Redis란
In-Memory 기반의 Dictionary(key-value) 구조 데이터 관리 Server 시스템이다.
메모리(dram)에서 데이터를 처리하기 때문에 작업 속도가 상당히 빠르다.
Redis는 다양한 데이터 구조를 지원함으로써 DB, Cache, Message Queue 용도로 사용될 수 있다.
Redis 특징
1. In-Memory Database
일반적인 RDB들은 디스크에서 데이터를 저장하고 관리하지만, Redis는 주기억장치인 ram에서 관리합니다.
데이터를 저장하고 조회할 때, 하드디스크를 거치지 않고 메모리 내부에서 처리되기 때문에 훨씬 더 높은 퍼포먼스를 보입니다.
하지만, 데이터를 메모리에 저장하기 때문에 서버가 다운되었을때 데이터가 유실될 수 있는 가능성이 존재합니다.
2. Persistent on disk
Redis는 데이터 유실 가능성이 존재하기에 영속적인 데이터 보존이 가능하다.
Redis에서는 데이터를 저장하는 방법이 RDB(snapshop), AOF(Append only file) 두 가지 방식이 존재한다.
2-1 RDB(Snapshop)
RDB 방식은 특정 시점에 전체 데이터를 디스크에 저장하는 방식이다.
주로 백업과 유사한 방식이라고 생각하면 된다.
실행 주기가 길기 때문에 해당 시점에 에러가 발생하게 된다면 에러 발생 시점에 데이터가 유실될 수 있다.
프로세스 포크 방식으로 이용되기 때문에 메모리가 급등할 수 있다.(BGSAVE 방식)
Process fork
fork는 Copy-on-Write(COW) 메모리 관리 방식이기에 스냅샷을 만들 때 모든 데이터가 변경되었을 경우, 모든 데이터를 복사해야 하므로 메모리 사용량이 급증할 수 있다.
2-2 AOF(Append Only File)
AOF 방식은 쓰기 작업의 명령이 실행될때 마다 데이터를 파일에 기록하는 방식이다.
RDB보다는 중도 복구에 용이한 장점이 있다.
하지만, 데이터 용량을 더 많이 사용하게 되고 디스크 쓰기 작업이 많아 성능에 영향을 미칠 수 있다.
사용 전략
Persist 구성을 할 때 RDB, AOF 방식을 혼용해서 사용할 수 있다.
기본 설정으로는 RDB만 사용하게 설정되어 있고, 단순 캐시 용도로만 사용한다면 두 옵션 모두 끄고 사용하는 전략을 적용할 수 있다.
3.다양한 데이터 타입을 지원
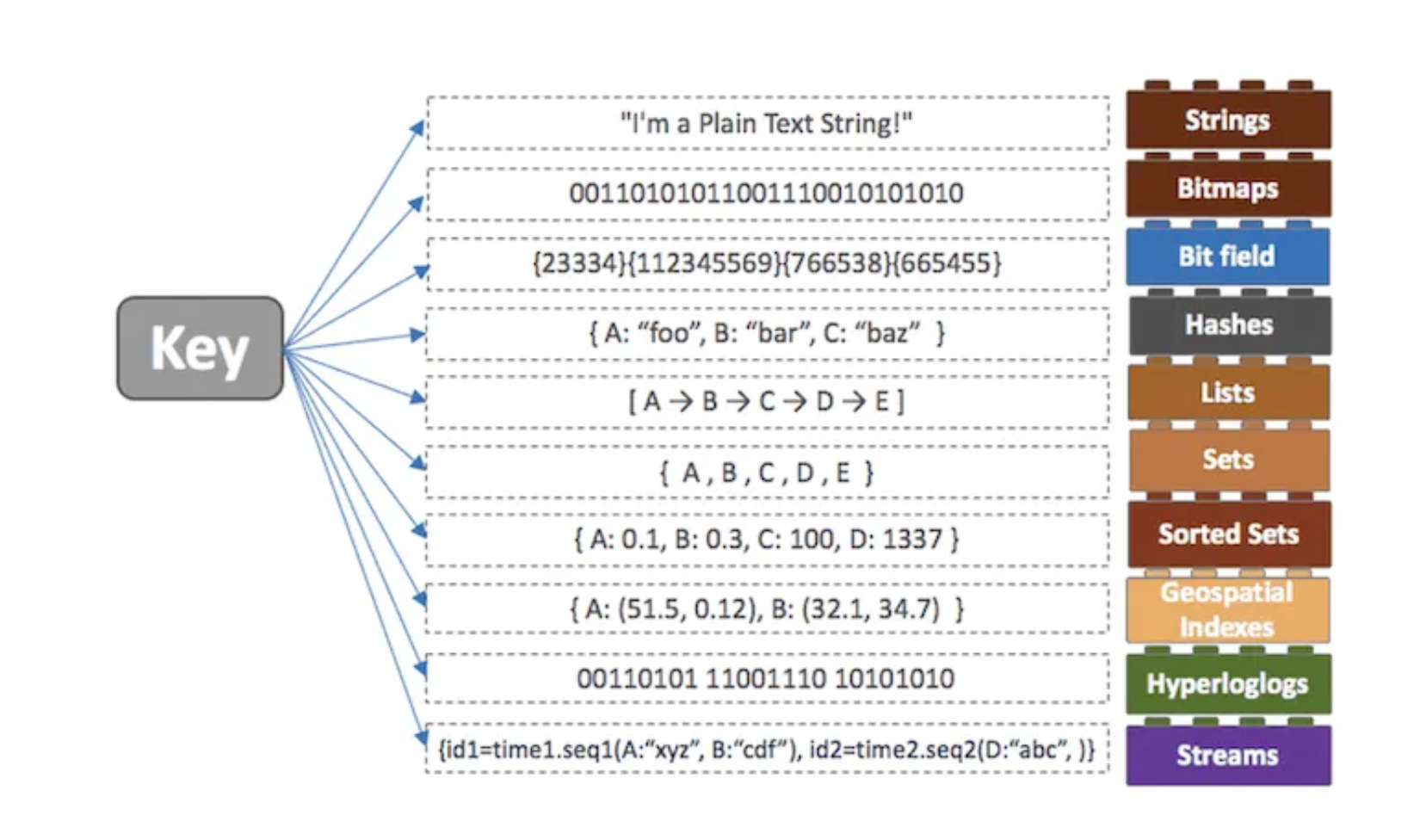
Redis Key-Value 스토리지에서 Value는 단순한 Object가 아니라 다양한 자료구조를 갖고 있다.
대표적으로 String, Set, Sorted Set, Hash, List 등 다양한 타입을 지원한다.
Redis 데이터 타입은 다른 포스팅에서 자세히 다뤄보려고 한다.
4. Single Thread
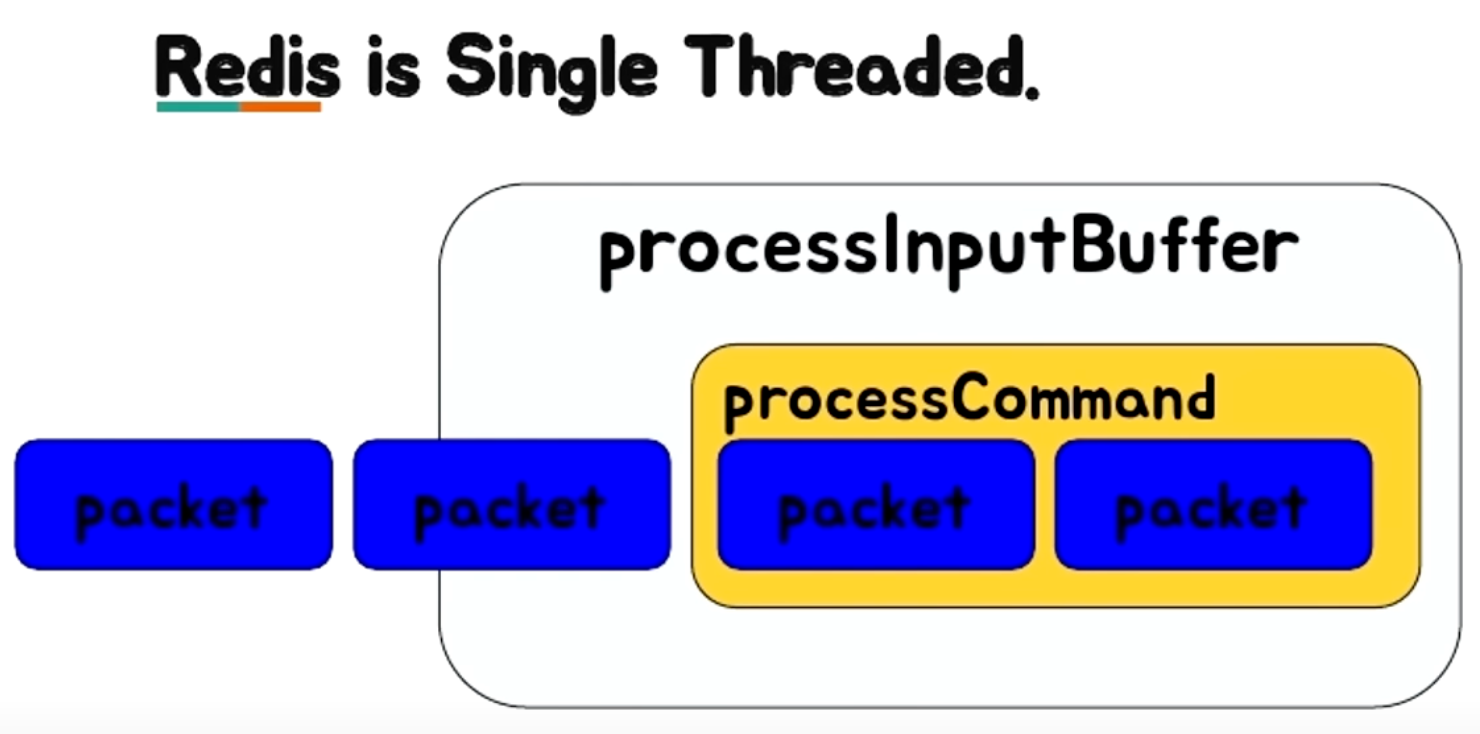
Redis는 Single Thread 기반으로 동작한다.
그래서 한 번에 딱 하나의 명령어만 실행된다. 다만, 외부로부터 요청은 동시에 받을 수 있지만 내부에서는 순차적으로 하나씩 처리한다.
레디스는 6.0v 이후부터는 성능 향상을 위해 스레드 I/O가 도입되었다. I/O 부분에 별도의 다수 스레드를 설정하여 사용하는 것이다.
대표적으로 네트워크 In/Out 부분에서 사용하고 병렬처리 또한 가능하다.
하지만. 여전히 명령어 처리는 Single Thread 구조로 동작하기에 주의해야 한다.
4-1 Single Thread 장점
Single Thread 방식이기에 내부적으로 락을 사용하지 않아도 원자적 실행이 가능하게 한다. 이를 통해 데이터 일관성을 보장할 수 있다.
단일 처리로 인해 병렬처리보다 복잡성을 줄이고 단순함을 유지할 수 있다는 장점이 존재한다.
Redis는 초당 10만건까지 지연없이 처리할 수 있다고 알려져 있다.
4-2 Single Thread 단점
Single Thread이기에 사용한 명령어에 따라 뒤의 작업들이 지연되는 경우가 있을 수 있다.
이는 응답 지연, 서비스 장애까지 이어질 수 있다.
NHN Redis 해당 영상 19분 50초부터 나오는 장애 포인트에서도 Single Thread의 명령어로 인한 주의 할 내용을 확인할 수 있다.
4-3 keys 대신 scan
Single Thread로 동작하기 때문에 keys * 명령어로 모든 키를 조회하게되면 다른 작업에 latency가 발생할 수 있다
그래서 keys 대신 scan 명령어를 사용하면 된다.
scan 0 match * count 100
위 명령어로 keys * 를 대신할 수 있고, next cursor 값을 반환 받으면
scan [next cursor] match * count 100명렁어로 원하는 키를 찾을 수 있다.
참조
https://medium.com/garimoo/%EA%B0%9C%EB%B0%9C%EC%9E%90%EB%A5%BC-%EC%9C%84%ED%95%9C-%EB%A0%88%EB%94%94%EC%8A%A4-%ED%8A%9C%ED%86%A0%EB%A6%AC%EC%96%BC-01-92aaa24ca8cc
https://www.youtube.com/watch?v=mPB2CZiAkKM
