
챗봇을 쥐어주지 않으면 언어능력이 급격히 하락하는 키보드 파이터인 나는, 작년 상반기부터 llm을 학습시켜 전투력을 극대화한 말싸움 챗봇이라는 것(?)을 만들고 싶어했다.
물론 작년에는 이런저런 일들로 좀 바빴다. 하지만 올해부터는 절대 야근하지 말자는 나와의 약속을 아직까지는 굳건히 지키고 있는 중이고, 사이드 프로젝트로 무언가를 개발할 시간이 좀 나기 시작했다.
”절대 지지 않는“ 말싸움 챗봇을 개발하기 위해 뉴스 스트리밍과 각종 온라인 상 논란 글, 혐오 글, 어그로성 글 등 인터넷 밑바닥을 크롤링해서 읽어보았다. 이렇게 끊임없이 AI와 나 자신을 타락시키다가, 어느 순간, 내가 AI가 되면 굳이 안 싸워도 되겠구나..! 라는 결론에 이르게 되었다.
그렇게, 나의 뇌를 AI에 이식하기 위해 이 때까지의 메신저 내용과 sns 글들을 열람했다. 그런데, 생각보다, 훨씬 하기 싫다. 그리고 가장 괴로운 것은 귀찮은 수집과 정제 작업이 아니라, 내 글들을 직면하는 순간이었다.
근데.. 인터넷 밑바닥을 보는 것이 괴로울까? 내 흑역사의 밑바닥을 보는 것이 괴로울까?
비교적 최근에 쓰던 말투랑 워딩을 학습시키고 싶어서, 수집 기간은 2년으로 잡았다. 수집 범위는 금단의 공간(팀즈/메일은 공적인 어조가 너무 강해서 제외, 블로그는 독백이라 제외)
챗봇 학습 용도로 카카오톡 대화 내역 일부를 사용하겠다고 지인들에게 미리 허락을 받았다. (희생양들이다.)
1. Intro
✅ 데이터 수집 기간: 2023년 6월 - 2025년 8월
✅ 수집 범위: 카카오톡 백업 파일
✅ 데이터 변환: 텍스트/csv 파일을 .json 확장자로 변환
✅ 사용 언어: Python 3.12
✅ 사용 LLM: Solar 10.7B
✔ 허깅페이스 링크: SOLAR-10.7B-v1.0
2. 데이터 수집 및 parsing
Step1. 가상 환경을 설정한다
이번 편에서는 작성하지 않을 거지만, 2025년 8월 기준 3.13을 사용하니 학습 모델이 찌그락빠그락거리기 시작했다. (복선이라고 해야 하나..)
결국에는 Python 3.11를 재설치 한 후 가상환경을 설정했다. C드라이브 내 작업용 폴더를 하나 만들고, 가상경로 설정, 필요한 패키지(굳이 가상환경 경로와 일치하지 않아도 되지만), LLM을 동일 경로에 설치한다.
아래와 같은 명령어를 Powershell에 입력한다.
(+) 훈련용 데이터셋도 동일 경로에 저장한다.
cd C:\작업용 폴더명
py -3.11 -m venv .venv
Set-ExecutionPolicy -ExecutionPolicy RemoteSigned -Scope Process
.venv\Scripts\Activate.ps1
python.exe -m pip install --upgrade pip
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
pip install datasets peft bitsandbytes accelerate transformers torch pandas tqdm huggingface_hub
huggingface-cli download Upstage/SOLAR-10.7B-Instruct-v1.0 --local-dir ./Upstage/SOLAR-10.7B-Instruct-v1.0
Python으로 가서 패키지를 불러온다.
import os
import re
import json
from tqdm.auto import tqdm
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments, Trainer, BitsAndBytesConfig
from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training, PeftModel
from datasets import load_dataset
import unicodedata
Step2. 판도라의 상자를 열고, 불필요한 부분 제거
카카오톡 백업 파일을 받아본 적 있는가? 거의 귀여니 소설 수준으로 긴 텍파 몇 개가 압축되어 날라온다. 나는 이 .txt파일을 불러들인 다음에, 한 개의 파일로 합친 다음, 불필요한 부분은 제거해서, 발화 순서대로 나열을 하였다. 그리고 질문에 대한 답을 하는 챗봇인 만큼, 상대방의 말에 대한 나의 대답 패턴/대답 어조를 학습시키기 위해 대화를 쌍으로 묶는 작업을 거쳤다.
비속어, ㅋ, ㅎ, 의미없는 단어, 오타, 이상한 의성어 등은 굳이 정제하지 않았다. (욕설은 좀 정제할걸 그랬다.)
카카오톡 백업 파일을 열면, 다음과 같이 맨 위에 데이터 저장 일자가 기재되어 있고, 공백 아래는 대화를 주고받은 일자가 기재되어 있다. 다 필요 없으니 삭제한다.
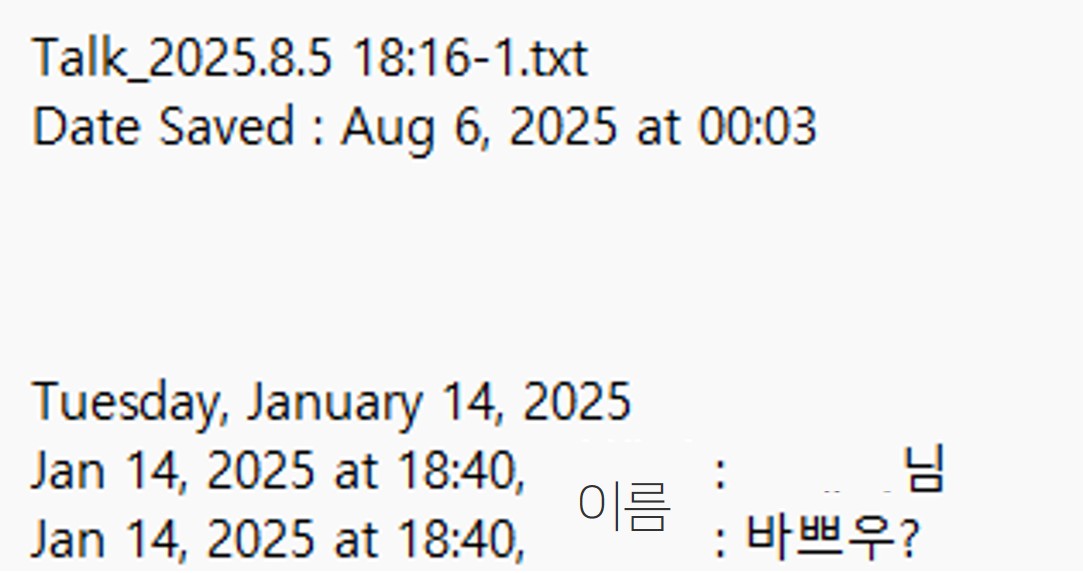
다음으로, 대화 패턴을 보면,
월-일-연 at 시-분, 보낸사람 이름 : 메시지 내용
규칙이 있다는 점을 파악할 수 있다. 보낸 순서 - 보낸 사람 - 메시지 내용을 제외하고는 굳이 필요한 내용은 아니기에, 정규식을 통해 필요없는 정보들은 제거한다.
# 1.대화 패턴 정리: 월-일-연 at 시-분, 보낸사람 이름 : 메시지 내용
korean_chat_pattern = r"^\d{4}\.\s*\d{1,2}\.\s*\d{1,2}\.\s*(?:오전|오후)\s*\d{1,2}:\d{2},\s*(.*?)\s*:\s*(.*)$"
chat_re = re.compile(korean_chat_pattern)
# 2.날짜 헤더 정규식
date_re = re.compile(r"^\d{4}년\s*\d{1,2}월\s*\d{1,2}일\s*(?:월|화|수|목|금|토|일)요일$")
# 3.불필요한 저장 라인 (2번) 삭제
date_saved_re = re.compile(r"^Date Saved\s*:\s*.*$")
참고) 데이터 정규식에 주로 쓰이는 명령어
- re.compile(): 정규식 패턴을 미리 컴파일해서 정규식 객체로 만듦. 같은 패턴을 여러 번 사용할 때 효율적이며, 컴파일된 객체는 match(), search(), findall() 등의 메서드를 가짐.
- re.match(): 문자열의 시작 부분부터 패턴이 일치하는지 확인
- re.search(): 문자열 전체에서 패턴이 일치하는 첫 번째 부분을 찾음
- re.findall(): 문자열 전체에서 패턴이 일치하는 모든 부분을 리스트로 반환
- re.sub(): 패턴이 일치하는 부분을 다른 문자열로 대체
Step3. 학습하기 적절한 형태로 정제
첫 번째로 해야 할 것은, 발화 덩어리를 만드는 것이다. 모든 대화 라인에서 보낸 사람 - 받는 사람을 구분한 다음에, 받는 사람이 답장 하기 전에 보낸 사람이 연속적으로 보낸 말도 하나의 덩어리로 간주하고 묶어 준다.
이게 무슨 말이냐..? 하면
나: 아
나: 배고파
나: 뭐먹지?
친구: 밥
이라는 대화가 있다고 하면,
나: 아, 배고파, 뭐먹지? > 1개의 발화덩어리로 간주
친구: 밥
으로 만드는 과정인 것이다.
# 덩어리 만들기
# 채팅 내용을 한 줄씩 살펴보고 덩어리(turn)를 만들 건데
turns = []
buffer = []
last_label = None
for line in all_lines:
# 날짜나 영문 날짜 표시는 무시
if date_saved_re.match(line) or english_date_header_re.match(line):
if debug:
print(f"[DEBUG] 건너뛰는 줄: {line.strip()}")
continue
m = chat_re.match(line)
if m:
# 이름과 메시지를 찾는다
name, msg = None, None
if m.groups()[0] is not None:
name = m.groups()[0]
msg = m.groups()[1]
elif m.groups()[2] is not None:
name = m.groups()[2]
msg = m.groups()[3]
if not name or not msg:
continue
# 내 이름이면 'Me', 아니면 'Friend'
label = 'Me' if unicodedata.normalize('NFKC', name).strip() == my_name else 'Friend'
# 화자가 바뀌면 이전 메시지를 저장
if buffer and label != last_label:
turns.append({'speaker': last_label, 'message': '\n'.join(buffer).strip()})
buffer = []
buffer.append(msg)
last_label = label
else:
# 채팅 아닌 줄은 이어서 적기
if buffer and not date_re.match(line) and line.strip():
buffer.append(line.strip())
# 덩어리 저장
if buffer:
turns.append({'speaker': last_label, 'message': '\n'.join(buffer).strip()})
두 번째로 해야 할 것은, 덩어리(turn)을 가지고, 챗봇 학습에 사용할 질문 - 답변 쌍(pair) 형태로 데이터를 정제하는 것이다. 여기서 핵심적인 것은, 나의 '답변' 패턴을 학습시켜야 한다는 것이기에, 몇 가지 스텝을 통해 데이터를 정제하였다.
- 덩어리를 확인하며, 챗봇이 학습할 대화 쌍 형태를 찾아낸다
예) 친구: 아 짜증나 / 나: 왜
여기서는 나의 '답변'을 확인하는 것이 핵심이기에,
바로 앞 덩어리가 친구가 보낸 경우, - 내가 답을 한 경우의 pair를 골라낸다.
a는 나의 답변, q_base는 친구의 질문이라 가정하였다.
# 6) 'Friend'->'Me' 발화쌍 생성 (context_turns 적용)
training_pairs = []
for i in range(1, len(turns)):
if turns[i-1]['speaker']=='Friend' and turns[i]['speaker']=='Me':
q_base = turns[i-1]['message']
a = turns[i]['message']
# Context turns 추가
context_messages_list = []
start_index = max(0, i - 1 - context_turns)
for j in range(start_index, i - 1):
speaker_tag = "[친구]" if turns[j]['speaker'] == 'Friend' else "[나]"
context_messages_list.append(f"{speaker_tag}\n{turns[j]['message']}")
if context_messages_list:
q_context = "\n\n".join(context_messages_list) + "\n\n"
else:
q_context = ""
q = q_context + "[친구의 말]\n" + q_base
if q_base and a:
text = (
"<s>[INST] 다음은 친구와의 대화입니다. "
"친구의 마지막 말에 답변하세요.\n\n"
"[대화 흐름]\n" + q + " [/INST] " + a + " </s>"
)
training_pairs.append({'text': text})
print(f" 추출된 발화쌍 개수: {len(training_pairs)}")
- 대화 맥락 추가
대화는 일정한 맥락이 있기 때문에, 바로 전 시점의 n개의 대화 맥락을 반영할 수 있도록 Context 매개변수를 추가하였다. (특히 나는 메시지를 한 번의 뭉치로 보내지 않고, ㅋㅋ / 왜 / 아니 / 그건 아니지 등으로 끊어 보내는 습관이 있어서, 추가한 거다;)
수작업으로 몇 시점 전을 대화로 보아야 할 지 고민하다가, 최적화 할 수 있는 방법을 찾아봤지만 아쉽게도 없는 것 같다. 일단은 4개 정도로 결정했다.
pairs = parse_kakaotalk_chats(CHATS_DIR, MY_NAME, debug=True, context_turns=4) # 여기서 몇 번 턴의 대화까지 맥락에 고려할 것인지 넣어줘야 함.
if pairs:
create_finetuning_data(pairs, OUTPUT_FILE)
# Context turns 추가
context_messages_list = []
start_index = max(0, i - 1 - context_turns)
for j in range(start_index, i - 1):
speaker_tag = "[친구]" if turns[j]['speaker'] == 'Friend' else "[나]"
context_messages_list.append(f"{speaker_tag}\n{turns[j]['message']}")
if context_messages_list:
q_context = "\n\n".join(context_messages_list) + "\n\n"
else:
q_context = ""
q = q_context + "[친구의 말]\n" + q_base- LLM에 적합한 형식으로 데이터 저장
데이터 형태를 변환해서, 모든 pair를 LLM이 학습하기 용이한 형태로 저장한다. 아래 내용을 참고하면 된다. 제미나이 땡큐..
참고) 구조화된 문자열을 만드는 법
<s> (시퀀스 시작)
[INST] (지시 시작)
[모델에게 주어지는 지시사항]
* "다음은 친구와의 대화입니다. 친구의 마지막 말에 답변하세요.\n\n"
[대화 맥락]
* "[대화 흐름]\n"
* q (이전 대화 턴들 + 친구의 마지막 질문)
[/INST] (지시 끝)
[나의 답변]
* a
</s> (시퀀스 끝)
이 모든 과정을 거치고 나면, 하나의 pair로 묶인 대화들을 확인할 수 있다.

Step4. 결과값을 .json으로 저장
Json을 쓰는 이유는, 범용성이 높고 컴퓨터도 인간도 사용하고 이해하기 쉬운 언어이기 때문이라고 한다. 더 이상 알려 하면 다친다..
이렇게 대충 LLM이 학습할 수 있는 형태로 데이터를 정제하였다. 이 다음 편은 파싱보다 더 극악이었던 LLM 학습 과정에 대해 대략적으로 기재하겠다.
(비밀인데.. 챗지피티나 제미나이 채팅창 하나를 틀고 프롬프트로 조교시키는 게 쉽고 빠르다. 푸하하 🤣)
