
Hi! I'm Jaylnne. ✋
오늘은 BERT 모델을 공부하던 중 BERTAdam이라는 독특한 옵티마이저(optimizer)를 접하게 되어서 이것에 대해 정리해보고자 글을 써보기로 했습니다.
아래 huggingface 깃헙 링크에 BERTAdam 뿐만 아니라 pytorch-pretrained-bert 라이브러리에 대한 설명이 잘 정리되어 있습니다. 시간이 되신다면 차후 pytorch-pretrained-bert 라이브러리 자체에 대해 공부하는 차원에서 읽어보면 좋을 것 같아요.
0. 시작하기 전에
아래 사항에 대한 이해가 있으시다는 전제하에 설명을 정리하도록 하겠습니다.
🖐
- BERT
- Optimizer (특히 Adam)
- L2 Regularization 와 weight decay
- bias correction
1. BERTAdam 은 무엇일까?
이름에서부터 짐작되는 게 있습니다. BERT와 Adam이 합쳐진 무언가라는 거요. Adam은 옵티마이저의 한 종류니까, 대충 눈치로만 추측해봐도 BERT 학습에 사용된 어떤 특별한 Adam 옵티마이저 정도라는 걸 알 수 있겠네요.
huggingface 깃헙 링크에서는 뭐라고 말하는지 봅시다!
Bert version of Adam algorithm with weight decay fix, warmup and linear decay of the learning rate.
역시. 'Bert version of Adam' Adam 옵티마이저의 BERT 버전이라고 말하네요. 뒤에 주렁주렁 붙어 있는 다른 것들은 잠시 무시해봅시다. 어차피 지금부터 차근차근 짚으면서 정리해볼 거니까요.
2. BERTAdam과 Adam의 차이점
위 깃헙 링크의 pytorch-pretrained-bert 마크다운 문서에서는 BERTAdam과 Adam의 차이점에 대해 두 가지로 정리하고 있습니다.
- BertaAdam implements weight decay fix
- BertAdam doesn't compensate for bias as in the regular Adam optimizer
핵심이 되는 두 가지 키워드는 weight decay와 bias인 것 같은데요. weight decay를 고정한다(weight decay fix)는 건 무슨 의미이고, 편향을 보정하지 않는다(doesn't compensate for bias)는 것은 무슨 의미인지 하나씩 차근차근 알아보겠습니다.
2-1. weight decay fix
weight decay를 고정한다는 점이 Adam과의 첫 번째 차이점이라고 합니다. Adam은 weight decay 가 고정되어 있지 않고 변화한다는 것을 반대로 추측해볼 수 있겠네요. (정말 그럴까요. 그게 정상일까요. 뒤에서 얘기할 예정.) 우선 weight decay부터 다시 한번 짚어봅시다. 우리가 일반적으로 알고 있는 gradient descent 식을 떠올려보아요.
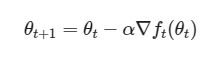
그리고 weight decay 가 적용된 식을 봅시다.
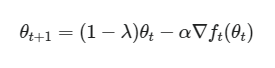
θt 앞에 (1−λ)를 곱해준다는 점이 다르네요. 여기서 이 λ가 바로 0에서 1 사이 값을 가지는 decay rate입니다. (우리가 직접 설정하는 하이퍼파라미터에요.) λ가 0에서 1 사이 값이기 때문에 (1−λ)도 0에서 1 사이 값이 되고요. 때문에 (1−λ)θt는 θt 보다 작은 값이 됩니다. Decay! 줄어든 거죠. 무엇이? θt, 즉 weight가요. 아하. 그래서 weight decay.
그래서! weight decay 를 '고정'한다는 건 모델의 학습이 이루어지는 동안, θ**t에 곱해지는 (1−**λ) 값이 고정되어 변하지 않는다는 것을 의미하는 겁니다. (결론이 난 것 같지만, 여기서 멈추지 말고 글을 계속 읽어주세요. 진짜 의미는 조금 다르거든요.)
오버피팅은 특정 weight 값이 커질수록 발생할 가능성이 높아지는데요. 이러한 weight decay 방법은 (고정이든 아니든) weight 값이 비약적으로 증가하여 모델이 오버피팅되는 것을 방지하여 줍니다. 하지만 weight decay 값을 너무 크게 설정하면 반대로 언더피팅이 발생할 수 있기 때문에 (언제나 그렇듯) 적절한 값을 설정해주는 것이 중요합니다.
🤔그렇다면 Adam에서는 weight decay가 고정되어 있지 않다는 걸까요?
실제로 정말 그렇고, 그렇게 둬도 괜찮은 걸까요?
이 문제에 대한 답을 하려면 사실 L2 Regularization에 대한 이야기부터 시작해야 합니다. 사실 대부분 옵티마이저의 weight decay 기법이 코드 상으로는 L2 Regularization 을 이용해 구현되어 있거든요. L2 Regularization이 우리가 원하는 weight decay 로서의 기능을 하기 때문입니다.
하지만 Adam의 경우에는 달라요. 다른 옵티마이저들처럼 똑같은 방식으로 L2 Regularization 을 이용해 weight decay를 구현하면 Adam 알고리즘을 거치면서 다른 값들(m와 v)의 영향을 받게 됩니다. 무슨 말인가 싶죠? 너무 깊게 말고, 최대한 단순히 이해해 봅시다.
아래 그림의 6, 7, 8, 12번만 봐주세요!

6번에서 분홍색으로 표시된 부분이 기존 Adam 알고리즘에서 L2 Regularization을 적용하고 있는 부분입니다. 그게 g 값으로 업데이트되더니 7번에서 m 값을 업데이트하는 데 사용되죠? 그리고 8번에서는 v 값을 업데이트 하는데 사용되고요. 그렇게 업데이트를 거친 m 값과 v 값이 12번에 가서야 비로소 weight 값을 업데이트 하는데 사용됩니다. 그러는 동안 우리가 처음 설정했던 λ 값은 당연히 다른 값들의 영향을 받아 변화했을 거예요. 우리가 weight decay 효과를 0.5 만큼 적용하고 싶어서 λ 값을 0.5로 설정했다고 해도, 막상 weight 가 업데이트되는 12번 줄에서는 온전히 0.5 만큼의 weight decay 효과를 주지 못하게 되는 거죠.
BERTAdam에서는 이러한 문제를 방지하기 위해 12번 초록색 표시처럼 weight 업데이트 식에 λ 를 직접 곱해주게 됩니다. 그렇게 하면 우리가 처음 설정한 λ 값의 영향이 다른 값들에 의해 변하지 않고 그대로 weight decay에 적용되겠죠! weight decay fix의 진짜 의미는, λ 값 자체가 변화하지 않는다기보다, 이렇게 그 영향이 weight decay에 '온전히, 그대로' 적용된다는 걸 뜻하는 거였군요.
✨ 아래 링크는 AdamW 옵티마이저에 대해 소개하고 있는 논문입니다. 위에서 언급한 내용을 수식과 함께 자세히 설명하고 있고, 그에 대한 해결 방안으로서 제시한 것이 곧 BERTAdam의 weight decay fix 에도 적용된 방법입니다! 간단히, BERTAdam = AdamW + no bias correction이라고 할 수도 있습니다.
2-2. doesn't compensate for bias
Adam과 BERTAdam의 두 번째 차이점은 '편향을 보정하지 않는다.'(doesn't compensate for bias)입니다. 한 번만 더 Adam 알고리즘을 봅시다.
이번에는 9번, 10번만 보시면 됩니다! 더 말할 것도 없어요. 9번, 10번이 bias correction이라고 불리는 과정이고 BERTAdam에서는 이 과정이 생략되었다. 끝. 끝이에요.

BERT 개발팀 그러니까 구글 개발자들이 왜 BERTAdam 에서 bias correction 과정을 생략했는지 그 이유에 대해서는 아직 알아내지 못했습니다. 😂 심지어, 최근 BERT 모델 파인튜닝 안정성에 관한 한 연구 논문을 발견했는데요. 옵티마이저에서 bias correction을 생략한 것이 BERT를 파인튜닝할 때 나타나는 불안정성의 원인 중 하나였다고 합니다. (아래 해당 논문의 링크를 달아둘게요!)
3. BERTAdam의 사용법
구슬이 서 말이라도 꿰어야 보배라고 실제 코드에서 어떻게 BERTAdam을 사용할 수 있는지 알아야겠죠? 물론 우리가 해당 수식을 일일이 구현할 필요는 없습니다. 다른 개발팀들이 이미 만들어둔 라이브러리를 잘 이용하면 되죠.
3-1. huggingface의 pytorch-pretrained-bert의 BertAdam
아래 예시 코드와 같이 huggingface의 라이브러리에서 BertAdam 클래스를 불러와 사용할 수 있습니다.
from pytorch_pretrained_bert.optimization import BertAdam, WarmupLinearSchedule
optimizer = BertAdam(params, lr=required, warmup=-1, t_total=-1, schedule='WarmupLinearSchedule',
b1=0.9, b2=0.999, e=1e-6, weight_decay=0.01,
max_grad_norm=1.0)3-2. huggingface의 transformers의 AdamW
아래 예시 코드와 같이 huggingface의 transforemrs에서 AdamW 클래스를 불러온 후 correct_bias 만 False로 바꾸어주시는 방법도 있습니다.
from transformers import AdamW
optimizer = AdamW(
optimizer_grouped_parameters,
lr=lr,
eps=epsilon,
correct_bias=False) # AdamW에서 bias correction 과정만 생략해주시면 BERTAdam이 됩니다!여기까지!
오늘은 마침 옵티마이저에 대한 자료와 BERT 모델을 함께 살펴보고 있던 차에 BERTAdam을 접하게 되어서 한번 자세히 정리해보았습니다.
감사합니다!
