
참고) 처리 방식에는 배치형(일괄적으로 정보 처리해서 답변)과 대화형(티키타카 형태로 맥락 고려해서 답변)이 있다. 놀랍게도 나는 대화형을 사용함.
배치형(Batch Inference)
• 한 번에 여러 입력을 넣어서 묶음 처리
• 속도·처리량에 유리
• 대화 맥락 없이 독립된 요청에 적합
• 예: 데이터셋 전체에 답변 생성, 문서 요약 일괄 처리
대화형(Interactive / Chat Inference)
• 입력과 출력을 순차적으로 주고받으며 진행
• 맥락 유지 가능
• 실시간 질의응답·대화형 애플리케이션에 적합
• 예: 챗봇, 고객 상담, 실시간 질문 응답
5. 학습부분 개선: 2단계 학습
충격과 공포의 챗봇의 대답의 원인을 찾은 결과, 카카오톡 대화를 과학습했기 때문이라는 답변을 GPT에게서 받았다. 그렇다.. 과학습을 어디서 했는지 뭘 어떻게 바꿔야 하는지 감도 못 잡은 채 시간만 보냈다.
고민한 결과, 다소 정제된 결과로 1차 학습을 한 다음에, 정제되지 않은 실제 데이터를 학습된 모델에 살짝 덧입혀 주기로 하였다.
그렇다면 정제된 데이터를 어디서 구할 것인지 한참 고민한 결과, 답을 찾았는데, 지피티에게 일단은 다양한 상황에서 나올 수 있는 대화들 중 질문 형식이나 내가 대답할 수 있는 멘트들을 달라고 했고, 그 멘트에 나는 답변을 달았다. 달다 보니 현타가 오고, 모든 대화 패턴이 거의 비슷해서 나의 어휘 능력이나 문장구사 능력에 대해 의심을 하게 되었다.
그 다음, 하기 코드를 통해 동일한 Solar 모델을 쓸 건데, 1단계 학습 후 -> 2단계 학습을 해줘!!! 라는 명령어를 작성하였다.
1단계 학습: 정제된 말을 학습시킨다
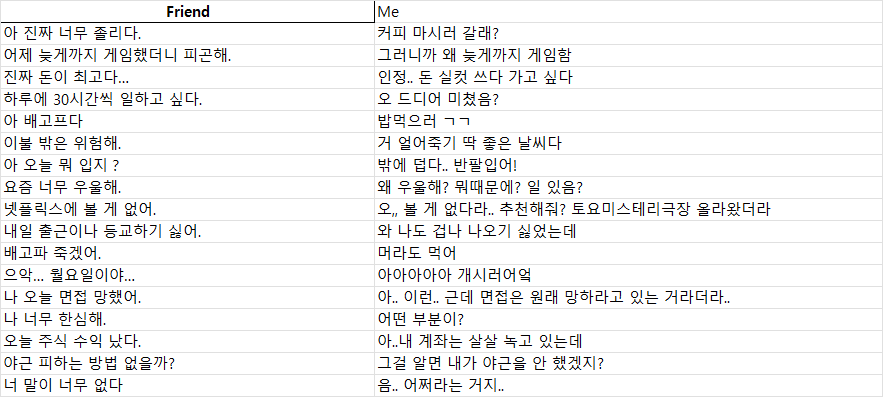
# 1단계 학습을 위한 전처리. 엑셀 데이터를 json 형식으로 전처리한다.
def prepare_data_from_excel(excel_path: str, out_path: str):
print(f"▶ STAGE1 데이터 전처리: {excel_path}")
if not os.path.exists(excel_path): raise FileNotFoundError(f"엑셀 없음: {excel_path}")
try:
df = pd.read_excel(excel_path) # openpyxl 필요
except Exception as e:
raise RuntimeError(f"엑셀 읽기 오류: {e}")
need = {"Friend", "Me"}
if not need.issubset(df.columns): raise RuntimeError(f"'Friend'/'Me' 열 필요. 현재: {list(df.columns)}")
def clean_txt(x):
if pd.isna(x): return None
s = str(x).strip()
if not s: return None
bad = ["이모티콘", "사진을 보냈습니다", "삭제된 메시지"]
if any(b in s for b in bad): return None
return s
n_in, n_out = len(df), 0
with open(out_path, "w", encoding="utf-8") as f:
for _, row in tqdm(df.iterrows(), total=len(df), desc="엑셀 → jsonl"):
u, a = clean_txt(row["Friend"]), clean_txt(row["Me"])
if u and a:
text = f"### User:\n{u}\n\n### Assistant:\n{a}"
f.write(json.dumps({"text": text}, ensure_ascii=False) + "\n")
n_out += 1
print(f"✅ {n_in}행 중 {n_out}쌍 변환 → {out_path}")
return out_path
# 두 가지 단계를 학습시킨다
def train_and_maybe_merge(excel_path, kakao_jsonl, stage1_dir, final_dir, do_merge, lr_stage1=5e-5, lr_stage2=2e-5, seed=42):
set_all_seeds(seed)
trainer_s1 = make_sft_trainer(model=model, tokenizer=tok, train_dataset=ds1, args=args_s1, peft_config=lora_cfg())
# 1단계: 엑셀 데이터로 학습
excel_jsonl = prepare_data_from_excel(excel_path, "/content/excel_data_formatted.jsonl")
ds1 = load_dataset("json", data_files=excel_jsonl, split="train")
print(f"STAGE1 샘플 수: {len(ds1)}")
model, tok = load_base_4bit_model_and_tokenizer() # 마찬가지로 4비트 양자모델_토크나이저 불러온다
args_s1 = mk_train_args("/content/results_stage1", lr_stage1)
# 모델+토크나이저를 설정한 다음에 모델을 학습할 준비를 한다
trainer_s1 = make_sft_trainer(model=model, tokenizer=tok,
# 학습에 사용할 데이터를 불러온다
train_dataset=ds1, args=args_s1, peft_config=lora_cfg()) # 학습 방법은 마찬가지로 QLoRa(핵심만 학습시킬 것이다)
trainer_s1.train()
os.makedirs(stage1_dir, exist_ok=True)
trainer_s1.model.save_pretrained(stage1_dir); tok.save_pretrained(stage1_dir)
print(f"STAGE 1 저장: {stage1_dir}") # 1단계를 저장한다
del trainer_s1, model
if torch.cuda.is_available(): torch.cuda.empty_cache()2단계: 1단계 학습 모델에 카카오톡 어투를 학습시켜 준다.
- 학습률(lr_stage2=2e-5) 더 작음 → 큰 변화를 주지 않고 미세 조정
- PEFT Config 없이(peft_config=None) 호출 → 기존 어댑터 구조 유지
- 원본 LoRA에 덧씌우는 방식 → “살짝 덧칠”하는 파인튜닝
# 2단계: 1단계에서 학습한 결과물을 가지고 카카오톡 데이터로 미세조정
if not os.path.exists(kakao_jsonl): raise FileNotFoundError(f"카카오톡 jsonl 없음: {kakao_jsonl}")
ds2 = load_dataset("json", data_files=kakao_jsonl, split="train")
print(f"STAGE2 샘플 수: {len(ds2)}")
model, _ = load_base_4bit_model_and_tokenizer()
# 여기서 1단계에서 학습한 모델을 불러온다
model = PeftModel.from_pretrained(model, stage1_dir) # 1단계 LoRA 로드
tok = AutoTokenizer.from_pretrained(stage1_dir)
args_s2 = mk_train_args("/content/results_final", lr_stage2)
# 동일하게 핵심만 학습시킨다
trainer_s2 = make_sft_trainer(model=model, tokenizer=tok, train_dataset=ds2, args=args_s2, peft_config=None)
trainer_s2.train()
os.makedirs(final_dir, exist_ok=True)
trainer_s2.model.save_pretrained(final_dir); tok.save_pretrained(final_dir)
print(f"최종 어댑터 저장: {final_dir}")
# 학습시킨 모델들을 전부 저장한다
if do_merge:
merged = model.merge_and_unload()
merged.save_pretrained(final_dir, safe_serialization=True)
tok.save_pretrained(final_dir)
print(f"병합된 단일 모델 저장 완료: {final_dir}")
del trainer_s2, model
if torch.cuda.is_available(): torch.cuda.empty_cache()코드를 입력하세요6. 출력부분 개선
이 곳이 정말 중요한 부분이었다.. 이 부분에서 다양한 제약이 이루어진다.
- 일반적으로 자주 쓰는 단어는 데스크리서치 + 내 카톡을 기반으로 단어사전을 만든 후, 단어사전 내 없는 단어들은 한 번 더 생각을 하고 출력하도록 함. (사실 카톡 텍마에서 살아남은 건 많이 없었음 ㅎ..)
이는 푶, 씟 등의 이상한 문자 출력을 최대한 방지하기 위해서임. - 무의미한 ㅋㅋㅋㅋ ㅎㅎㅎㅎ 출력방지
- 심한 비속어 몇 개 출력 방지
# ===== 1) 정규화 사전 =====
NORMALIZE_MAP = {
# 축약/구어
"ㅇㅋ": "오케이",
"ㅇㅇ": "응",
"ㄴㄴ": "아니",
"ㄱㄱ": "고고",
"ㄷㄷ": "두근두근",
"ㅁㅊ": "미쳤다",
"ㅅㄱ": "수고",
"ㅊㅋ": "축하",
"ㄱㅅ": "감사",
"뇌피셜": "거짓말",
"ㅂㅂ": "바이바이",
"ㅂㅇ": "바이",
"ㅈㄴ": "엄청",
"졸": "엄청",
"겜": "게임",
"갬성": "감성",
"걍": "그냥",
"뭐함": "뭐 해",
"뭐하냐": "뭐 하냐",
"뭐하니": "뭐 하니",
"머해": "뭐 해",
"머함": "뭐 해",
"뭐함?": "뭐 해?",
"ㅎㅇ": "안녕",
"하이": "안녕",
"헬로": "안녕",
"굿모닝": "좋은 아침",
"굿밤": "좋은 밤",
"굿나잇": "잘 자",
"쌉가능": "완전 가능",
"ㄱㅊ": "괜찮아",
"구리다": "별로다",
"짜쳐": "별로다",
"빻았다": "별로다",
"노상관": "상관없어",
"인정": "맞아",
"ㄹㅇ": "진짜",
"개좋다": "정말 좋다",
"개쩐다": "정말 대단하다",
"쩐다": "대단하다",
"킹받네": "화난다",
"킹받": "화남",
"빡친": "화난",
"빡침": "화남",
"웃프다": "웃기고 슬프다",
"꿀잼": "재미있다",
"노잼": "재미없다",
"뇌절": "과하다",
"ㅗ": "화남",
"꺼져": "화남",
# 맞춤법/표기 변형
"졸라": "엄청",
"존나": "엄청",
"존맛": "정말 맛있다",
"존버": "끝까지 버틴다",
"ㅈ됐": "큰일났다",
"ㅈ되": "큰일나",
"ㅈ됨": "큰일남",
"ㅈㄹ": "헛소리",
"개빨리": "아주 빨리",
"개느려": "아주 느리다",
"개힘들어": "아주 힘들다",
"개귀찮": "아주 귀찮다",
"개피곤": "아주 피곤하다",
# 빈도 높은 말끝/이모티브
"ㅇㅈ": "인정",
"ㄹㅇㅋㅋ": "진짜 웃김",
"ㅋㅋ": "ㅎㅎ",
"ㅋㅋㅋ": "ㅎㅎㅎ",
"ㅋㅋㅋㅋ": "ㅎㅎㅎㅎ",
"ㅠ": "ㅜ",
"ㅠㅠ": "ㅜㅜ",
"ㅜㅜ": "슬프다",
"ㅎ": "ㅎㅎ",
"ㅎㅋ": "ㅎㅎ",
}
# ===== 2) 데이터 증강용 동의어 세트 =====
AUGMENT_MAP = {
"오케이": ["ㅇㅋ", "오케이", "OK", "오키", "오케"],
"응": ["응", "ㅇㅇ"],
"아니": ["아니", "ㄴㄴ", "노노", "아뇨"],
"고고": ["ㄱㄱ", "고고"],
"수고": ["수고", "ㅅㄱ", "수고링"],
"축하": ["축하", "ㅊㅋ", "추카", "축하해"],
"감사": ["감사", "ㄱㅅ", "감사해요", "고마워"],
"안녕": ["안녕", "ㅎㅇ", "하이", "헬로"],
"좋은 아침": ["좋은 아침", "굿모닝"],
"잘 자": ["잘 자", "굿나잇", "굿밤", "잘자"],
"괜찮아": ["괜찮아", "괜춘", "ㄱㅊ"],
"상관없어": ["상관없어", "본인 알아서", "맘대로 해"],
"맞아": ["맞아", "인정", "ㅇㅈ", "ㅇㅇ"],
"진짜": ["진짜", "레알", "리얼", "ㄹㅇ"],
"정말 좋다": ["정말 좋다", "개좋다", "엄청 좋다"],
"대단하다": ["대단하다", "쩐다"],
"정말 대단하다": ["정말 대단하다", "개쩐다"],
"화난다": ["화난다", "킹받네", "빡친다"],
"화남": ["화남", "빡침", "킹받"],
"재미있다": ["재미있다", "재밌다", "꿀잼"],
"재미없다": ["재미없다", "노잼"],
"과하다": ["과하다", "뇌절"],
"큰일났다": ["큰일났다", "ㅈ됐다", "망했다"],
"아주 빨리": ["아주 빨리", "개빨리", "엄청 빨리"],
"아주 느리다": ["아주 느리다", "개느려"],
"아주 힘들다": ["아주 힘들다", "개힘들어"],
"아주 귀찮다": ["아주 귀찮다", "개귀찮"],
"아주 피곤하다": ["아주 피곤하다", "개피곤", "디지겠는디"],
"그냥": ["그냥", "걍"],
"왜 이렇게": ["왜 이렇게", "왤케"],
"뭐 해": ["뭐 해", "뭐함", "머해", "머함"],
"진짜 웃김": ["진짜 웃김", "개웃김", "ㅈㄴ웃김"],
"슬프다": ["슬프다", "ㅜㅜ", "ㅠㅠ"],
"ㅎㅎ": ["ㅎㅎ", "ㅋㅋ", "ㅋㅋㅋ", "ㅋㅋㅋㅋ"],
}
- 무지성으로 이상한 헛소리, 단어조합 못 하게 방지하는 파라미터 설정
- 프롬프트 설정에 영어, 한자 금지제약 걸고, AI, 인공지능, 도와주다, 어시스턴트 등의 단어도 최대한 방지함.
# 한국어만 말할 수 있도록 제약
_ALLOWED_CHARS_RE = re.compile(r"[^가-힣ㄱ-ㅎㅏ-ㅣA-Za-z0-9\s\.\,\!\?\~\:\;\-\(\)\[\]\'\"/@]+")
def remove_weird_chars(text: str) -> str:
"""허용 문자 외 제거(희귀/깨짐 문자 방지)."""
return _ALLOWED_CHARS_RE.sub("", text)
# ㅋ, ㅎ 과대사용 방지
def collapse_laughter(text: str, keep="ㅎㅎ", max_repeat=2) -> str:
"""
ㅋㅋ/ㅎㅎ 과다 반복 억제.
- 단독 출현 시 keep(기본 'ㅎㅎ')로 정규화
- 연속 길이는 max_repeat 로 절삭
"""
# 연속 ㅋ/ㅎ을 지정 길이로 축약
text = re.sub(r"ㅋ{3,}", "ㅋㅋ", text)
text = re.sub(r"ㅎ{3,}", "ㅎㅎ", text)
# 단독 ㅋㅋ / ㅎㅎ 만 있을 때는 keep 로 교체
if text.strip() in {"ㅋ", "ㅋㅋ", "ㅋㅋㅋ", "ㅎㅎ", "ㅎㅎㅎ"}:
return keep
return text
#무분별한 헛소리를 하지 못하게 방지하는 파라미터
MAX_TURNS = 4
MAX_NEW_TOK = 128
TEMPERATURE = 0.6 # 높을수록 언급 확률이 낮은 단어도 뽑힘. 숫자가 낮을수록 보수적.
TOP_P, TOP_K= 0.9, 50 # TOP_P: 상위 언급 90% 미만은 버림 / TOP_K: 상위 언급 50개 미만은 버림
# 프롬프트에 적고 싶은 요구사항을 적어야 함 ** 안 적으면 영어/한자/AI 봇이다라고 대답
def run_colab_chat(model, tokenizer):
history = []
system_prompt = "너는 사용자의 가장 친한 친구야. 반드시 순수한 한글을 사용한 구어체 반말로만 대화해야 해. 절대로 한자(漢字)나 영어를 사용하면 안 돼. 'AI', '인공지능', '챗봇', '도와줄게', '어시스턴트', 'Assistant', '역할' 같은 단어도 절대 사용하지 마.\\n\\n"
print("친구 챗봇과의 대화를 시작합니다. '종료' 또는 'exit'를 입력하면 대화가 끝납니다. ===")
while True:
try:
user_input = input("나 > ")
if user_input.lower() in ["종료", "exit"]:
print("챗봇 > 잘 가! 다음에 또 봐.")
break
prompt_parts = [system_prompt]
recent_history = history[-5:]
for turn in recent_history:
prompt_parts.append(f"### User:\\n{turn['user']}\\n\\n### Assistant:\\n{turn['assistant']}")
prompt_parts.append(f"### User:\\n{user_input}\\n\\n### Assistant:\\n")
full_prompt = "".join(prompt_parts)
inputs = tokenizer(full_prompt, return_tensors="pt", return_attention_mask=True).to(model.device)
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=256,
do_sample=True,
temperature=0.6,
top_p=0.9,
repetition_penalty=1.15,
eos_token_id=tokenizer.eos_token_id,
pad_token_id=tokenizer.pad_token_id
)
assistant_response = tokenizer.decode(outputs[0][inputs.input_ids.shape[1]:], skip_special_tokens=True).strip()
print(f"챗봇 > {assistant_response}")
history.append({"user": user_input, "assistant": assistant_response})
except (KeyboardInterrupt, EOFError):
print("\\n챗봇 > 대화를 강제 종료합니다.")
break
# --- 스크립트 실행 부분 ---
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Colab 셀 채팅 스크립트")
parser.add_argument("--model-dir", type=str, required=True)
args = parser.parse_args()
model, tokenizer = load_model_for_chat(args.model_dir)
run_colab_chat(model, tokenizer)
""")
결론은 다소 나아졌다.
약간 술에 만취한 내가 하는 헛소리와 비스무리한 무언가를 이야기하는 것 같다. 아니면 나 혼자 빈정대는 느낌도 들고.. ㅎ
하지만 피곤한 인간과 피곤한 AI의 자강두천이라 그닥 재미는 없다.



결국 UI를 예쁘게 만드는 건 실패했다. Gradio를 쓰면 된다는데, 속도가 너무 느려진다. 사실 욕심같아서는 최근 상장한 figma를 써보고 싶다. 물론 배운 적 없다.
하지만 SQLD가 끝나면 다시 오겠습니다. 푸하하..
