본은 같은 랙의 다른 노드에, 세번째 복사본은 다른 랙에 있는 다른 노드에 저장한다. HDFS가 큰 파일을 지원하도록 디자인되었기 때문에 HDFS 블록 크기는 64MB로 정의된다. 필요에 따라 이 값을 증가시킬 수 있다.
- MapReduce Layer
Job Tracker: MapReduce Layer의 마스터 노드이며 Task Tracker들의 Job과 Resource를 관리한다. 실제 데이터에 가까운 Task Tracker에 스케줄링하려고 시도하여 해당 기반 블록에 대한 데이터 노드와 같은 곳에서 잡을 수행하게 된다.Task Tracker: 각 컴퓨터에 배포되는 슬레이브다. Job Tracker로부터 할당 받은 작업을 Map-Reduce하여 결과 반환한다.- HDFS Layer
NameNode: 디렉토리, 파일을 관리하고 파일을 Block으로 나누어 Data Node에 전달한다.DataNode: 클라이언트로부터 전달받은 파일의 읽기/쓰기 등을 실제로 수행Secondary NameNode: 주기적으로 체크포인트를 수행하고 네임 노드가 고장 났을 때, 대체하는 역할을 수행한다.
Hadoop의 구조 v2
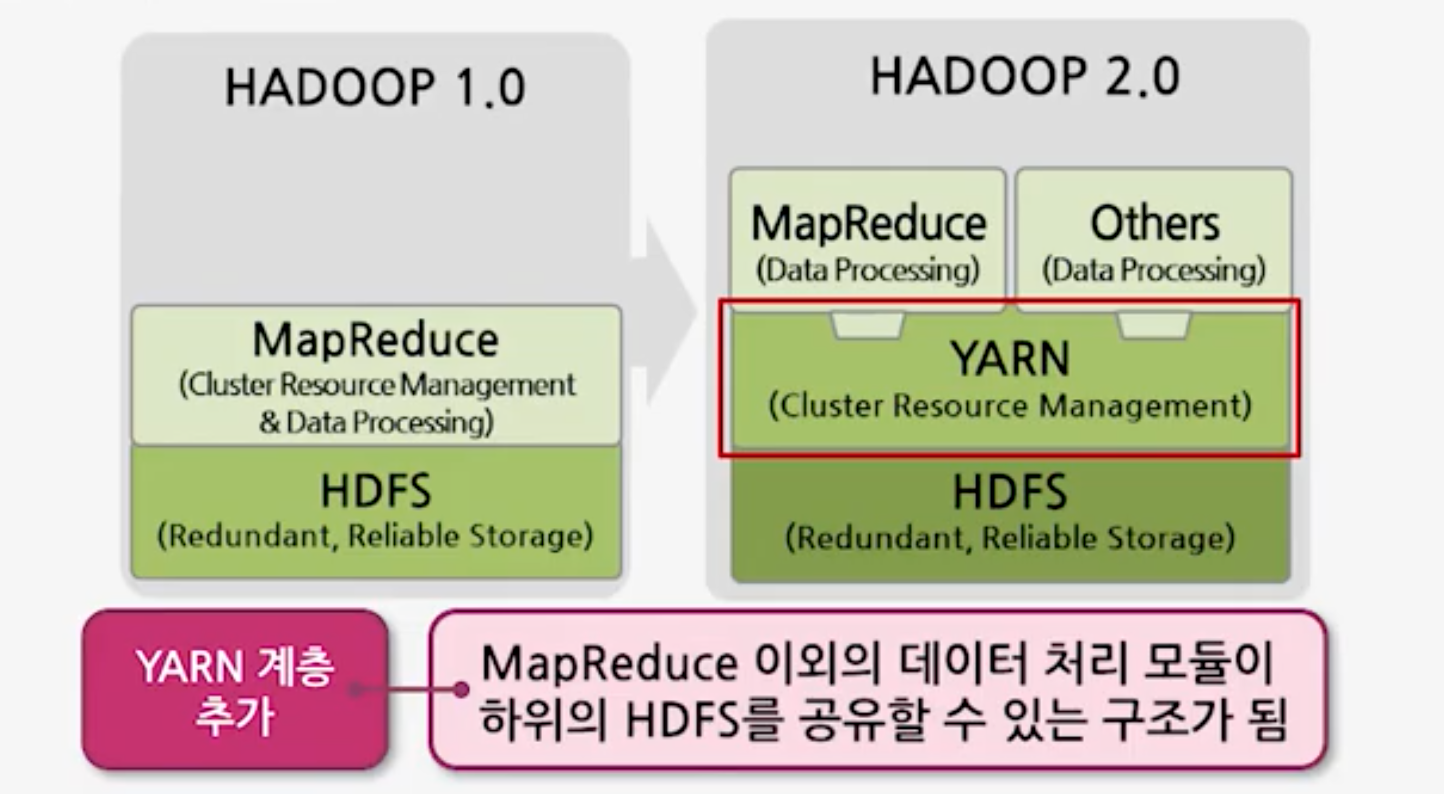
기존에 HDFS Layer와 MapReduce Layer로 구성되었던 Hadoop은 2.X.X 버전으로 넘어오면서 기존 Job Tracker의 병목현상을 제거하기 위해 HDFS Layer와 MapReduce Layer 사이에 YARN(yet another resource negotiator)계층을 추가하였다. 이는 기존에 MapReduce Layer에서 자원 관리 및 데이터 처리를 모두 진행하던 것을 MapReduce와 YARN으로 역할을 분리하여 MapReduce가 데이터 처리를, YARN이 Resource 관리를 담당하게 하였다.
YARN
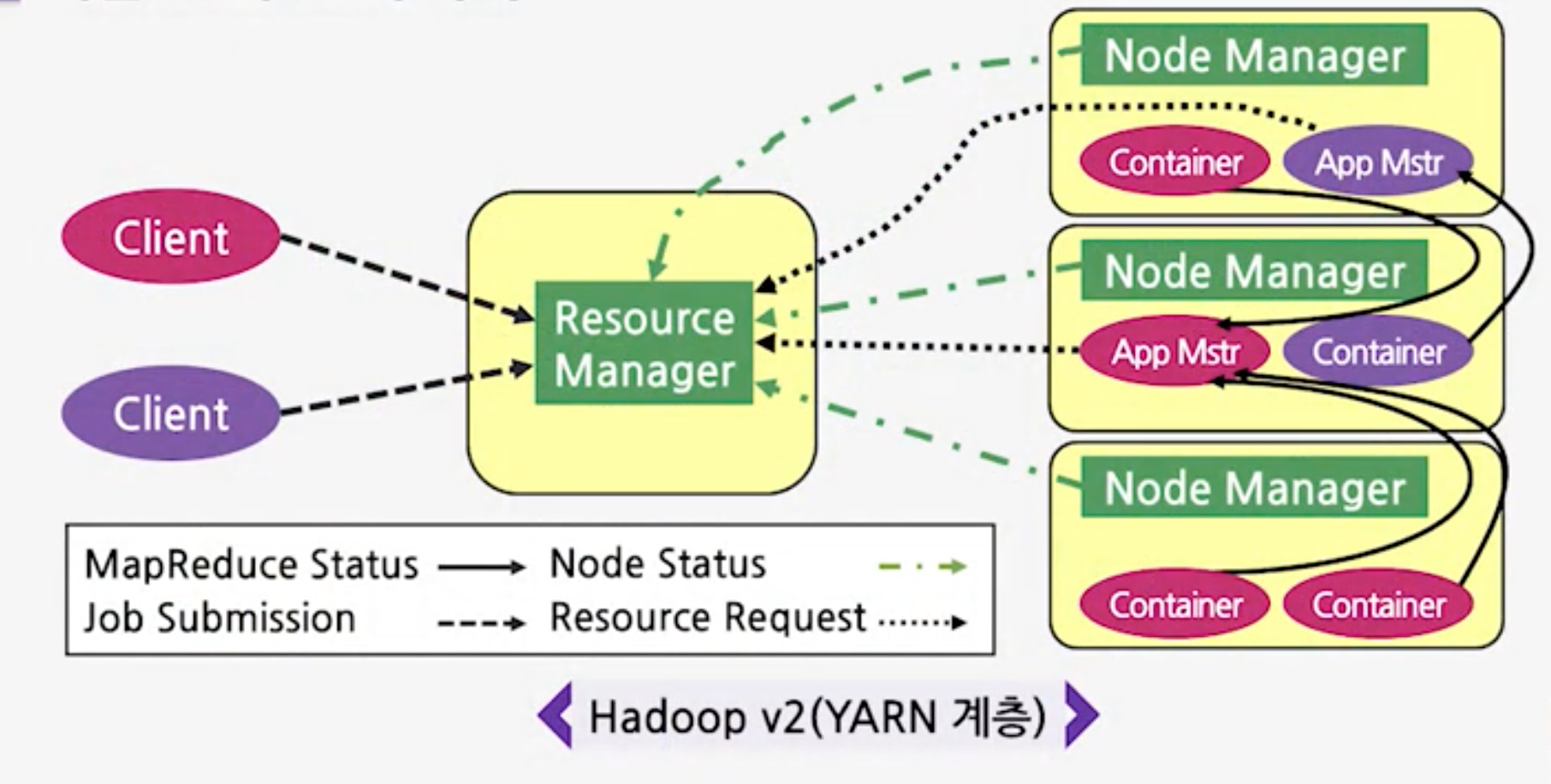
MapReduce 수행 과정
- 클라이언트 Application이 Job Tracker에 Job을 제출한다.
- 입력이 클러스터 상에 분산된다.
- Job Tracker가 처리될 맵과 리듀서의 수를 계산하여 Task Tracker에 잡을 할당한다.
- Task Tracker는 리소스를 Local에 복사하고 데이터에 대해 수행할 맵과 리듀스를 위해 JVM을 시작한다.
- Task Tracker는 Job Tracker에게 주기적으로 갱신 메시지(heartbeat)를 보낸다
하트비트(HeartBeat): JobID, Status, Resource 사용량을 갱신하는데 도움을 주는
References
https://mangkyu.tistory.com/129
https://gachonyws.github.io/hadoop/hadoop3/
http://a4academics.com/tutorials/83-hadoop/835-hadoop-architecture
