RDS
- Relational Database Service, AWS가 제공하는 관리형 서비스다. (프로비저닝과 OS가 자동화)
- 다양한 데이터베이스 엔진을 제공한다.
- Aurora
- Postgresql
- Mysql
- MariaDB
- Oracle
- Microsoft SQL Server
- 지속적으로 백업이 되므로, 특정 시점으로 복원이 가능하다.
- 데이터베이스의 성능을 대시 보드에서 모니터링 가능하다.
- 읽기 전용 복사본을 생성해 읽기 성능을 올릴 수도 있다.
- 재해 복구 목적으로 다중 AZ 설정 가능하다.
- 유지 관리 기간에 업그레이드도 가능하다.
- 수직 확장하거나 읽기 전용을 추가해 수평 확장도 가능하다.
- 파일 스토리지는 EBS에 구성된다. (gp2, io1)
- RDS 인스턴스는 ssh 액세스가 불가능하다.
- EC2 인스턴스에 데이터베이스 엔진을 배포할 때 설정할 모든 것을 AWS가 제공함 -> 완전 관리형
- RDS 스토리지 오토 스케일링 기능이 활성화되어 잇으면 RDS가 이를 감지해서 자동으로 확장한다.
- 디비 스토리지 용량을 늘리려고 디비를 다운시키는 등의 작업이 필요 없다.
- IO가 많으면 스토리지를 오토 스케일링 해야 하는데, 이를 위해 최대 스토리지 임계값을 정해야한다.
- 할당된 용량에서 남은 공간이 10% 미만이 되면 스토리지를 자동으로 수정한다.
- 스토리지 부족 상태가 5분이상 지속되거나 지난 수정으로부터 6시간이 지났을 경우에 오토 스케일링이 활성화되어 있다면 스토리지가 자동 확장된다.
- 워크로드를 예측할 수 없는 애플리케이션에서 굉장히 유용하다.
- 스토리지 오토 스케일링은 모든 RDS 디비 엔진에서 지원된다.
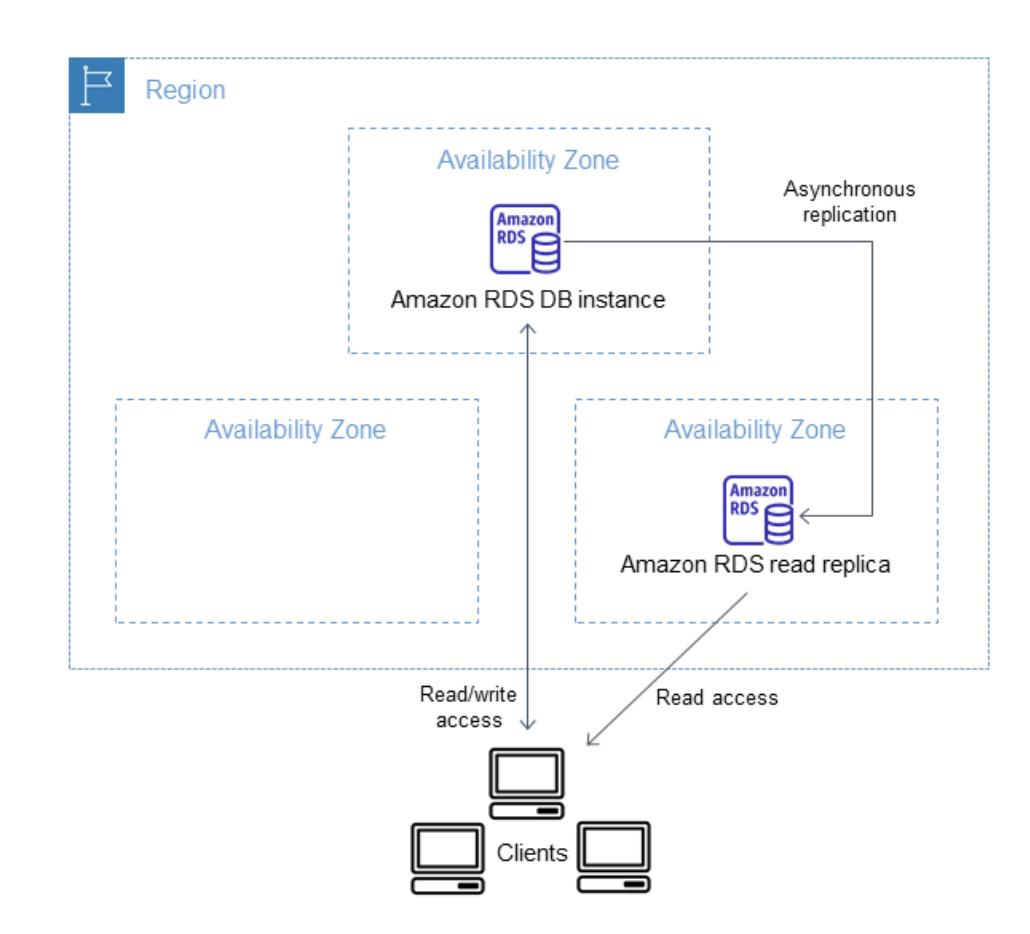
RDS 읽기 전용 복제본
- 읽기 전용 복제본은 최대 15개까지 생성 가능하다.
- 동일한 가용 영역 또는 가용 영역이나 리전을 걸쳐서 생성될 수 있다.
- 읽기 전용 복제본이 2개가 있고 메인 RDS가 있다면 두 읽기 전용 복제본 사이에 비동기식 복제가 발생한다.
- 비동기이므로 읽기가 일관적으로 유지된다.
- 읽기 전용 복제본을 마스터 데이터베이스로 승격시켜 사용할 수 있다.
사용 사례
- 운영 디비의 읽기 전용 복제본을 만들어서 분석 애플리케이션과 전용 복제본을 사용해 데이터를 분석할 수 있다.
- 클라이언트의 요청을 받는 운영DB에는 영향을 주지 않는다.
네트워크 비용
- AWS에서는 하나의 가용 영역에서 다른 가용 영역으로 데이터가 이동할 때 비용이 발생한다.
- 하지만 예외가 존재하며 보통 이 예외는 관리형 서비스다.
- RDS 읽기 전용 복제본은 관리형 서비스다.
- 읽기 전용 복제본이 다른 AZ지만 동일한 리전 내에 있을 때는 비용이 발생하지 않는다.
- 하지만 서로 다른 리전에 복제본이 존재하는 경우에는 이동할 때 네트워크에 대한 복제 비용이 발생한다.
Multi-AZ
- 다중 AZ는 주로 재해 복구에 사용된다.
- AZ A의 마스터 DB 인스턴스 AZ B의 스탠바이(대기) 인스턴스로 동기식 복제를 한다.
- 즉 마스터 DB의 모든 변화를 동기적으로 복제한다.
- 하나의 DNS 이름을 갖고 마스터에 문제가 생기면 스탠바이(대기) 인스턴스에도 자동으로 장애 조치가 수행된다.
- 전체 AZ 또는 네트워크가 손실될 때에 대비한 장애 조치이자, 마스터 DB가 고장나면 스탠바이 DB가 마스터 DB가 되도록 한다.
- 자동으로 장애 스탠바이가 마스터로 승격되기에 스케일링에 사용되지 않는다. 오로지 대기 목적이므로, 읽기 쓰기가 불가능하다.
- 읽기 전용 복제본을 다중 AZ로 설정할 수 있다.
- 단일 AZ에서 다중 AZ로 RDS 디비 전환이 가능한데 변환시에 다운 타임이 전혀 없다.
- 즉, DB를 중지할 필요가 없다
- 기본 DB의 RDS가 자동으로 스냅샷을 생성한다. -> 스탠바이 DB에 복원된다.
- 기존 DB를 읽기 전용 DB 복제본을 만들어 다중 AZ를 활성화하면 된다.
RDS Custom
- Oracle, Microsoft SQL Server에서만 가능하다.
- 기저 운영체제나 DB 사용자 지정 기능에 액세스할 수 있다.
- 내부 설정 구성, 패치 적용, 네이티브 기능 활성화, SSH 접근이 가능해진다.
Amazon Aurora
- AWS의 고유 기술로 Postgres 및 MySQL과 호환된다.
- RDS의 MySQL보다 5배 높은 성능, RDS의 Postgresql보다는 3배 높은 성능을 보장한다.
- Aurora 스토리지는 자동으로 확장된다. 10GB에서 시작하지만 디비에 더 많은 데이터를 넣을 수록 자동으로 128TB까지 커진다. (10GB ~ 128TB)
- 읽기 전용 복제본은 최대 15개의 복제본을 둘 수 있다. 복제 속도도 훨씬 빠르다.
- Aurora는 다중 AZ, MySQL RDS보다 훨씬 빠른 즉각적인 장애 조치를 취한다. 가용성도 높다.
- RDS에 비해 20% 비싸지만 스케일링 측면에서 훨씬 더 효율적이다.
높은 가용성과 읽기 스케일링
- Aurora는 특이하게 3 AZ에 걸쳐 데이터의 6개의 사본을 저장한다.
- 쓰기에는 6개 사본 중 4개가 필요하다.
- 읽기에는 6개 사본 중 3개만 있으면 된다.
- 일부 데이터가 손상되거나 문제가 있으면 백엔드에서 p2p 복제를 통한 자가 복구가 진행된다.
- 단일 볼륨에 의존하지 않고 수백개의 볼륨에 의존한다.
- 스토리지가 수백 개의 볼륨에 걸쳐 스트라이핑된다.
스트라이핑 : 스트라이핑(striping)은 데이터를 여러 개의 디스크나 스토리지 볼륨에 분산하여 저장하는 기술.
- 쓰기를 받는 인스턴스는 하나다.
- Aurora도 마스터가 존재하며 여기서 쓰기를 진행한다.
- 마스터가 작동하지 않으면 평균 30초 이내로 장애 조치가 시작된다. -> 매우 빠르게 장애 조치
- 마스터 외에 읽기를 제공하는 읽기전용 복제본은 최대 15개. 자동 스케일링도 설정 가능하다.
- 복제본을 많이 두고 읽기 워크로드를 스케일링할 수 있다.
- 마스터에 문제가 생기면 읽기 전용 복제본이 마스터로 대체된다.
- 이 복제본들은 리전 간 복제를 지원한다.
- 정리하면 마스터는 하나고 ,복제본은 여럿이며 스토리지가 복제된다.
- 작은 블록 단위로 자가 복구 또는 확장이 일어난다
Aurora DB cluster
- 마스터가 바뀌거나 장애조치가 실행될 수 있으므로 Aurora는 Writer 엔드포인트를 제공한다.
- Writer 엔드포인트는 DNS 이름으로 항상 마스터를 가리킨다.
- 따라서 장애 조치 후에도 클라이언트는 라이터 엔드포인트와 상호작용하게 되며 올바른 인스턴스로 자동으로 리다이렉트된다.
- 읽기 복제본도 오토 스케일링을 설정해 항상 적절한 수의 읽기 전용 복제본이 존재하도록 할 수 있다.
- Reader 엔드포인트도 존재한다. 모든 읽기 전용 복제본과 자동으로 연결된다.
- 따라서 클라이언트가 reader 엔드포인트에 연결될 때마다 읽기 전용 복제본 중 하나로 연결되며 이런 방식으로 로드 밸런싱을 도와준다.
Aurora 특징
- 자동 장애 조치
- 백엽 및 복구
- 격리 및 보안
- 산업 규정 준수
- 자동 스케일링
- 제로다운 타임 자동 패치
- 고급 모니터링
- 통상 유지 관리
- 백트랙: 과거 어떤 시점의 데이터로도 복원 가능하게 해주는 기능. 백업에 의존 하지 않는다.
Amazon Aurora 고급 개념
- 복제본 자동 스케일링을 사용해 읽기 요청을 분산하고 CPU 사용량을 감소시킬 수 있다.
- 사용자 지정 엔드포인트를 정의하고 사용해 특정 복제본에서 작업이 가능하다.
- 일반적으로 사용자 지정 엔드포인트를 정의하면 Reader 엔드포인트가 동작하지 않는다.
- 실무에서는 여러 사용자 지정 엔드포인트를 만든다.
- 서버리스 기능을 사용해 실제 사용량에 기반한 자동 데이터베이스 인스턴스화와 오토 스케일링을 가능하게 해준다. 이는 비정기적, 간헐적 또는 예측 불허한 워크로드에 유용하다. 용량 계획을 세울 필요가 없고 각 Aurora 인스턴스에 대해 매 초당 비용을 지불한다. 비용면에서 효율적이다.
- 멀티 마스터: 라이터 노드에 대한 즉각적 장애 조치로 라이터 노드에서 높은 가용성을 갖추고자 할때 사용한다.
- 이 경우 Aurora 클러스터의 모든 노드에셔 읽기 및 쓰기가 가능하다
- Global Aurora
- 모든 쓰기 및 읽기가 진행되는 하나의 기본 리전이 있다.
- 복제 지연이 1초 미만인 보조 읽기 전용 리전을 다섯개까지 설정할 수 잇고, 각 보조 지역마다 읽기 전용 복제본을 16개까지 생성가능하다. 이렇게 하면 세계 각지의 있는 읽기 전용 복제본의 지연시간을 단축할 수 있다.
- 또한 한 리전의 데이터베이스가 작동 중단될 경우 재해 복구 목적으로 다른 지역을 승격하는데 필요한 RTO, 즉 복구 시간 목표는 1분 미만이다.
- 평균적으로 Aurora 글로벌 데이터베이스에서 한 리전에서 다른 리전으로 데이터를 복제하는데는 1초 이하의 시간이 걸린다. ->
글로벌 Aurora를 사용하라는 힌트
- Aurora는 AWS내의 머신 러닝 서비스와의 통합을 지원한다. (Amazon SageMaker, Amazon Comprehend와 통합 가능)
- 이를 통해 Aurora는 머신 러닝 서비스에 데이터를 보내고 Aurora는 쿼리 결과를 응용 프로그램에게 반환한다.
RDS & Aurora
RDS 백업
자동 백업
- 이는 RDS 서비스가 자동으로 디비 유지 관리 시간에 데이터베이스 전체를 백업한다는 의미다.
- 5분마다 트랜잭션 로그도 백업. 가장 최신 백업이 5분전 임을 의미한다.
- 이 자동 백업을 사용하면 5분 전 어떤 시점으로도 복구가 가능하다.
- 자동 백업 보유 기간은 1일에서 35일까지로 설정 가능하다. 이 기능은 비활성화도 가능하다.
수동 DB 스냅샷 생성
- 사용자가 수동으로 트리거해야 한다.
- 수동 백업은 원하는만큼 오랫동안 보유할 수 있다는 장점이 있다.
- 원하는 기간동안 보유가 가능하다.
Aurora 백업
자동 백업
- 하루에서 35일까지 보유 가능한 자동 백업이다. 비활성화가 불가능하다.
- 지정 시간 복구 기능이 있는데, 정해진 시간 범위 내의 어느시점으로도 복구가 가능하다.
수동 디비 스냅샷
- 사용자가 수동으로 만들고, 원하는 기간만큼 보유 가능하다. RDS와 매우 유사하다.
복원(Restore)
- 복원이 가능한 것은 RDS 및 Aurora 백업 또는 스냅샷이다.
- 이를 새로운 디비로 복원 가능 자동 백업이나 스냅샷을 복원할 때마다 새로운 디비가 생성된다.
- S3로부터 MySQL RDS 디비를 복원 가능하다.
- 기본적인 개념은 온프레미스 디비의 백업 파일을 객체스토리지인 S3에 업로드하고 백업 파일을 복원하는 것이다.
- S3로부터 MySQL Aurora 클러스터로 복원
- Percona XtraBackup 이라는 소프트웨어를 사용해 백업한 후에 S3에 업로드하고 백업 파일을 복원하면 된다.
Aurora DB 복제
- 기존의 디비로부터 새로운 Aurora DB 클러스터를 만들 수 있다.
- 기존 배포 디비에 영향을 주지 않고 복제하여 개발 또는 테스트 수행 가능하다.
- 실제로 스냅샷을 만들고 복원하는 것보다 복제한 Aurora를 사용하는 편이 더 빠르다.
- 이유: 복제는 copy-on-write 프로토콜을 사용한다.
- 새로운 디비는 같은 클러스터 볼륨을 사용하기 때문에 빠르고 효율적이다. 데이터를 복제하지 않기 때문에
- 그리고 시간이 흐름에 따라 새 디비로 업데이트되면 변경된다.
- 디비 복제는 매우 빠르고 비용 면에서 효율적이다
RDS & Aurora Security
- RDS 및 Aurora 디비에 저장된 데이터를 암호화할 수 있다. 데이터가 볼륨에 암호화된다.
- KMS를 사용해 마스터와 모든 복제본의 암호화가 이뤄지며 이는 디비를 처음 실행할 때 정의된다.
- 어떤 이유에서든 마스터 데이터베이스를 암호화하지 않았다면 읽기 전용 복제본을 암호화할 수 없다.
- 암호화 되어 있지 않은 기존 디비를 암호화하려면 암호화되지 않은 디비의 디비 스냅샷을 가지고 와서 암호화된 디비 형태로 데이터베이스 스냅샷을 복원해야 한다.
- RDS와 Aurora는 전송중 데이터 암호화라는 기능이 있다. 따라서 클라이언트는 AWS의 TLS 루트 인증서를 사용해야 한다.
- IAM 역할을 사용해서 디비에 접속하거나 사용자 이름/비밀번호로 접속 가능하다.
- 보안 그룹을 사용해 디비에 대한 네트워크 액세스를 통제할 수 있다.(포트, 아이피, 보안 그룹 등)
- RDS & AURORA는 SSH로 접근 불가능. custom RDS는 제외다.
- 감사 로그 작성을 활성화하면 시간에 따라 RDS 및 Aurora에서 어떤 쿼리가 생성되는지 확인 가능 장기관 보관하고 싶다면 CloudWatch Log 서비스로 전송해야 한다.
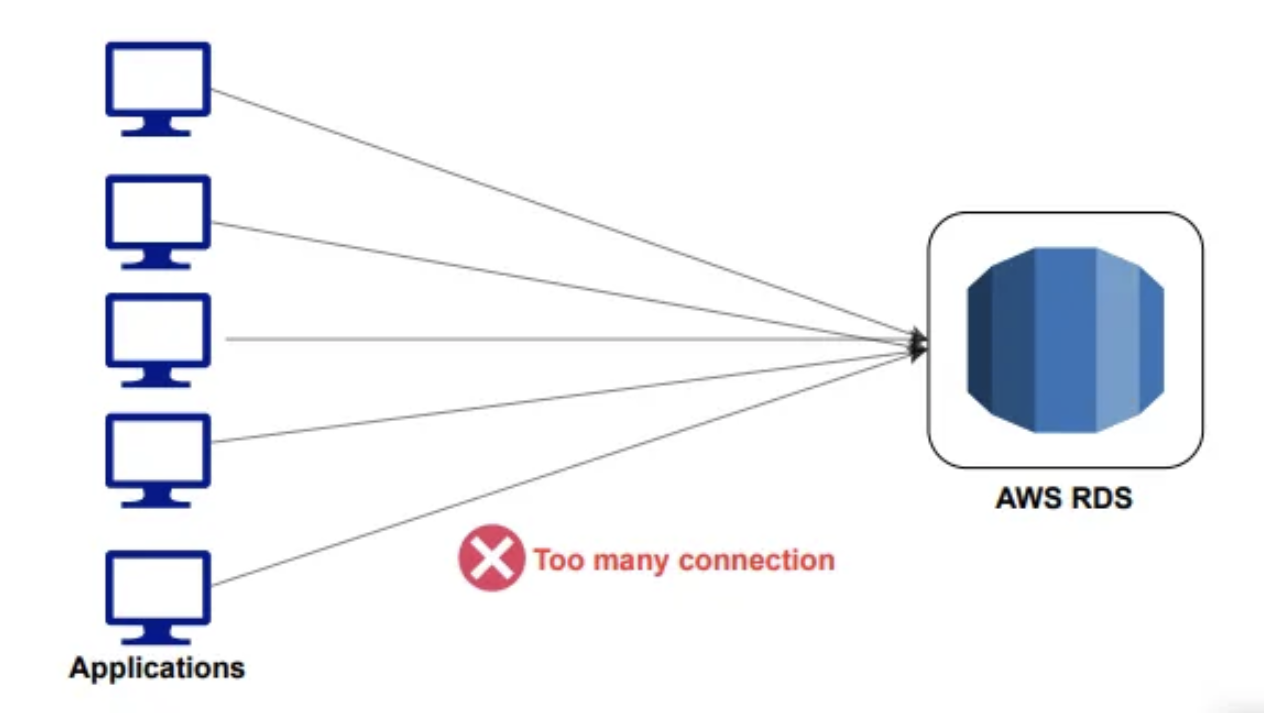
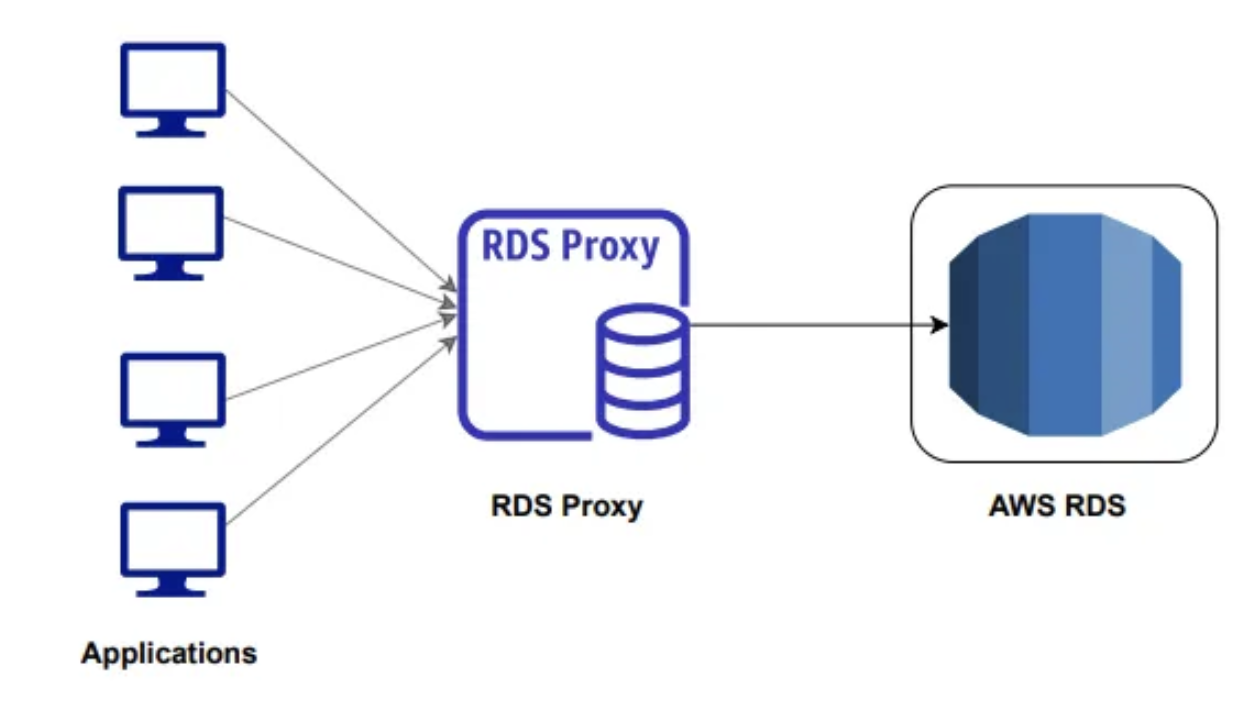
RDS Proxy
- 애플리케이션과 RDS 데이터베이스에 대한 연결을 최소화한다.
- RDS PRoxy는 완전한 서버리스로 오토 스케일링이 가능해 용량 관리가 필요 없고 가용성이 높다.(다중 AZ 지원)
- 장애 조치 시간을 66%까지 줄일 수 있다.
- RDS Proxy를 사용하면 애플리케이션은 장애와 무관한 RDS 프록시와 연결된다.
- RDS 프록시는 장애가 발생한 RDS 데이터베이스 인스턴스를 처리하므로 장애 조치 시간이 개선된다.
- RDS PROXY는 MySQL, PostgreSQL, MariaDB용 RDS를 지원하고 MySQL, PostgreSQL 용 Aurora를 지원한다.
- DB에 IAM 인증을 강제함으로써 IAM 인증을 통해서만 RDS 디비 인스턴스에 연결하도록 할 수 있다. 이때 자격증명은 AWS Secrets Manager 서비스에 안전하게 저장된다.
- RDS는 프록시는 퍼블릭 액세스가 절대 불가능하다.
ElasticCache
- 모든 캐시는 IAM 인증을 지원하지 않는다.
- IAM 정책은 AWS API 수준의 보안에만 사용된다.
- RDS와 동일한 방식으로 관계형 디비를 관리할 수 있다.
- 레디스와 멤캐시 같은 캐시 기술을 관리한다
- 낮은 지연 시간을 가진 인 메모리 디비다.
- 엘라스틱 캐시를 사용해 읽기 집약적인 워크로드의 부하를 줄이는데 도움이 된다.
- 애플리케이션의 상태를 Amazon 엘라스틱 캐시에 저장해 애플리케이션을 무상태로 만들 수 있다
- RDS와 같은 장점을 갖기 때문에 AWS는 동일한 유지 보수를 수행한다.
(운영체제, 패치, 최적화와 설정, 구성, 모니터링, 장애 회복 그리고 백업 수행한다.) - 엘라스틱 캐시를 사용할 때 캐시의 정합성을 고려하면 어려운 부분이 존재한다.
- 엘라스틱 캐시를 디비 캐시, 유저 세션 스토어로 많이 사용한다.
- Redis는 자동 장애 조치와 함께 다중 AZ를 수행한다.
- Redis 읽기 전용 복제본은 읽기 스케일링에 사용되며 고가용성을 가짐 지속성으로 인해 데이터 내구성도 갖추고 있다. 백업, 복원이 가능하며 RDS와 유사하다.
- Memcached는 데이터 분할을 위해 멀티 노드(샤딩)를 사용한다.
- 고가용성이 없고 복제가 일어나지 않으며 영구 캐시가 아니다.
- 백업 및 복원의 기능이 없다.
- 멀티 스레드 아키텍처이다.
- Memcached에서는 여러 인스턴스가 모두 샤딩을 통해 작동한다.
- Redis는 고가용성, 백업, 읽기 복제본 등을 위해 존재
- 반면, Memcached는 분산되어 있는 순수한 캐시. 데이터 손실되어도 괜찮은 경우, 고가용성이 없으며 백업, 복원 기능 없다.
ElasticCache 보안
- Redis에서만 IAM 인증을 지원하며, 나머지 경우에는 사용자 이름과 비밀번호를 사용하면 된다.
- ElasticCache에서 IAM 정책을 정의하면 AWS API 수준 보안에만 사용된다.
- Redis AUTH라는 Redis 내 보안을 통해 비밀번호와 토큰을 설정할 수 있다. -> Redis 클러스트를 생성할때
- 이는 캐시에 사용할 수 있는 보안 그룹에 대한 추가적인 수준의 보안이다.
- 그리고 전송 중 암호화를 위해 SSL 보안을 지원할 수 있다.
- EC2 인스턴스와 클라이언트가 있는 경우 Redis AUTH를 사용하여 Redis 클러스터에 연결할 수 있다.
- 이는 Redis 보안 그룹에 의해 보호되는 것이다.
- 또한, in-flight 암호화 사용하거나, Redis에서 IAM 인증을 활용할 수 있다.
Memcached
- 좀 더 높은 수준인 SASL 기반 인증을 지원한다. 상당히 고급이라 다른 종류의 인증 메커니즘이다.
일래스틱 캐시의 패턴
일래스틱 캐시에 데이터를 불러오는 패턴에는 3가지 패턴이 있다.
1. 지연 로딩
- 모든 읽기 데이터가 캐시되고 데이터가 캐시에서 오래될 수 있다. (케케 묵을 수 있다.)
2. Write Through
- 데이터를 오래된 데이터가 없는 디비에 기록될때마다 캐시에 데이터를 추가하거나 업데이트하는 것이다.
3. 세션 저장소
- Time To Live 속성으로 세션을 만료시킬 수 있다.

문제 해결과 개선 과제를 수행하며 성장을 추구하는 것을 좋아합니다.