SQS (Simple Queue Service)
SQS의 핵심은 자료구조 큐다. 큐는 메시지를 포함한다.
메시지를 담기 위해서 프로듀서가 SQS 대기열에 메시지를 전송해야 한다.
프로듀서는 한 개일 수도 그 이상일 수도 있다.
여러 프로듀서가 여러 개의 메시지를 SQS 대기열에 보내게 할 수 있다.
큐에서 메시지를 처리하고 수신해야 하는 대상을 컨슈머라고 한다.
만일 큐에 메시지가 있으면 소비자는 이 메시지를 폴링해서 정보를 얻는다.
그리고 그 메시지로 처리를 하고 큐에서 그 메시지를 삭제한다.
여러 컨슈머가 SQS 큐에서 메시지를 소비할 수 있도록 할 수도 있다.
Standard Queue
완전 관리형 서비스이며 애플리케이션을 분리하는 데 사용된다.
초당 원하는 만큼 메시지를 보낼 수 있고 큐에도 원하는 만큼 메시지를 포함시킬 수 있습니다
처리량에 제한이 없고 큐에 있는 메시지 수에도 제한이 없다. 각 메시지는 수명이 짧다.
메시지는 기본값으로 4일 동안 큐에 남아 있고 큐에 있을 수 있는 최대 시간은 14일이다.
즉 큐에 메시지를 보내자마자 컨슈머가 읽고 해당 보존 기간 내에 처리한 후 큐에서 삭제해야 한다. 그렇지 않으면 소실된다.
지연 시간이 짧아서 SQS는 메시지를 보내거나 SQS에서 메시지를 읽을 때마다 게시 및 수신 시 10밀리초 이내로 매우 빠르게 응답을 받게 된다.
SQS의 메시지는 작아야 한다. 전송된 메시지당 256KB 미만이어야 한다.
SQS는 대기열 서비스이므로 높은 처리량, 높은 볼륨 등이 있어서 중복 메시지가 있을 수 있습니다
최선의 오더라는 뜻으로 품절 메시지를 보낼 수도 있다.
SQS FIFO Queue
큐에 첫 번째로 도착한 메시지가 큐를 떠날 때도 첫 번째가 되도록 큐 내의 순서가 정렬된다는 의미다.
즉 Standard Queue보다 순서가 더 확실히 보장되는 것이다.
FIFO Queue는 순서를 확실히 보장하기 때문에 이 SQS 큐의 처리량에는 제한이 있다.
묶음이 아닐 경우에는 초당 300개의 메시지를 처리하고 메시지를 묶음으로 보낸다면 그 처리량은 초당 3,000개가 된다.
중복을 제거하도록 해주는 SQS FIFO 대기열의 기능으로 인해 정확히 한 번만 보낼 수 있게 해 준다.
우리는 메시지가 소비자에 의해 순서대로 처리된다는 것을 알고 있다.
따라서 분리가 발생하거나 메시지의 순서를 유지할 필요가 있을 때 FIFO 대기열을 사용하면 된다.
SQS로 너무 많은 메시지를 보내지 않도록 처리량에 제한도 할 수 있다.
Message Producer
프로듀서는 SDK를 사용해 메시지를 SQS로 전송한다.
메시지가 작성되면 프로듀서가 해당 메시지를 읽고 삭제할 때까지 SQS 큐에 유지된다.
메시지가 삭제됐다는 것은 메시지가 처리됐다는 뜻이다.
Standard SQS는 무제한 처리량을 보장한다.
Message Consumer
코드로 작성해야 하는 애플리케이션이다.
이러한 애플리케이션은 EC2 인스턴스 즉 AWS 상의 가상 서버에서 실행될 수 있다.
원하는 경우 자체 온프레미스 서버에서 실행할 수도 있고 AWS Lambda의 람다 함수에서 실행할 수도 있다.
컨슈머는 메시지들을 처리할 책임이 있으므로, 메시지들을 처리 후 DeleteMessage API로 큐에서 삭제한다.
그러면 다른 소비자들이 이 메세지를 볼 수 없게 되고, 메시지 처리가 완료된다.
Multi Ec2 Instance Consumer
SQS 큐에서 더 많은 메시지가 있어서 처리량을 늘려야 하면 소비자를 추가하고 수평 확장을 수행해서 처리량을 개선할 수 있다.
이런 경우에는 ASG(Auto Scaling groups)와 더불어 SQS를 사용한다.
컨슈머가 ASG의 내부에서 EC2 인스턴스를 실행하고 SQS 큐에서 메시지를 폴링한다.
ASG는 일종의 지표에 따라 확장되어야 하는데 우리가 사용할 수 있는 지표는 큐의 길이다.
ApproximateNumberOfMessages라고 한다.
모든 SQS 큐에서 쓸 수 있는 CloudWatch 지표다.
알람을 설정할 수도 있는데 큐의 길이가 특정 수준을 넘어가면 CloudWatch Alarm을 통해 오토 스케일링 그룹의 용량을 X만큼 증가시킨다.
만일 웹사이트에 오더가 폭주했다거나 해서 오토 스케일링 그룹이 더 많은 EC2 인스턴스를 제공하면 메시지들을 더 높은 처리량으로 처리할 수 있다.
SQS Security
SSE-SSQ 타입을 통해 메시지를 보내고 생성함으로써 전송 중 암호화를 하거나KMS 키를 사용하여 미사용 암호화를 얻고 원한다면 클라이언트 측 암호화를 할 수도 있다.
이는 클라이언트가 자체적으로 암호화 및 암호 해독을 수행해야 함을 의미한다. SQS에서 기본적으로 지원하는 것은 아니다.
액세스 제어를 위해 IAM 정책은 SQS API에 대한 액세스를 규제할 수 있고 S3 버킷 정책과 유사한 SQS 액세스 정책도 있다.
SQS 큐에 대한 교차 계정 액세스를 수행하려는 경우나 곧 배울 SNS 혹은 Amazon S3 같은 다른 서비스가 SQS 큐에 S3 이벤트 같은 것을 쓸 수 있도록 허용하려는 경우에 매우 유용하다.
메시지 가시성 시간 초과
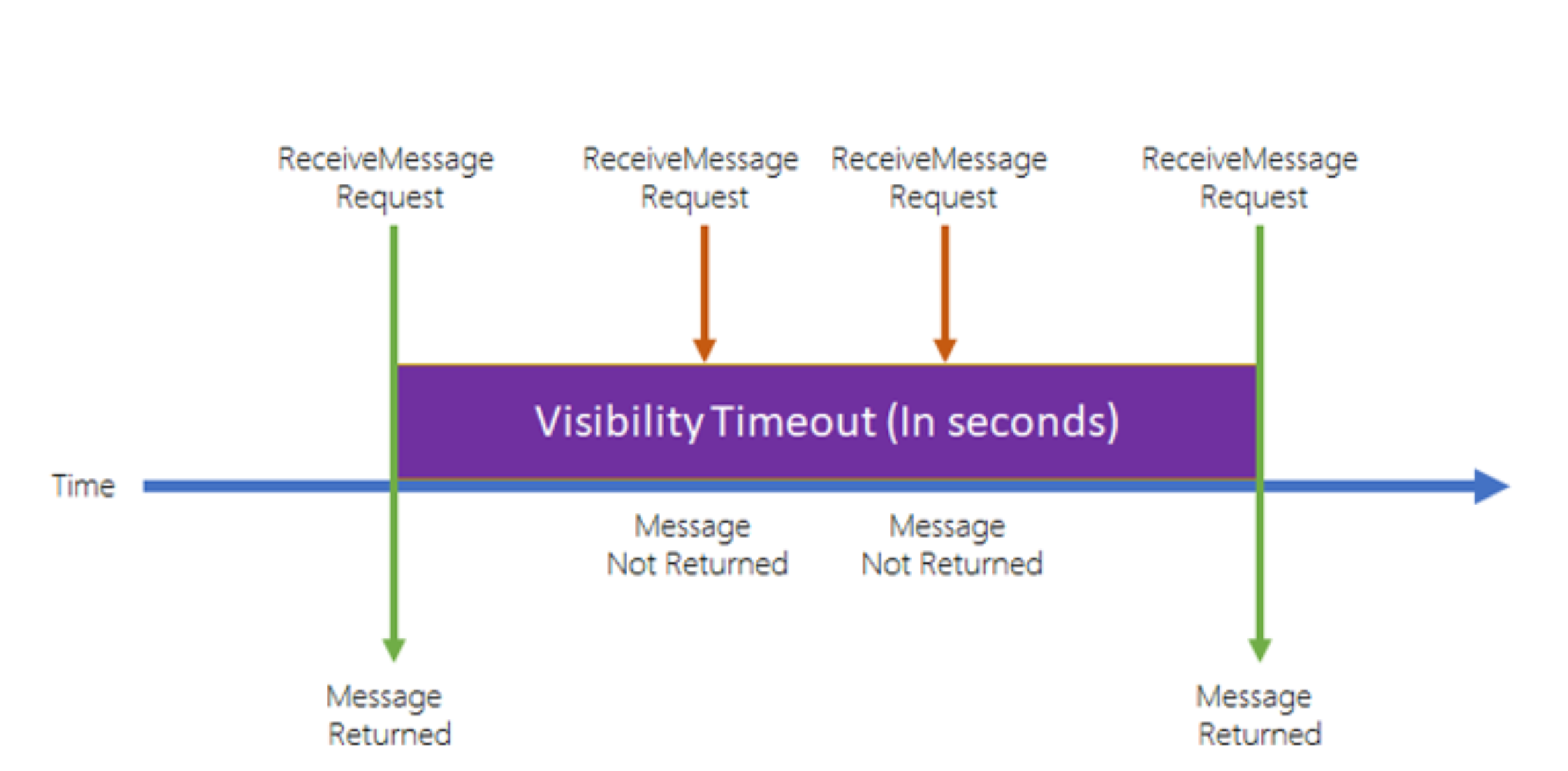
소비자가 메시지를 폴링하면 그 메세지는 다른 소비자들에게 보이지 않게 된다. 예시를 들어보자.
컨슈머가 ReceiveMessage 요청을 하면, 큐에서 메시지가 반환된다.
이제 가시성 시간 초과가 시작된다.
기본값으로 메시지 가시성 시간 초과는 30초다.
그 말은 이 30초 동안 메시지가 처리되어야 한다는 것이다.
그러면 동일한 혹은 다른 컨슈머가 메시지 요청 API를 호출하면 메시지가 반환되지 않는다.
시간 초과 기간 내에 또 다른 요청이 들어와도 메시지가 반환되지 않는다.
즉 가시성 시간 초과 기간 내에서는 그 메시지는 다른 소비자들에게 보이지 않는다.
하지만 가시성 시간 초과가 경과되고 메시지가 삭제되지 않았다면 메시지는 큐에 다시 넣는다.
그러면 다른 컨슈머 또는 동일한 컨슈머가 또 ReceiveMessage API 호출을 하면 이전의 그 메시지를 또 받게 된다.
가시성 시간 초과 기간 내에 메시지를 처리하지 않으면 메시지가 두 번 처리될 수도 있다는 것을 알 수 있다.
만일 컨슈머가 메시지를 적극적으로 처리하고 있지만 메시지를 처리하는 데 시간이 더 필요하다는 것을 알고 있는데 메시지를 처리하지 않아 가시성 시간 초과 기간을 벗어날 때를 위해 ChangeMessageVisibility라는 API가 있다.
즉 컨슈머가 메시지를 처리하는 데 시간이 더 필요하다는 것을 알고 있고 해당 메시지를 두 번 처리하고 싶지 않다면 컨슈머는 ChangeMessageVisibility API를 호출하여 SQS에 알려야 한다.
가시성 시간 초과는 애플리케이션에 합당한 것으로 설정되어야 하고 컨슈머는 시간이 조금 더 필요하다는 것을 알면 ChangeMessageVisibility API를 호출하도록 프로그래밍해야 한다.
그러면 더 많은 시간을 확보하고 해당 가시성 시간 초과 기간을 늘릴 수 있다.
SQS Long polling
컨슈머가 큐에 메시지를 요청하는데 대기열에 아무것도 없다면 메시지 도착을 기다리면 된다. 이것을 롱 폴링이라고 합니다
첫 번째 장점은 지연 시간을 줄이기 위해서다.
두 번째 장점는 SQS로 보내는 API 호출 숫자를 줄이기 위해서다.
롱 폴링을 구성하는 방법엔 두 가지가 있다.
큐 레벨에서 구성하여 폴링하는 아무 컨슈머로부터 롱 폴링을 활성화하는 방법이 있다.
WaitTimeSeconds를 지정함으로 컨슈머가 스스로 롱 폴링을 하도록 선택할 수도 있다.
만약 시험에서 SQS 큐에 대한 API 호출 수를 최적화하고 지연 시간을 줄이는 법을 묻는다면 롱 폴링을 떠올려야 한다.
SQS With ASG
SQS 큐와 ASG가 있을 때 ASG 내의 EC2 인스턴스가 메시지를 SQS 큐에서 폴링한다.
이는 ASG를 자동으로 큐 크기에 따라 확장시키기 위함으로 CloudWatch 지표인 큐 길이를 보고 결정할 수 있다.
ApproximateNumberOfMessages라고 하는 이 지표는 대기열에 몇 개의 메시지가 남아 있는지를 표시한다.
이를 기반으로 경보를 지정할 수 있는데 가령 이 지표가 1,000을 넘는 경우 1,000개의 메시지가 대기열에서 처리를 기다리고 있다는 뜻으로 처리에 지연이 발생하고 있음을 파악할 수 있다.
따라서 경보를 생성하여 1,000개의 메시지가 대기 중임을 경보를 통해 알리면 이 경보가 EC2 인스턴스가 충분하지 않음을 근거로 오토 스케일링 그룹에 확장 동작을 트리거한다.
이렇게 하면 ASG에 더 많은 EC2 인스턴스가 추가되며 확장이 이루어져 메시지가 훨씬 더 빨리 처리된다.
동시에 SQS 큐의 크기는 줄어들어 이에 대한 축소 또한 실행된다.
분리나 급격히 증가한 로드 혹은 시간초과 등의 문제에서 신속한 스케일링이 필요한 경우에는 SQS 큐를 떠올려야 한다.
SNS (Simple Notification Service)
메시지 하나를 여러 수신자에게 보낸다고 가정하면 pub/sub 구조를 사용하는 것이 이상적이다.
메시지를 토픽으로 publish 한다.
토픽에는 많은 구독자가 있으며 각 구독자는 SNS 토픽에서 해당 메시지를 수신하고 이를 보관할 수 있다.
SNS에서 "이벤트 프로듀서"는 한 SNS 토픽에만 메시지를 보낸다.
SNS 토픽 구독자는 해당 토픽으로 전송된 메시지를 모두 받게 된다.
그리고 메시지를 필터링하는 기능을 사용하는 경우에도 메시지를 받을 수 있다.
토픽 별로 최대 1,200만 이상의 구독자까지 가능하다. (추후 변경 가능)
계정당 가질 수 있는 토픽 수는 최대 10만 개다. (추후 변경 가능)
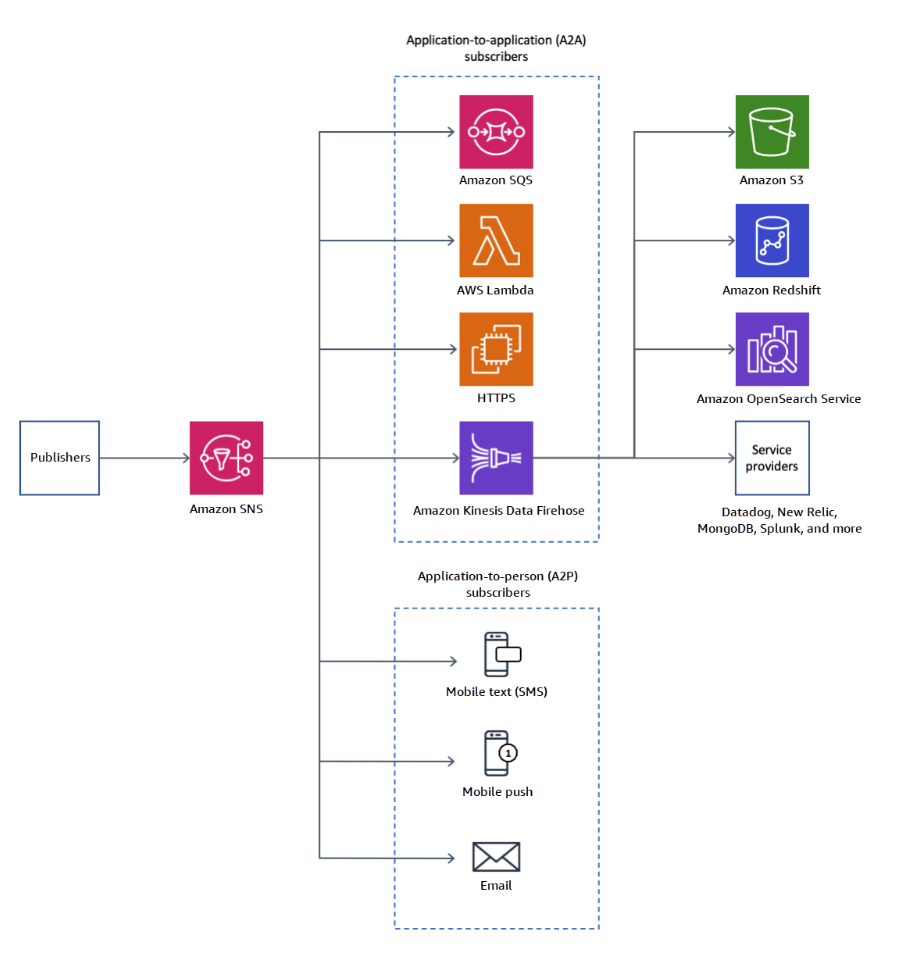
SNS에서 직접 이메일을 보낼 수도 있고 SMS 및 모바일 알림을 보낼 수도 있다.
또한 지정된 HTTP 또는 HTTPS 엔드 포인트로 직접 데이터를 보낼 수도 있다.
SNS는 SQS와 같은 특정 AWS 서비스와 통합하여 메시지를 큐로 직접 보낼 수도 있고
메시지를 수신한 후 함수가 코드를 수행하도록 Lambda에 보내거나 Firehose를 통해 데이터를 Amazon S3나 Redshift로 보낼 수 있다.
SNS는 다양한 AWS 서비스에서 데이터를 수신할 수 있다.
CloudWatch 경보 Auto Scaling 그룹 알림, CloudFormation State Changes Budgets, S3 버킷, DMS, Lambda, DynamoDB RDS 이벤트 등이 있다.
AWS에서 알림이 발생하면 이러한 서비스가 지정된 SNS 토픽으로 알림을 보낸다.
구독자에게 메시지를 push 하는 부분이 중요하다. 완전 관리형 서비스다.
메시지 발행 방법
SDK Topic Publish를 사용해 SNS에 메시지를 게시할 수 있다.
먼저 토픽을 만든 다음 하나 또는 여러 개의 구독을 만들고 SNS 토픽에 게시하면 된다.
그럼 모든 구독자가 자동으로 해당 메시지를 받는다.
혹은 모바일 앱 SDK 전용 직접 게시 방법이 있다.
플랫폼 애플리케이션을 만든 다음 플랫폼 엔드 포인트를 만들고 플랫폼 엔드 포인트에 게시하면 된다.
수신 가능 대상은 Google, GCM, Apple APNS 또는 Amazon ADM 구독자다.
모두 모바일 애플리케이션으로 알림을 수신한다.
Security
기본적으로 전송 중 암호화와 KMS 키를 사용한 저장 데이터 암호화가 있고 클라이언트가 SNS에 암호화된 메시지를 보내려는 경우를 위한 클라이언트 측 암호화가 있다.
액세스 제어는 IAM 정책 중심이다.
모든 SNS API가 IAM 정책으로 규제되기 때문이다.
S3 버킷 정책과 매우 유사한 SNS 액세스 정책을 정의할 수 있다.
SNS 토픽에 교차 계정 액세스 권한을 갖거나 S3 이벤트와 같은 서비스가 SNS 토픽에 작성할 수 있도록 허용하려는 경우 유용하다.
SNS + SQS Fan Out
SNS 토픽에 메시지를 전송한 후 다수의 SQS 큐가 이 SNS 토픽을 구독하게 해보자.
다수의 Queue는 구독자로서 SNS로 들어오는 모든 메시지를 받는다.
이는 완전히 분리된 모델이며 데이터도 손실되지 않는다.
SQS로 작업을 다시 시도할 수 있을 뿐 아니라 데이터 지속성, 지연 처리도 수행할 수 있다.
게다가 이런 방식으로 SNS 토픽을 구독하도록 더 많은 SQS 큐를 추가할 수도 있다.
이를 위해서는 앞서 살펴봤듯이 SQS 액세스 정책에서 SNS 토픽이 SQS 큐에 쓰기 작업을 할 수 있도록 허용해야 한다.
리전 간 전달도 가능하다.
즉 보안상 가능하다면 한 리전의 SNS 토픽에서 다른 리전의 SQS 큐로 메시지를 보낼 수 있다.
FIFO Topic
Amazon SNS에는 토픽의 메시지 순서를 지정하는 FIFO, 즉 선입 선출 기능이 있다.
여기에서 프로듀서가 메시지 1, 2, 3, 4를 보내고 구독자는 1, 2, 3, 4의 순서로 메시지를 수신하는 SQS FIFO 큐가 된다.
이 SNS FIFO는 SQS FIFO와 유사하다.
메시지 그룹 ID에 따라 순서를 매기고 중복 제거 ID를 활용하거나 내용을 비교하여 중복 데이터를 제거하며 SQS FIFO 큐를 FIFO SNS 토픽의 구독자로 설정한다.
처리량은 제한적이며 SQS FIFO 대기열과 동일하다. SQS FIFO 큐만 SNS FIFO 토픽을 읽어 들일 수 있기 때문이다.
SNS FIFO + SQS FIFO + Fan Out
SQS FIFO를 활용하여 팬아웃을 수행하려면 팬아웃, 순서, 중복 제거가 필요하다.
Message Filtering
팬아웃 패턴과 관련한 SNS의 기능은 SNS에서 메시지 필터링을 할 수 있다는 것이다.
SNS 토픽을 구독할 때 전송되는 메시지를 필터링하는 데 사용되는 JSON 정책이다.
토픽에 어떤 필터링 정책도 없다면 모든 메시지를 받아들이며 이것이 기본 동작이다.
필터링 정책과 SQS 큐도 만들 수 있고 아무 필터링 정책 없이 SNS 토픽에 있는 모든 메시지를 받는 SQS 큐도 만들 수 있다.
Kinesis
Kinesis를 활용하면 실시간 스트리밍 데이터를 손쉽게 수집하고 처리하여 분석할 수 있다.
실시간 데이터에는 애플리케이션 로그, 계측, 웹 사이트 클릭 스트림, IoT 원격 측정 데이터 등 다양하다.
데이터가 빠르게 실시간으로 생성된다면 모두 실시간 데이터 스트림으로 간주할 수 있다.
Kinesis는 네 가지 서비스로 구성되어 있다.
Kinesis Data Stream에서는 데이터 스트림을 수집하여 처리하고 저장한다.
Kinesis Data Firehose에서는 데이터 스트림을 AWS 내부나 외부의 데이터 저장소로 읽어 들인다.
Kinesis Data Analytics에서는 SQL 언어나 Apache Flink를 활용하여 데이터 스트림을 분석한다.
시험에는 나오지 않지만 Kinesis Video Stream에서는 비디오 스트림을 수집하고 처리하여 저장한다.
Kinesis Data Stream
시스템에서 큰 규모의 데이터 흐름을 다루는 서비스다.
Kinesis Data Stream은 여러 개의 샤드로 구성되어 있고 이 샤드는 1번, 2번에서 N번까지 번호가 매겨진다.
이건 사전에 우리가 프로비저닝해야 한다.
예를 들어 Kinesis Data Stream을 시작할 때 스트림을 여섯 개 샤드로 구성하겠다고 결정해야 한다는 의미다.
데이터는 모든 샤드에 분배된다. 샤드는 데이터 수집률이나 소비율 측면에서 스트림의 용량을 결정한다.
프로듀서는 데이터를 Kinesis Data Stream으로 보낸다.
컨슈머는 다양하다. 애플리케이션일 수도 있고 데스크톱이나 휴대전화와 같은 클라이언트일 수도 있고 매우 낮은 수준에서 AWS SDK를 활용하거나 더 높은 수준에서 Kinesis Producer Library (KPL)을 활용하기도 한다.
Kinesis Agent를 활용해서 스트리밍할 서버, 예를 들면 Kinesis 스트림에서 애플리케이션 로그를 처리할 수도 있다.
프로듀서는 모두 동일한 역할을 한다. 매우 낮은 수준에서 SDK에 의존하며 Kinesis Data Stream에 레코드를 전달한다.
레코드는 근본적으로 두 가지 요소로 구성됩니다. 파티션 키와 최대 1MB 크기의 데이터 블롭으로 구성된다.
파티션 키는 레코드가 이용할 샤드를 결정하는 데 사용되고 데이터 블롭은 값 자체를 의미한다.
프로듀서는 데이터를 스트림으로 보낼 때 초당 1MB를 전송하거나 샤드당 1초에 천 개의 메시지를 전송할 수 있다.
데이터가 스트림에 들어가면 많은 컨슈머가 이 데이터를 사용한다.
컨슈머는 다양하다. SDK에 의존하거나 높은 수준에서는 Kinesis Client Library, KCL에 의존하는 애플리케이션이 있다.
Kinesis 스트림에서 서버리스로 처리하려는 경우 Lambda 함수도 가능하다.
Kinesis Data Firehose도 있고 Kinesis Data Analytics도 있다.
컨슈머가 레코드를 받으면 여기에는 파티션 키, 샤드에서 레코드의 위치를 나타내는 시퀀스 번호, 데이터 자체를 의미하는 데이터 블롭이 있다.
Kinesis Data Stream에는 여러 소비 유형이 존재한다.
샤드마다 초당 2MB의 처리량을 모든 컨슈머가 공유할 수 있다. 아니면 컨슈머마다 샤드당 1초에 2MB씩 받을 수도 있다.
효율성을 높인 소비 유형, 즉 효율성을 높인 팬아웃 방식
정리하면 프로듀서가 Kinesis Data Stream에 데이터를 전송하고 데이터는 잠시 거기에 머물면서 여러 컨슈머에게 읽힌다.
특징
보존 기간은 1일에서 365일 사이로 설정할 수 있다. 즉, 데이터를 다시 처리하거나 확인할 수 있다.
데이터가 일단 Kinesis로 들어오면 삭제할 수 없으며 이러한 특징을 불변성이라고 한다.
또한 데이터 스트림으로 메시지를 전송하면 파티션 키가 추가되고 파티션 키가 같은 메시지들은 같은 샤드로 들어가게 되어 키를 기반으로 데이터를 정렬할 수 있다.
프로듀서는 SDK, Kinesis Producer Library (KPL), Kinesis Agent를 사용하여 데이터를 전송할 수 있고 컨슈머는 Kinesis Client Library (KCL)나 SDK를 써서 직접 데이터를 작성할 수 있다.
아니면 AWS에서 관리하는 Lambda나 Kinesis Data Firehose, Kinesis Data Analytics를 활용할 수도 있다.
Capacity Modes
Kinesis Data Stream에는 두 가지 용량 유형이 있다.
먼저 전통적인 용량 유형으로 프로비저닝 유형이 있다.
여기에서는 프로비저닝할 샤드 수를 정하고 API를 활용하거나 수동으로 조정한다.
Kinesis Data Stream에 있는 각 샤드는 초당 1MB나 1천 개의 레코드를 받아들이고 출력량의 경우에는 각 샤드가 초당 2MB를 받아들인다.
이는 일반적인 소비 유형이나 효율성을 높인 팬아웃 방식에 적용할 수 있다.
다만 샤드를 프로비저닝할 때마다 시간당 비용이 부과되므로 사전에 심사숙고해야 한다.
두 번째는 온디맨드 유형이다.
여기에서는 프로비저닝을 하거나 용량을 관리할 필요가 없다. 시간에 따라 언제든 용량이 조정된다.
기본적으로는 초당 4MB 또는 초당 4천 개의 레코드를 처리하지만 이 용량은 지난 30일 동안 관측한 최대 처리량에 기반하여 자동으로 조정된다.
이 유형에서는 시간당 스트림당 송수신 데이터양(GB 단위)에 따라 비용이 부과된다.
두 유형은 비용 산정 방식이 다르다.
어쨌든 사전에 사용량을 예측할 수 없다면 온디맨드 유형을 선택하자.
하지만 사전에 사용량을 계획할 수 있다면 프로비저닝 유형을 선택하자.
보안
IAM 정책을 사용하여 샤드를 생성하거나 샤드에서 읽어 들이는 접근 권한을 제어할 수 있다.
HTTPS로 전송 중 데이터를 암호화할 수 있으며 미사용 데이터는 CMS로 암호화할 수 있다.
클라이언트 측에서 데이터를 암호화하거나 해독할 수 있으며 이를 클라이언트 측 암호화라고 한다.
이는 직접 데이터를 암호화하고 해독해야 하기 때문에 수행하기 더 어렵다. 하지만 그만큼 보안이 더 강화된다.
Kinesis에서 VPC 엔드포인트를 사용할 수 있다.
이를 이용하면 Kinesis에 인터넷을 거치지 않고 프라이빗 서브넷의 인스턴스에서 직접 손쉽게 접근할 수 있다.
마지막으로 모든 API 요청은 CloudTrail로 감시할 수 있다.
Data Firehose
프로듀서에서 데이터를 가져올 수 있는 유용한 서비스이며, 프로듀서는 Kinesis Data Stream에서 본 무엇이든 될 수 있다.
즉, 애플리케이션, 클라이언트, SDK, KPL, Kinesis Agent 모두 Kinesis Data Firehose로 생산할 수 있다.
Kinesis Data Stream과 아마존 CloudWatch (로그 및 이벤트) 그리고 AWS IoT도 Kinesis Data Firehose로 생산할 수 있다. 이 모든 애플리케이션이 Kinesis Data Firehose로 데이터를 전송하면 Kinesis Data Firehose는 람다 기능을 활용해 데이터를 변환할지 선택할 수 있는데 이는 옵션이다.
일단 데이터를 변환하면 배치로 수신처에 쓸 수 있다.
Kinesis Data Firehose는 소스에서 데이터를 가져오는데 주로 Kinesis Data Stream이다. 그리고 수신처에 데이터를 쓸 수 있다.
이때 Kinesis Data Firehose가 데이터 쓰는 법을 알기 때문에 별도로 코드를 쓸 필요가 없다.
Kinesis Data Firehose의 수신처는 세 종류가 있다.
첫 번째 범주는 AWS 수신처다. (매우 중요)
S3가 있다. 모든 데이터를 아마존 S3에 쓸 수 있다.
데이터 웨어하우스인 아마존 레드시프트도 있는데, 여기에 데이터를 쓸 때는 아마존 S3에 데이터를 쓰면 Kinesis Data Firehose가 복사 명령어를 내보낸다. 이 복사 명령어가 아마존 S3의 데이터를 아마존 레드시프트로 복사하는 것이다.
AWS 범주의 마지막 수신처는 아마존 ElasticSearch다.
써드 파티 파트너 수신처도 있다. 데이터독, 스플렁크, 뉴렐릭, 몽고DB 다양한 수신처로 Kinesis Data Firehose가 데이터를 전송할 수 있다.
마지막으로, 만약 HTTP 엔드포인트가 있는 자체 API를 보유하고 있다면 Kinesis Data Firehose를 통해 커스텀 수신처로 데이터를 보낼 수 있다.
데이터가 이러한 수신처로 전송되고 나면 우리에게는 두 가지 옵션이 있다.
모든 데이터를 백업으로 S3 버킷에 보내거나, 혹은 수신처에 쓰이지 못한 데이터를 실패 S3 버킷에 보낼 수도 있다.
Kinesis Data Firehose는 완전 관리형 서비스다.
관리가 필요하지 않으며, 자동으로 용량 크기가 조정되고, 서버리스이므로 관리할 서버가 없다.
Kinesis Data Firehose를 통하는 데이터에 대해서만 비용을 지불하면 되므로 아주 효율적이다.
근 실시간으로 이루어집니다. 왜 근 실시간이냐면 Kinesis Data Firehose에서 수신처로 데이터를 배치로 쓰기 때문이다.
전체 배치가 아닌 경우 최소 60초의 지연시간이 발생하거나, 데이터를 수신처에 보내는 데 한 번에 적어도 1MB의 데이터가 있을 때까지 기다려야 한다. 그러므로 실시간 서비스가 아니라 실시간에 가까운 서비스다.
Kinesis Data Stream VS Kinesis Data Firehose
시험에 Kinesis Data Stream을 사용할 경우, Kinesis Data Firehose를 사용해야 하는 경우를 구분해야 하는 문제가 나온다.
Kinesis Data Stream은 데이터를 대규모로 수집할 때 쓰는 스트리밍 서비스고, 프로듀서와 컨슈머에 대해 커스텀 코드를 쓸 수 있다.
실시간으로 이루어지며약 70ms 혹은 200ms 정도의 지연시간이 발생한다.
용량을 직접 조정할 수 있어 샤드 분할이나 샤드 병합을 통해 용량이나 처리량을 늘릴 수 있다.
제공한 용량만큼 비용을 지불하면 되며, 데이터는 1일에서 365일간 저장된다. 덕분에 여러 소비자가 같은 스트림에서 읽어 올 수 있고, 반복 기능도 지원된다.
Kinesis Data Firehose도 수집 서비스로 데이터를 아마존 S3나 레드시프트, ElasticSearch 써드 파티 파트너나 자체 HTTP로 스트리밍해준다.
완전 관리되며, 서버리스이고, 근 실시간으로 이루어진다.
자동으로 용량 조정되어 관련해 걱정할 필요 없고, Kinesis Data Firehose를 통과하는 데이터에 대해서만 비용을 지불하면 된다.
데이터 스토리지가 없어 Kinesis Data Firehose의 데이터를 반복하는 기능은 지원되지 않는다.
Kinesis의 SQS FIFO에 대한 데이터 정렬
SQS FIFO는 그룹 ID 숫자에 따른 동적 소비자 수를 원할 때 사용하면 좋은 모델이다.
Kinesis 데이터 스트림을 사용할 경우는 예를 들어 트럭 10,000대가 많은 데이터를 전송하고 또 Kinesis 데이터 스트림에 샤드당 데이터를 정렬할 때다.
Amazon MQ
MQTT, AMQP 등과 같은 기존에 쓰던 프로토콜을 사용하고 싶을 수 있는데 이때 Amazon MQ를 쓴다.
RabbitMQ와 ActiveMQ 두 가지 기술을 위한 관리형 메시지 브로커 서비스다.
RabbitMQ와 ActiveMQ는 온프레미스 기술로 앞서 설명했던 개방형 프로토콜 액세스를 제공한다.
Amazon MQ를 이용하면 해당 브로커의 관리형 버전을 클라우드에서 사용할 수 있다.
먼저 Amazon MQ는 무한 확장이 가능한 SQS나 SNS처럼 확장성이 크지는 않다.
Amazon MQ는 서버에서 실행되므로 서버 문제가 있을 수 있다.
고가용성을 위해 장애 조치와 함께 다중 AZ 설정을 실행할 수 있다.
Amazon MQ는 SQS처럼 보이는 큐 기능과 SNS처럼 보이는 토픽 기능을 단일 브로커의 일부로 제공한다.
Amazon MQ의 고가용성은 어떨까요?
us-east-1라는 리전에 us-east-1a와 us-east-1b 두 개의 가용 영역이 있다고 가정해보자.
영역 하나는 활성 상태 그리고 또 다른 영역은 대기 상태다.
이제 두 영역에 각각 활성, 대기 상태인 Amazon MQ 브로커를 추가한다.
장애 조치 실행을 위해 백엔드 스토리지에 Amazon EFS도 정의해야 한다.
EFS는 네트워크 파일 시스템으로 다중 가용 영역에 마운트할 수 있다.
이렇게 설정하면 장애 조치가 일어날 때마다 대기 상태 영역 역시 Amazon EFS에 마운트되므로 첫 번째 활성 큐와 동일한 데이터를 가질 수 있고 따라서 장애 조치도 올바르게 실행된다.
클라이언트가 Amazon MQ 브로커와 통신해서 장애 조치가 실행되는 경우에도 Amazon EFS 덕분에 데이터가 저장된다.
