
👉 스테이트풀 서비스
스테이트풀 서비스 패턴 은 퍼시스턴트 식별자, 네트워킹, 스토리지, 순서성 등과 같은 기능을 통해서
분산 스테이트풀 어플리케이션 관리에 이상적이고 강력한 보장을 해줍니다.
따라서 이번 글에서는 스테이트풀 서비스 패턴을 위한 StatefulSet 의 기본 요소를 설명하도록 하겠습니다.
🍏 문제점
지금까지 쿠버네티스 패턴 시리즈에서 기본 요소로 여러가지를 살펴보았습니다.
이들의 공통적인 특징은 두 가지가 있습니다.
- 어플리케이션은 교체 가능하며 대체 가능한 컨테이너로 구성된 Stateless 로 취급
- 모두가 Twelve-Factor App 원칙을 준수
이러한 Stateless 어플리케이션 위주의 플랫폼은 Stateful 어플리케이션 같이
고유하며 오래 지속되는 특성을 지니는 어플리케이션을 관리하기가 어렵습니다.
실제로 확장성이 뛰어난 모든 Stateless 서비스 뒤에는 일반적인 데이터 저장소 형태의 Stateful 서비스가 있으며
쿠버네티스의 초창기 해결책은 Statefull 서비스 는 퍼블릭 클라우드, 온프레미스 하드웨어와 같이
비 클라우드 네이티브 메커니즘으로 관리하였습니다.
따라서 모든 기업들이 수 많은 Stateful 서비스 를 사용한다는 점을 고려할 때
범용 클라우드 네이티브 플랫폼으로 알려진 쿠버네티스에 있어서 상당한 한계점이 됩니다.
그렇다면 쿠버네티스에서 Stateful 서비스 를 구현하기 위해서 어떻게 해야할까요?
기본적으로 단일 어플리케이션의 경우 특히 replicas=1 로 ReplicaSet 을 생성하고
Service 를 활용하고, PVC 와 PV 로 영구적인 저장소를 사용한다면 어느정도 해결할 수 있습니다.
하지만 ReplicaSet 은 최대한 하나 라는 의미를 보장하지 않기 때문에 데이터 손실로 이어질 수 있습니다.
또한 여러 인스턴스로 구성된 Distributed Stateful App 은 많은 부분의 보장이 필요합니다.
따라서 Stateful App 을 위한 전제조건 몇 가지를 살펴보도록 하겠습니다.
1) 스토리지
Distributed Stateful App 을 만드는 것은 Replicas 수를 늘려 만들 수 있습니다.
하지만 이런 경우에 스토리지 요구사항을 정의하는 것은 어렵습니다.
일반적으로 Distributed Stateful App 은 모든 인스턴스에 대해 전용의 PV 가 필요합니다.
하지만 만약 replicas=3 이고 PVC 정의를 갖춘 ReplicaSet 이 있다면
3개의 파드는 모두 동일한 PV에 연결될 것입니다.
이를 해결하기 위한 방법을 생각해보면 다음과 같습니다.
1-1) 공유 스토리지를 이용하고 스토리지를 하위 폴더로 분할하여 사용
이 경우에는 가능하지만 단일 스토리지로 단일 장애지점을 만들며
스케일 중에 파드 수가 변경될 때 오류가 발생할 수 있습니다.
또한 스케일 중에 데이터 손상이나 손실을 방지하기가 어려울 수 있습니다.
1-2) 모든 인스턴스에 대해 별도의 ReplicaSet(replicas=1) 을 갖는 방법
이 경우에는 모든 ReplicaSet 은 PVC 와 전용 스토리지를 가지고 있어야 합니다.
따라서 스케일 중에 경우 새로운 ReplicaSet, PVC, Service 를 수동으로 생성하거나 지워야합니다.
또한 Stateful 어플리케이션 의 모든 인스턴스를 하나로 관리하는 단일 추상화가 없습니다.
따라서 스토리지 요구사항 을 만족시키기 위한 새로운 것이 필요합니다.
2) 네트워킹
스토리지 요구사항과 유사하게 Distributed Stateful App 은 안정적인 네트워크 식별자 가 필요합니다.
Staeteful 어플리케이션 은 스토리지에 관련 데이터를 저장하는 것 외에도
Hostname 과 그들의 Peer 연결 세부사항 같은 Configuration 을 저장해야합니다.
👍 즉, ReplicaSet 의 파드 IP 주소처럼 동적으로 변경되면 안 되고 예측 가능한 주소를 사용해야합니다.
이에 대한 간단한 해결 방안은 replicas=1 로 설정된 ReplicaSet 에 Service 를 생성하는 것 입니다.
하지만 이러한 설정을 관리하는 것은 수동 작업이며 어플리케이션 자체가 안정적인 Hostname 을 가질 수 없습니다.
따라서 Steteful 어플리케이션 을 위한 각 파드 별로 안정적인 네트워크 식별자 에 대한 요구사항이 있습니다.
3) 식별자
지금까지 설명한 요구사항에서 알 수 있듯이 Stateful 어플리케이션 은
모든 인스턴스가 제각기 고유하고 자신의 고유한 식별자를 필요로 합니다.
하지만 ReplicaSet 으로 생성된 파드는 임의의 이름을 가지기 때문에
고유한 식별자를 유지할 수 없습니다.
4) 순서성
고유한 식별자 외에도 Stateful 어플리케이션 은 인스턴스의 순서가 보장되어야 합니다.
여기서 순서란 일반적으로 인스턴스가 다운되는 순서입니다.
ReplicaSet 의 경우 파드를 시작하거나 제거할 때 특정 순서를 따르지 않습니다.
따라서 Stateful 어플리케이션 을 위한 인스턴스의 순서성 에 대한 요구사항이 있습니다.
5) 기타 요구사항
위에서 살펴본 스토리지, 네트워킹, 식별자, 순서성 등은
클러스터된 Stateful 어플리케이션에서 공통적으로 요구하는 사항입니다.
하지만 이 외에도 Stateful 어플리케이션 관리에는 상황에 따라 많은 요구사항이 수반되기도 합니다.
다음은 이러한 요구사항에 대한 예시입니다.
- Quorum 기반과 같이 최소 수의 인스턴스가 필요한 경우
- 순차적인 것이 아닌 Parallel Deployment에 적합한 경우
- 중복 인스턴스를 허용하지 않는 경우
위와 같은 요구사항들은 필수는 아니지만 필요할 수 있습니다.
🍏 해결책
이러한 문제들을 해결하기 위해 쿠버네티스는 StatefulSet 를 지원합니다.
이번 글에서는 Stateful 어플리케이션을 위한 5가지 요구사항을
StatefulSet은 어떠한 방식으로 해결하였는지 살펴보도록 하겠습니다.
1) 스토리지
위에서 살펴보았듯이 대부분의 Stateful 어플리케이션 은 상태를 저장하므로
인스턴스마다 전용 PV 가 필요합니다.
이를 해결하기 위해 StatefulSet 은 volumeClaimTemplates 을 사용합니다.
StatefulSet 은 사전에 정의된 PVC 를 참조하는 것이 아니라
파드를 생성할 때 volumeClaimTemplates 을 사용하여 동적으로 PVC 를 생성합니다.
따라서 모든 파드는 replicas 를 변경하여 스케일 중이거나 초기 생성 중에 자체 전용 PVC 를 얻을 수 있습니다.
여기서 PV 는 관리자가 사전에 Provisioning 하거나
요청된 스토리지 클래스를 기반으로 동적으로 PV를 Provisioning 하도록 준비해야합니다.
주의해야할 점은 스케일을 줄이는 경우 파드는 삭제되지만 PVC 는 삭제되지 않으므로
PV 를 재사용하거나 삭제할 수 없으며 해당 스토리지를 해제할 수 없습니다.
이 동작은 의도적으로 설계되었으며 Stateful 어플리케이션 는 스토리지가 중요하며
실수로 인해서 데이터 손실이 발생하지 않아야 하기 때문입니다.
따라서 데이터의 손실이 없다는 가정하에 PVC 를 수동으로 삭제하면 PV 재사용이 가능합니다.
2) 네트워킹
StatefulSet 을 통해서 만들어진 파드는 각각의 고정된 식별자가 있습니다.
이에 따라서 위의 예시에서 생성된 두 파드의 이름은 rg-0 과 rg-1 이 됩니다.
다음은 이를 통해서 Headless Service 를 만들기 위한 yaml 입니다.
apiVersion: v1
kind: Service
metadata:
name: random-generator
spec:
clusterIP: None
selector:
app: random-generator
ports:
- name: http
port: 8080Headless 서비스 를 만들기 위해서는 .spec.clusterIP 필드를 None 으로 설정하면됩니다.
셀렉터가 있는 Headless 서비스 를 만들게 되면 다음과 같은 일이 일어납니다.
- Service 는 API 서버에 Endpoint 레코드 를 생성
- Service 에 속하는 파드는 A Record 를 반환하는 DNS 항목을 생성
이를 통해서 다음과 같은 두 가지 이점이 있습니다.
1) 직접적으로 각 파드에 접근 가능
만약 위의 예시와 같이 random-generator 서비스를 생성하였고 Default 네임스페이스인 경우
rg-0.random-generator.default.svc.cluster.local 을 통해 rg-0 파드에 도달 할 수 있습니다.
2) SRV 레코드에 대한 DNS 참조 가능
만약 위의 예시와 같이 random-generator 서비스를 생성하였고 Default 네임스페이스인 경우
dig SRV random-generator.default.svc.cluster.local 을 통해
Service 에 등록된 모든 실행 중인 파드를 발견할 수 있습니다.
따라서 Stateful 어플리케이션 의 특정 파드로 접근 해야하는 요구사항을 해결할 수 있습니다.
3) 식별자
StatefulSet 에서 식별자는 고유한 이름으로 StatefulSet의 이름을 기반으로 만들어집니다.
식별자가 정해지면 이를 이용해서 PVC 의 이름을 지정하거나
Headless 서비스 를 통해서 특정 파드에 도달하는 작업을 할 수 있습니다.
다음은 쿠버네티스의 Distributed Stateful App 을 그림으로 나타낸 것입니다.
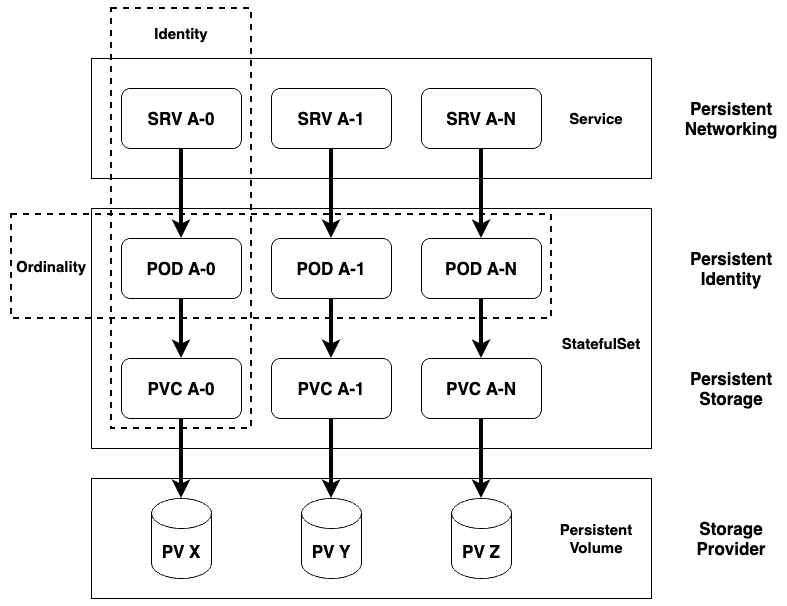
이 그림에서 식별자를 통해서 Service 부터 PVC 의 이름까지 예측할 수 있는 것을 볼 수 있습니다.
따라서 Stateful 어플리케이션 의 고유한 식별자 에 대한 요구사항을 해결할 수 있습니다.
4) 순서성
고유하고 오래 지속되는 식별자 외에도 StatefulSet 에서는 파드의 고유한 순서가 정해져있습니다.
이 순서는 일반적으로 파드가 스케일이 in-out 되는 순서에 영향을 줍니다.
위의 그림과 같이 파드는 순서를 나타내는 접미어(POD A-N) 를 붙인 이름을 가집니다.
따라서 파드는 생성될 때 0번부터 차례대로 시작되며
앞 번호의 파드가 생성되지 않으면 뒷 번호의 파드도 생성되지 않습니다.
또한 파드가 스케일 in 될 때는 역순으로 n번부터 다운됩니다.
이를 통해서 Stateful 어플리케이션 의 순서성 에 대한 요구사항을 해결할 수 있습니다.
특히 데이터 Partitioning 과 Distribution 이 인스턴스 사이에 연관된 경우에 유용합니다.
5) 기타 요구사항
StatefulSet 에서는 필수 요구사항뿐만 아니라
어플리케이션의 요구에 맞게 Custom으로 요구사항을 지정할 수 있는 방법이 있습니다.
따라서 Stateful 어플리케이션 에 적합하도록 세심한 고려가 필요하며
Custom 요구사항을 위한 StatefulSet 의 기능을 알아보도록 하겠습니다.
1) Partition Update
StatefulSet 은 순서성을 통해서 파드가 스케일할 때 순서를 보장한 것을 살펴보았습니다.
해당 경우에는 RollingUpdate 파드를 업데이트하기 위해 모든 파드를 다운시켜야합니다.
따라서 업데이트 동안 특정 수의 인스턴스가 그대로 유지되도록 보장하도록 할 수 있습니다.
이는 .spec.updateStrategy.rollingUpdate.partition 필드에 번호를 지정하여 달성할 수 있습니다.
만약 해당 필드에 값이 2 이며 replicas 는 5 인 경우 2 ~ 4 순서의 파드만 업데이트되며
2개의 파드 0 ~ 1 은 다운되지 않고 유지되도록 할 수 있습니다.
결과적으로 Canary Release 와 같게 됩니다.
2) Parallel Deployment
StatefulSet 에서 순서성을 통해서 제약되는 것중 하나는 파드를 병렬적으로 시작하거나 종료할 수 없다는 것입니다.
이를 위해서 StatefulSet 은 .spec.podManagementPolicy 를 통해서 해결하였습니다.
해당 필드가 활성화 된다면 순차적으로 파드를 실행하거나 종료하는 것이 아니라 병렬적으로 처리할 수 있습니다.
따라서 StatefulSet 어플리케이션 에서 순차적 처리가 필요하지 않다면 운영 절차의 속도를 높일 수 있습니다.
3) At-Most-One
StatefulSet 에서 고유성은 가장 기본적인 속성 중 하나입니다.
이를 통해서 중복되는 인스턴스를 최대한 줄여줍니다.
쿠버네티스 패턴 - 10장 싱글톤 서비스 에서 설명한 것과 같이 ReplicaSet 의 경우에는
replica 에 설정한 값을 유지하려고 노력하지만 그러지 않은 경우가 있습니다.
반면에 StatefulSet 은 순서성에 의해서 파드의 생성이 정해져있기 때문에
중복 파드가 없도록 가능한 모든 체크를 수행합니다.
따라서 ReplicaSet 은 최소한 N개 보장 을 제공하며
StatefulSet 은 최대한 하나 보장 을 제공합니다.
하지만 다음과 같은 예외사항으로 파드가 중복 수행되는 경우가 있습니다.
- 노드가 실행 중이지만 API 서버에서 연결할 수 없는 노드 자원 객체를 삭제
kubectl delete pods _<pod>_ --grace-period=0 --force수행
따라서 중복된 파드가 생겼는지 세밀하게 관찰할 필요가 있습니다.
🍏 정리
이번 글을 통해서 Stateful 어플리케이션 을 관리하기 위해
필요한 몇 가지 요구사항과 해결방안을 살펴보았습니다.
Stateful 어플리케이션 에 필요한 요구사항이 많은 만큼
StatefulSet 에도 고려해야하는 부분이 많습니다.
따라서 이런 부분들을 정확하게 짚고 넘어가지 않으면
운영하는 Stateful 어플리케이션 에 큰 결점이 생길 수 있습니다.
👉 Reference
