Kafka
Kafka란, 고성능 데이터 파이프라인, 스트리밍 분석, 데이터 통합 및 기타 여러 중요한 애플리케이션을 위해 오픈 소스 분산 이벤트 스트리밍 플랫폼 입니다.
Apache Kafka는 주로 실시간 데이터 스트리밍 파이프라인을 구축하는데 사용됩니다.
Kafka 탄생 배경
Kafka는 기존 메시지 대기열 시스템으로는 충족할 수 없는 내부 스트림 처리 요구사항을 서비스하기 위해 LinkedIn에서 만들어졌습니다.
첫 번째 버전은 2011년 1월에 출시되었고 빠르게 인기를 얻어 이후 Apache Foundation의 가장 인기 있는 프로젝트 중 한개가 되었습니다.
현재는 IBM, Yelp, Netflix 등과 같은 회사의 도움을 받아 Confluent가 주로 유지관리를 하고 있습니다.
LinkedIn의 초기 테이터 처리 시스템
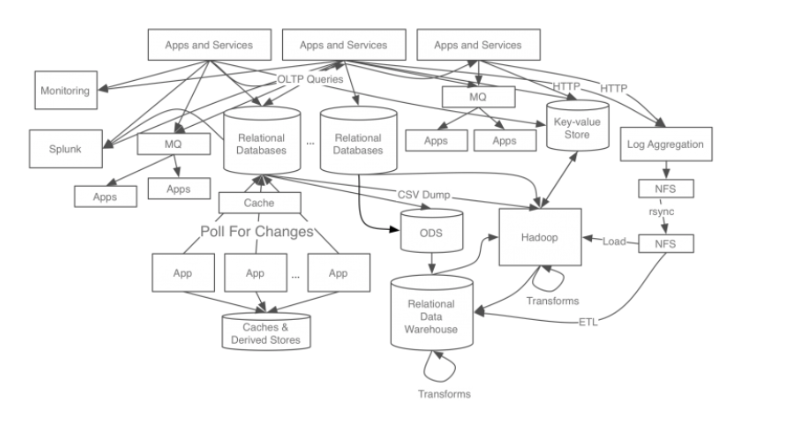
기존 시스템의 문제
각 애플리케이션과 DB가 end-to-end로 연결되어 있고, 요구사항이 늘어남에 따라 시스템 복잡도가 높아지면서 문제가 발생하였습니다.
-
시스템 복잡도 증가
- 통합된 전송 영역이 없어 데이터 흐름 파악이 없고, 시스템 관리가 어렵습니다.
-
특정 장애 발생시 장애 대응에 대한 시간이 증가
- 장애 발생시 장애와 연관된 모든 애플리케이션의 확인해야 합니다.
-
관리 포인트가 늘어나고 작업 시간 증가
- 연결된 애플리케이션의 side effect가 없는지 확인해야 합니다.
이러한 문제를 해결하기 위해 모든 이벤트/데이터 흐름을 중앙에서 관리하는 카프가가 개발되었습니다.
LinkedIn 카프카 적용 후
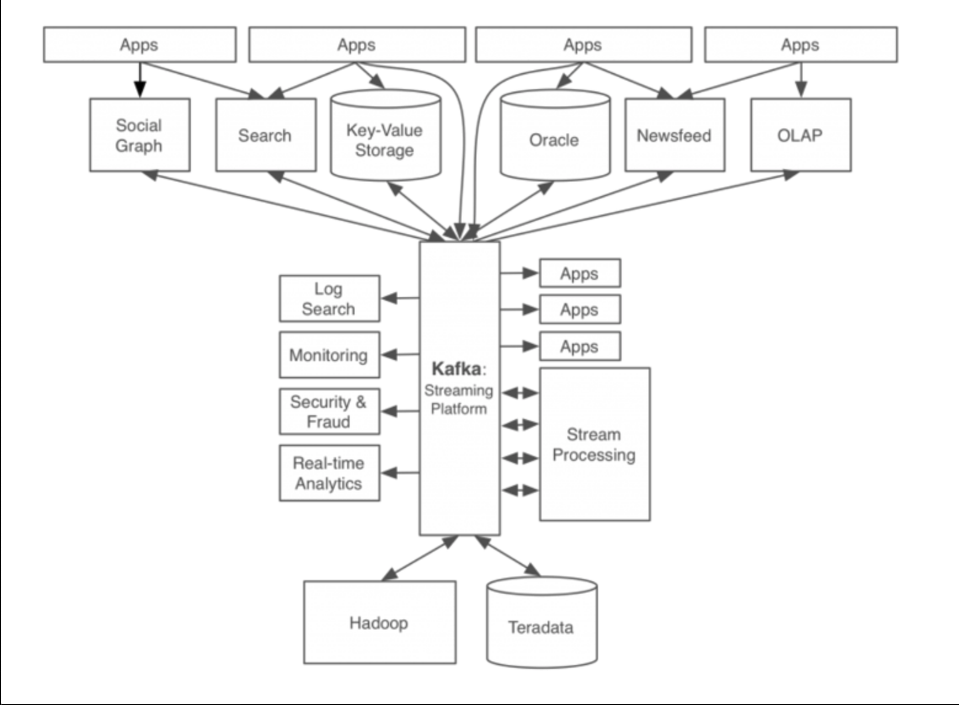
모든 이벤트/데이터의 흐름을 중앙에서 관리할 수 있게 되었습니다.
새로운 서비스/시스템이 추가되어도 Kafka가 제공하는 표준 포맷으로 연결하면 되기에 확장성과 신뢰성이 증가합니다.
개발자는 서비스간의 연결이 아닌 서비스 비즈니스 로직에 집중할 수 있게 되었습니다.

문제 해결과 개선 과제를 수행하며 성장을 추구하는 것을 좋아합니다.