Index란 무엇인가?
칼럼의 값과 해당 레코드가 저장된 주소를 Key-Value 쌍의 인덱스로 만들어두어 해당 테이블에 대한 탐색을 빠르게 해주는 자료 구조이다.
Index는 항상 정렬된 상태를 유지하기 때문에 원하는 값을 탐색하는 것은 빠르지만 새로운 값의 추가, 삭제, 수정이 발생할 경우에는 성능을 오히려 저하시킬 수 있다.
Index의 자료구조
인덱스는 크게 2가지 자료구조를 채택하고 있다.
b+-tree
일반적으로 인덱스에 사용되는 자료구조이다. 칼럼의 값을 변형하지 않고, 원래의 값을 이용해 트리구조에 저장하여 인덱싱하는 알고리즘이다.
MySQL의 DB engine인 InnoDB는 B+tree로 이루어져 있으며 이는 B-Tree의 확장된 개념이다.
b-tree
시간복잡도: O(logN)
어떤 값에 대해서도 같은 시간(O(logN))에 결과를 얻을 수 있다.
B-Tree는 이진트리와 유사하지만 하나의 노드당 2개 이상의 자식노드를 허용한다. B-Tree는 균형트리이며 이는 루트로부터 리프까지의 거리가 일정한 트리 구조임을 의미한다.
장점으로는 ‘균일성’을 꼽을 수 있는데 이는 ‘어떤 값에 대해서도 같은 시간(O(logN))에 결과를 얻을 수 있다’는 것을 의미한다. 따라서 데이터 양이 커질 수록 성능이 향상된다.
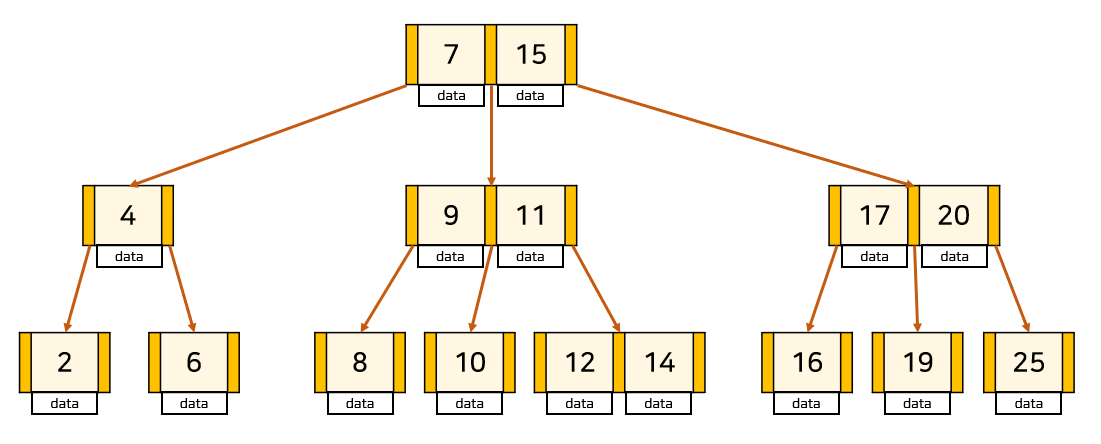
b+tree
B+Tree는 B-Tree의 확장 개념으로, B-Tree의 경우 internal 또는 branch 노드에 key와 data를 담을 수 있다. 하지만 B+tree의 경우 브랜치 노드에 key만 담아두고 data를 담지 않는다. 오직 leaf node에만 key와 data를 저장하고 리프 노드끼리 Linked List로 이루어져 있다.
이를 통해 얻을 수 있는 장점은 다음과 같다.
- 메모리 성능 확보 - 리프 노드를 제외하고 데이터를 담아두지 않기 때문에 메모리를 더 확보함으로써 더 많은 key들을 수용할 수 있다.
- select * 성능 향상 - 해당 테이블의 모든 데이터를 조회할 때, b-tree의 경우 모든 노드를 조회해야 하지만 b+tree는 리프 노드에 데이터가 모두 있기 때문에 한 번의 선형탐색으로 모든 데이터를 조회할 수 있다.
- 구간 탐색 성능 향상 - Link List로 이루어져 있기 때문에 최소값만 찾으면 다음 좌표들로 이동하며 탐색할 수 있다.

hash table
시간복잡도: O(1) ~ O(N)
보편적으로는 해시함수에 의해 고유 index를 가지게 되어 O(1)의 시간복잡도를 가지지만 Hash값 충돌이 발생할 경우 이후 연결된 리스트들 까지 검색해야 하므로 최대 O(N)까지 증가할 수 있다.
해시 테이블은 (Key, Value)로 데이터를 저장하는 자료구조 중 하나로 빠르게 데이터를 검색할 수 있는 자료구조. Key값을 해시 함수를 통과시켜 얻은 값(고유 인덱스)을 인덱스로 데이터를 저장하기 때문에 O(1)의 시간복잡도를 가진다.
예를 들어 John Smith를 저장 할 때, bucket[h("John Smith")]과 같이 Key값을 Hash함수를 통과 시킨뒤 바로 bucket의 인덱스로 사용한다.
따라서 해시 테이블을 사용하여 데이터를 저장하면 Key값으로 데이터를 찾을 때 해시 함수 수행 한번으로 매우 빠르게 데이터를 저장/삭제/조회할 수 있다.하지만 값을 변형해서 인덱싱 하므로 값의 일부만으로 검색하고자 할 때, 해시 인덱스를 하용할 수 없다.
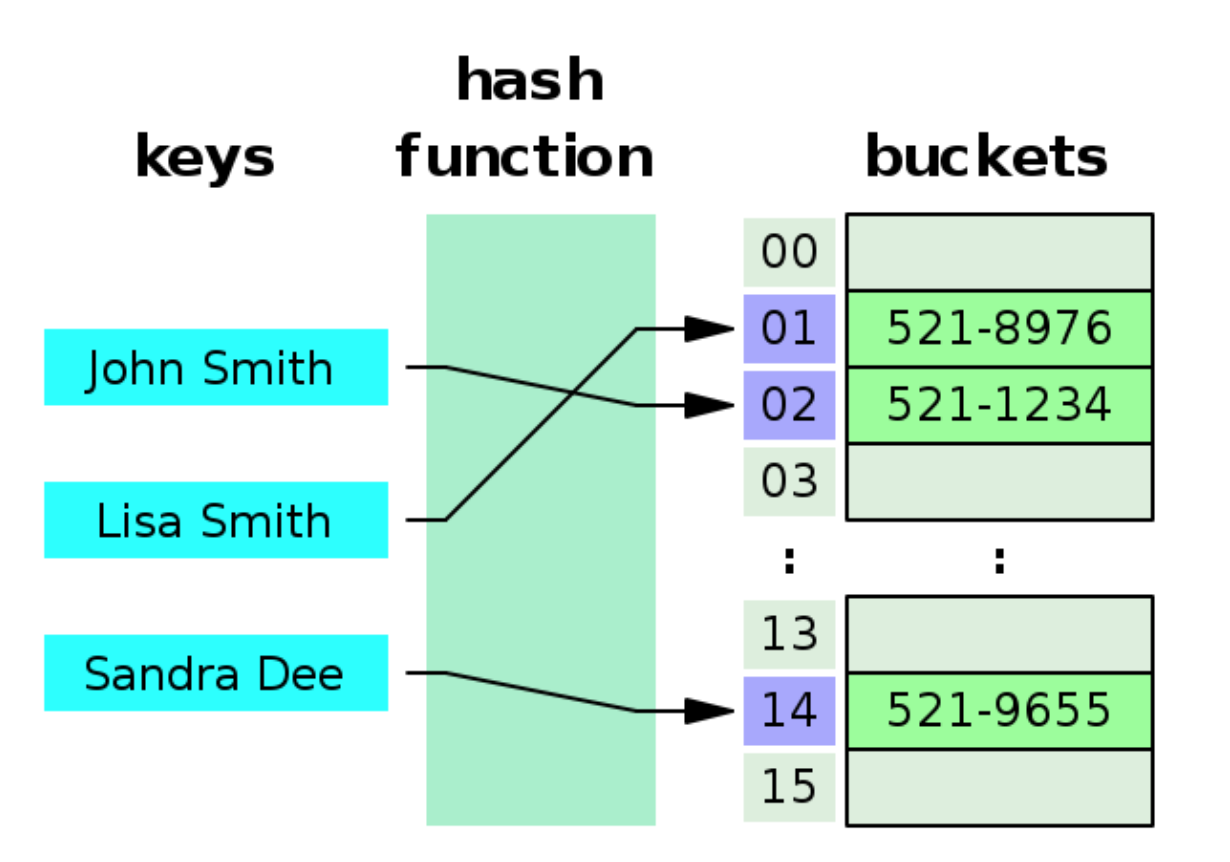
대부분의 database에서 b+-tree를 채택하는 이유
hash table의 경우 단일 데이터에 접근할 때의 시간복잡도가 O(1)이고 b+-tree의 경우 O(logN)의 시간 복잡도를 가진다. 하지만 hash table의 경우 부등호 연산(<>)이 포함되어 있을 경우 모든 데이터를 순회해야 하여 O(N)의 시간복잡도를 가지는 반면 b+-tree의 경우 똑같이 O(logN)의 시간복잡도를 가지기 때문에 일반적으로 데이터베이스에서는 b+-tree를 인덱스의 자료구조로 사용한다.
Index의 종류
Clustered Index (=Primary Index)
- PK 값이 비슷한 레코드끼리 묶어서 저장하는 것을 의미한다.
- InnoDB에서는 기본적으로 PK값을 이용해 데이터를 정렬한다.
- 테이블당 하나만 가질 수 있다. (PK 값에 대해서만 적용할 수 있기 때문)
- 프라이머리 키 값에 의해 레코드의 저장 위치가 결정
- Insert시 data가 정렬되고 index는 data block의 첫 번째 레코드의 주소값을 갖게 된다.
index가 곧 바로 data block에 접근해서 Secondary Index보다 동작이 빠른 편이다. - data가 정렬되어 저장되므로, Secondary Index에 비해 범위로 질의를 하는 것에 유리하다. 빈번한 I/O가 덜 발생할 것이기 때문이다.
Secondary Index
- Pimary Key 이외에 필요한 정렬 기준이 있을 경우 사용한다.
- 테이블당 여러 개 가질 수 있다.
- data record가 정렬되어 있지 않다.
- index가 data record의 모든 주소값을 가지고 있어야 한다.
- 데이
Composite Index
두개 이상의 Atrribute를 합쳐서 index로 설정하는 것을 의미한다. (attribute1, attribute2)를 Composite Index로 설정하였을 때, attribute1으로 정렬후 동일 attribute1에 대해서 attribute2로 정렬한다. 따라서 attribute1로 조회 시에는 성능이 좋아지지만 attribute2로만 조회 시에는 index 성능이 좋지 않다.
Index 적용 시 고려사항
Reference
https://zorba91.tistory.com/293
https://bcho.tistory.com/1072
https://mangkyu.tistory.com/102
