
Hi! I'm Jaylnne! 😀
새롭고 어려운 지식을 많이 아는 것도 좋지만 기본기를 단단히 다지는 일도 못지않게 중요하다고 생각합니다. 그래서 저는 시간이 날 때마다 틈틈이 내가 알고 있다고 생각했던 기본 개념들을 하나씩 짚어보며 복습하고는 하는데요. 개념을 처음 접하는 초보자분들도 쉽게 이해하실 수 있었으면 해서, K겹 교차 검증을 쉽게 풀어 정리해볼까 합니다.
1. K겹 교차 검증의 출발
"왜 K겹 교차 검증을 생각해내게 되었을까?"
몇 년 전, 처음 이 개념을 배울 때는 'K겹'이라는 단어를 보고서는 얇은 반죽이 켜켜이 겹쳐져 있는 페스츄리 빵을 떠올릴 뿐이었습니다. 하하. 무엇을 어떻게 왜 겹겹이 교차해서 검증하겠다는 건지, 이름만으로는 전혀 감이 잡히질 않았죠.
머신 러닝 모델을 학습시킬 때 우리는 주로 데이터를 '학습 데이터'와 '테스트 데이터'로 나누어 작업합니다. 그렇죠? 테스트 데이터는 모델을 학습시킬 때는 사용하지 않고, 과적합을 방지하면서 모델이 잘 학습되었는지 테스트해보기 위해 사용합니다. 하지만 이 말은 즉, 학습 데이터로 사용한 데이터는 모델 테스트 과정에선 전혀 사용되지 않는다는 뜻이기도 합니다.
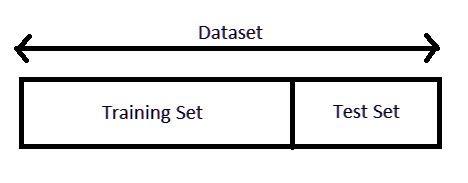
학습 데이터와 테스트 데이터의 비율을 보통 7:3으로 나눈다는 것을 생각해보면 아깝습니다. 70% 데이터를 모델 테스트 과정에서도 사용할 방법이 있다면 좋겠죠! (물론 데이터에 따라 7:3이 아닌 다른 비율로 나누는 경우도 많습니다. 확보 가능한 데이터의 양이 적다면 9:1의 비율로 분리하는 경우도 많습니다.)
그렇게 K겹 교차 검증이라는 개념이 생겨나게 된 겁니다.
2. K겹 교차 검증 (K-fold cross validation) 의 의미
그래서 K겹 교차 검증이 뭔데? 어떻게 전체 데이터셋을 모델 테스트에 활용할 수 있게 하는 건데?라는 생각이 듭니다. 이제 본격적으로 개념의 의미에 대해 알아보아요.
"집합을 체계적으로 바꿔가면서 모든 데이터에 대해 모형의 성과를 측정하는 검증 방식"
위 말은 K겹 교차 검증의 간단한 정의입니다. 하지만 대부분의 사전적 정의가 그렇듯 초보자는 무슨 말인지 이해할 수가 없습니다. (삑- 정상입니다. 괜찮습니다.) 그러니 우리는 차근차근 하나씩 떼어 이해해 봅시다!
2-1. 'K겹'
우선 'K겹' 이 가리키는 의미는 전체 데이터셋을 K개의 부분집합으로 나눈다는 것입니다. 별거 아닙니다. 그냥 아래 그림을 보세요!

이렇게 k개로 나눈 부분집합 데이터를 fold 라고 부른답니다. 앞에 숫자만 붙여 불러주면 되겠네요. 1번 fold, 2번 fold, 3번 fold ······ k번 fold, 이렇게요. 앞서 말씀드린
"집합을 체계적으로 바꿔가면서 모든 데이터에 대해 모형의 성과를 측정하는 검증 방식" 정의에서 '집합'이 무엇을 의미하는지 이제 알겠네요.
2-2. 교차
'K겹'이 무슨 말인지 알았으니 다음 단어를 봅시다. 무엇을 '교차' 한다는 뜻일까요? 이번에도 그림으로 이해하는 게 훨씬 쉽습니다. 아래를 보세요.
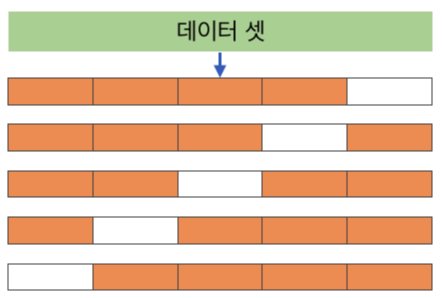
k개로 나눈 데이터셋의 부분집합들 (더 쉽게 말하자면, 위 그림에서 막대기들의 칸 한 칸씩이요)을 1번 fold, 2번 fold ······ 이렇게 부른다고 했죠. 바로 그 fold 들을 차례대로 교차해 테스트 데이터로 사용한다는 말입니다.
위 예시로 보여드린 그림의 맨 위 작대기를 보세요. 아하. 그러니까 예시에서는 첫 번째 모델 학습에서는 5번 fold를 테스트 데이터로 사용한다고 것으로 이해할 수 있겠네요. 맨 마지막 다섯 번째 fold 가 하얀색이니까요. 그리고 다음 모델 학습에서는 4번 fold가 테스트 데이터이고, 그다음엔 3번 fold ····· 이런 식으로 이어지면서 마지막 다섯 번째 모델 학습까지- 차례대로 fold가 테스트 데이터로 교차되어 사용되고 있습니다.
"집합을 체계적으로 바꿔가면서 모든 데이터에 대해 모형의 성과를 측정하는 검증 방식" 라고 하는 정의에서 '체계적으로 바꿔가면서 모든 데이터에 대해' 부분이 무엇을 의미하는지 이제 알겠네요.
2-3. '검증'
검증의 의미는 깊게 생각할 것도 없습니다. 테스트 데이터는 모델이 데이터를 잘 학습했는지 '검증'해보기 위해 사용하는 데이터잖아요! 사실 검증을 영어로 말하면 테스트일 뿐인 겁니다.
"집합을 체계적으로 바꿔가면서 모든 데이터에 대해 모형의 성과를 측정하는 검증 방식" 이라고 말한 정의에서 '검증'이 뜻하는 부분은 어디인지 너무 쉽게 아시겠죠?
3. K겹 교차 검증의 결과
이제 K겹 교차 검정의 의미와 원리는 대충 알겠네요. 만약 우리가 모델의 정확도(accuracy)를 측정해보고 싶다면 1번 fold가 테스트 데이터일 때 모델을 학습시켜 정확도를 산출하고, 2번 fold가 테스트 데이터일 때 모델을 학습시켜 정확도를 산출하고, 3번 fold가 테스트 데이터일 때 모델을 학습시켜 정확도를 산출하는 이 과정을 k번 fold까지 반복하는 겁니다. 어라. 그럼 여기서 한가지 의문이 들죠.
❓ 잠깐, 그럼 정확도가 대체 몇 개 나오는 거야? 그러니까 모델 검증 결과가····· k개나 나오는 거야?
🙌 네, 맞습니다.
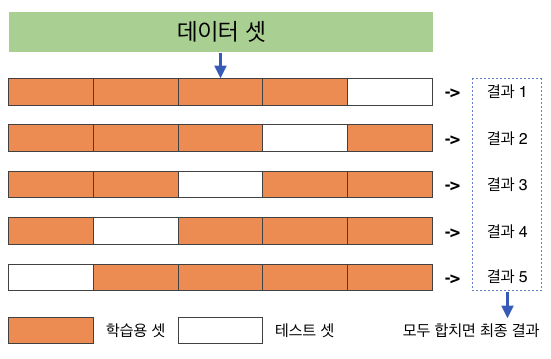
테스트 데이터를 다르게 설정할 때마다 학습 데이터의 구성도 당연히 달라집니다. (위 그림에서 하얀색 칸 위치가 달라질 때마다 주황색 칸의 구성도 달라지고 있는게 보이죠.) 약간씩 다른 구성의 학습 데이터로 학습하는 모델이 총 k번 돌아가게 되는 셈이죠! 모델이 총 k번 돌아갔으니 결과물도 총 k개 나오게 되는 겁니다. 그리고 이 k개의 결과물들의 평균값이 K겹 교차 검증 방식을 활용한 모델의 성능이 되는 거죠!.
4. K값 설정
그럼 K값은 몇으로 설정해주어야 할까요.
정답은 없습니다. 어쩔 수 없어요. 😌 데이터와 모델의 종류, 혹은 컴퓨터의 성능 등 상황에 따라 다양하게 달라질 수 있습니다.
머신러닝을 처음 공부하는 초보자에게는 이러한 애매모호성이 까다롭게 느껴질 것입니다. 무엇이 적정값일지 감도 잘 잡히지 않고요. 그게 정상이니 걱정하지 마세요. 공부를 점차 해나가시고, 실습 경험이 쌓이다 보면 언젠가 그에 대한 감이 잡히실 겁니다. 물론 저도 그러한 과정 중에 있는 주니어 데이터 사이언티스트입니다. 언제나 시행착오를 통해 배우게 되는 것 같습니다.
Tip❗ 파이썬에서는 sklearn(사이킷런) model_selection 패키지의 cross_val_score 모듈을 활용하여 쉽게 K겹 교차 검증을 실시할 수 있습니다.
from sklearn.model_selection import cross_val_score이렇게 'K겹 교차 검증'에 대해 정리해보았습니다. 저도 오랜만에 개념에 대해 복습할 수 있어서 좋았네요.
