
이번 글에서는 간단한 BI(Business Intelligence) 분석을 진행하며 비즈니스 질문에 대한 답을 찾아가는 과정을 다뤄보고자 한다.
BigQuery 언어에 익숙하지 않더라도 우선은 분석흐름에 익숙해지는 것을 목표로 제시된 쿼리들을 하나씩 실행하며 결과를 확인해 보도록 하자.
■ 실습 주제 (Hands-On Topic)
Kaggle에서는 해마다 경진대회에 참여하는 데이터 과학자들을 대상으로 설문을 실시하며 그 결과를 공유한다.
설문에는 데이터 과학자들의 간단한 프로파일 통계와 경력 기간, 급여, 교육 수준 및 선호 도구 등 다양한 항목이 포함되어 있다.

자세한 내용은 아래 링크를 참조하자.
여러 설문 항목 중 이번 핸즈온에서는 아래와 같은 질문에 대한 답을 찾고자 한다.
▷ 핵심 비즈니스 질문들(Key Business Questions)
- 2021년도에 분석가들로부터 가장 많이 선택받은 언어는?
- Kaggle 분석가들은 몇 가지 언어로 분석을 진행할까?
- 어떤 언어조합이 가장 많이 선호되고 있을까?
■ Hands-On
앞서의 비즈니스 질문에 대한 답을 찾는 과정에는 BigQuery에 데이터를 적재하고 분석이 용이한 형태로 변환하는 ELT(Extract-Load-Transform) 과정이 수반된다.
▷ 데이터 준비 (Data Preparation)
우선 Kaggle 사이트에서 설문 데이터를 다운로드 받고 개략적으로 데이터의 내용과 형식을 파악하도록 한다.
- Data Source - Kaggle Survey 2021 에서 원본 파일을 다운로드하고 압축을 해제한다.
- EDA(데이터탐색)
- kaggle_survey_2021_responses.csv 에서 대략적인 데이터 현황과 비즈니스 질문과 관련된 컬럼의 내용을 살핀다.
- CSV의 경우 분리자(delimeter)와 헤더 및 컬럼 속성 등을 파악해 둔다.
- 데이터 업로드
- 로컬PC의 파일을 바로 BigQuery에 업로드도 가능하나 파일 크기의 제한(10MB)이 있다.
- 이로 인해 큰 파일은 Clodud Storage에 업로드 후 BigQuery로 적재하는 것이 일반적이다.
- 이번 핸즈온에서 Cloud Storage 대신 Google Drive에 파일을 올려 실습토록 하겠다.
- Drive URI 확인 - BigQuery에 외부 데이터 소스의 위치를 알려줄 때 필요한 정보로 사전에 파악해 둔다.
- 업로드된 파일에서 마우스 오른쪽 클릭 후
Get link선택한다.
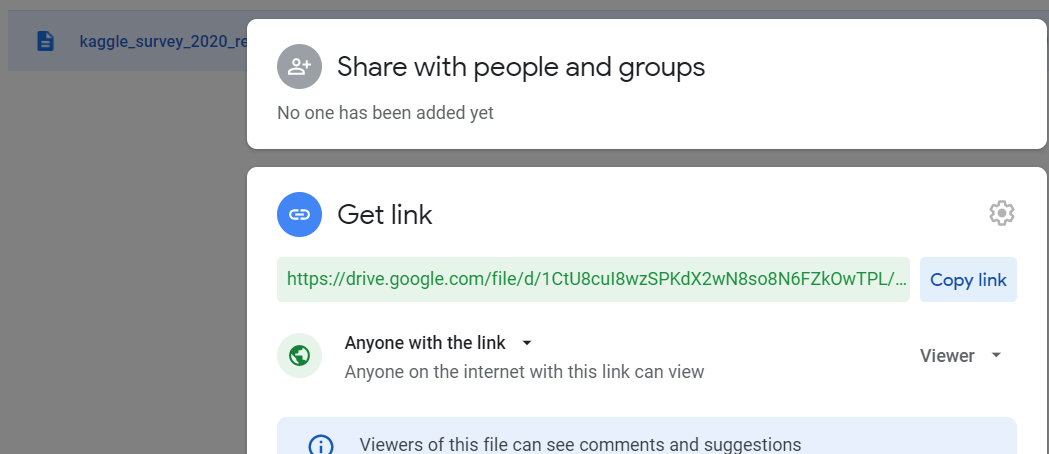
- Copy link 내의 암호된 숫자가 파일의 id --> BigQuery 적재시 필요한 정보
- 업로드된 파일에서 마우스 오른쪽 클릭 후
최종적으로 설문 데이터는 아래의 Google Drive URI에 위치하게 된다.
▷ 데이터 적재 (Load)
분석할 데이터가 준비되었으므로 BigQuery에 이를 적재하기 위한 Dataset을 준비하자.
BigQuery Dataset은 테이블 또는 뷰(View)들을 담고 있는 컨테이너의 역할을 한다.
- BigQuery Console 오픈
- https://console.cloud.google.com/bigquery?project=************
project에는 본인이 생성한 GCP 프로젝트의 이름 사용할 것 - 상단에 본인 프로젝트(ex. learning-club-2020)가 선택되어 있는지 먼저 확인
- Dataset 생성
- 테이블을 저장할 Dataset 생성 - 왼쪽 프로젝트 리스트 목록에서 내 프로젝트를 선택하면 오른쪽
[+] 데이터세트 만들기버튼을 누르면 데이터셋 생성 팝업이 뜸.
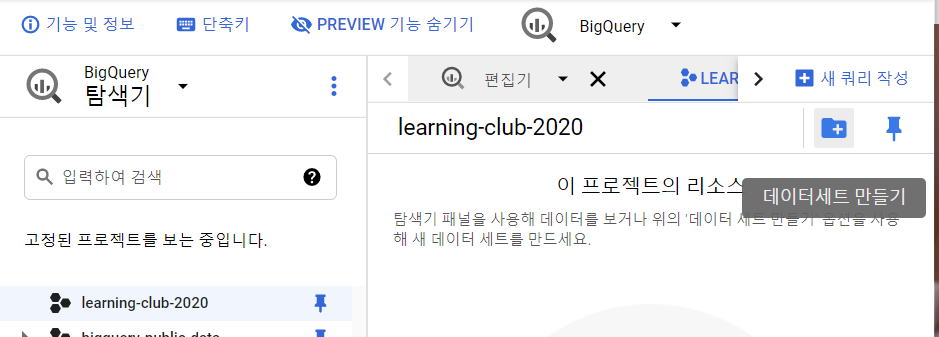
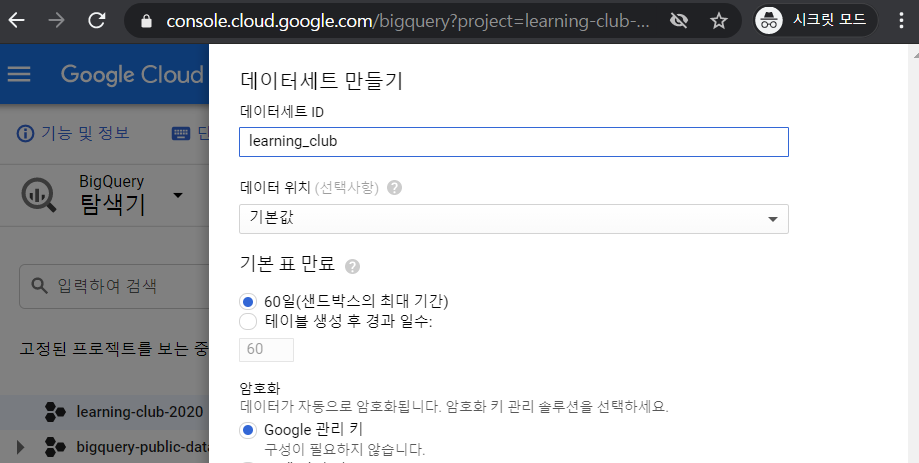
- 테이블을 저장할 Dataset 생성 - 왼쪽 프로젝트 리스트 목록에서 내 프로젝트를 선택하면 오른쪽
데이터셋이 준비되었으니 CSV로 되어 있는 설문데이터를 BigQuery 테이블로 옮길 차례이다.
이 때 아래와 같이 가능한 방법 몇 가지가 있는데 이번 실습에서는 이 중에서 두 번째 방법을 사용하도록 한다.
- BigQuery Console UI 상에서나 Command Line 에서 CSV 데이터를 BigQuery 스토리지로 적재하는 방법
- 외부테이블(External Table)로 생성하여 물리적인 데이터의 이동없이 BigQuery가 외부데이터(CSV파일)를 테이블처럼 읽도록 만드는 방법
BigQuery 외부 테이블 (External Table) 생성
BigQuery는 DDL(Data Definition Language) 문으로 외부 저장소에 위치한 데이터를 참조하는 External Table 생성이 가능하다.
앞서 확인한 Google Drive URI를 사용하여 테이블을 생성하는 BigQuery 구문은 다음과 같다.
CREATE OR REPLACE EXTERNAL TABLE learning_club.kaggle_survey_2021
OPTIONS (
format = 'CSV',
skip_leading_rows = 2,
field_delimiter = ',',
uris = ['https://drive.google.com/open?id=1xGKxgLmk07GP7wfP9OjROqcw7zP-QkxU']
);
SELECT * FROM learning_club.kaggle_survey_2021;uris를 통해 CSV파일이 위치한 URI를 BigQuery에 알려주고 있다. CSV파일의 헤더가 2줄에 걸쳐있으므로 skip_leading_rows 값을 2로 설정하였다.
▷ 데이터 변환 (Transform)
설문 파일에는 다양한 설문 항목과 관련된 많은 컬럼들을 포함하고 있다.
이 중 핸즈온의 비즈니스 질문과 관련이 있는 프로그래밍 언어 컬럼들만 추출하자. 그리고 External Table 을 Internal Table로 옮겨서 빠르게 쿼리가 수행될 수 있도록 해보자.
CREATE OR REPLACE TABLE learning_club.survey_raw AS
SELECT What_programming_languages_do_you_use_on_a_regular_basis___Select_all_that_apply____Selected_Choice___Python AS Python,
What_programming_languages_do_you_use_on_a_regular_basis___Select_all_that_apply____Selected_Choice___R AS R,
What_programming_languages_do_you_use_on_a_regular_basis___Select_all_that_apply____Selected_Choice___SQL AS SQL,
What_programming_languages_do_you_use_on_a_regular_basis___Select_all_that_apply____Selected_Choice___C AS C,
What_programming_languages_do_you_use_on_a_regular_basis___Select_all_that_apply____Selected_Choice___Java AS Java,
What_programming_languages_do_you_use_on_a_regular_basis___Select_all_that_apply____Selected_Choice___Javascript AS Javascript,
What_programming_languages_do_you_use_on_a_regular_basis___Select_all_that_apply____Selected_Choice___Julia AS Julia,
What_programming_languages_do_you_use_on_a_regular_basis___Select_all_that_apply____Selected_Choice___Swift AS Swift,
What_programming_languages_do_you_use_on_a_regular_basis___Select_all_that_apply____Selected_Choice___Bash AS Bash,
What_programming_languages_do_you_use_on_a_regular_basis___Select_all_that_apply____Selected_Choice___MATLAB AS MATLAB,
What_programming_languages_do_you_use_on_a_regular_basis___Select_all_that_apply____Selected_Choice___Other AS Other,
ROW_NUMBER() OVER() AS id, -- 사용자 ID 생성
FROM learning_club.kaggle_survey_2021;Kaggle 설문 자료는 분석하기 용이한 구조가 아니어서 Tidy Data가 되도록 변환 작업이 필요한데 아래의 몇가지 방법이 가능하다.
변환된 구조는 아래의 그림과 유사하니 참고토록 한다.
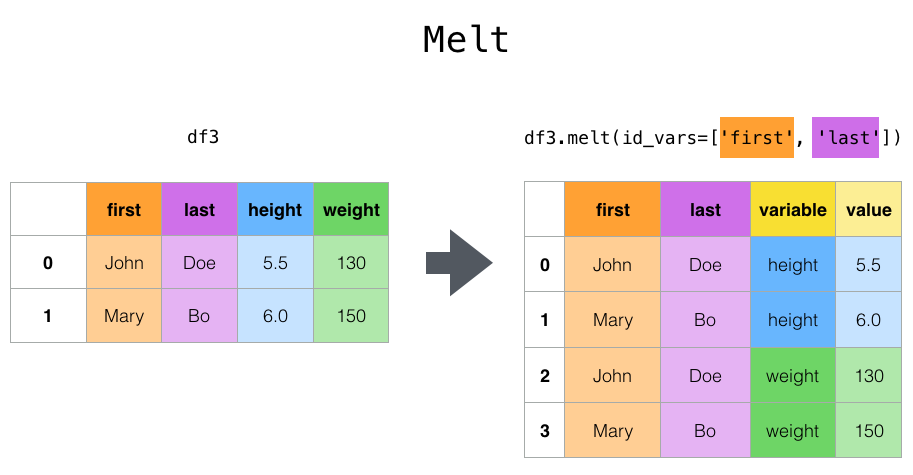
[참고] Tidy Data
방법 1 - UNION ALL 사용
표준 SQL 문법의 UNION ALL을 사용해서 아래와 같이 Stacked Data로 만들 수 있다.
WITH tidy AS ( -- WITH 구문은 SQL 문법 소개때 다룰 예정입니다.
SELECT id, Python AS lang FROM learning_club.survey_raw
UNION ALL
SELECT id, R AS lang FROM learning_club.survey_raw
UNION ALL
SELECT id, SQL AS lang FROM learning_club.survey_raw
-- UNION ALL
-- SELECT ....
)
SELECT * FROM tidy WHERE lang IS NOT NULL;방법 2 - ARRAY 사용
BigQuery 스럽게 ARRAY를 사용하게 되면 좀 더 간결하게 쿼리 기술이 가능하다.
WITH tidy AS (
SELECT id, lang FROM (
SELECT id, [Python, R, SQL, C, Java, Javascript, Julia, Swift, Bash, MATLAB, Other] AS languages
FROM learning_club.survey_raw
), UNNEST(languages) AS lang
)
SELECT * FROM tidy WHERE lang IS NOT NULL;방법 3 - UNPIVOT 사용
마지막으로 BigQuery UNPIVOT 연산자를 사용하여 변하는 방법을 살펴보자.
WITH tidy AS (
SELECT * EXCEPT(dummy)
FROM learning_club.survey_raw
UNPIVOT (dummy FOR lang IN (Python, R, SQL, C, Java, Javascript, Julia, Swift, Bash, MATLAB, Other))
)
SELECT * FROM tidy WHERE lang IS NOT NULL; | Row | id | lang |
|---|---|---|
| 1 | 16 | Python |
| 2 | 16 | C |
| 3 | 16 | MATLAB |
| 4 | 136 | SQL |
| 5 | 139 | Python |
| 6 | 139 | SQL |
| ... | ... | ... |
주어진 원시데이터(raw data)가 내가 원하는 형태로 주어지는 경우는 거의 없으므로 쿼리를 통해서 테이블의 형태를 원하는 모습으로 변환시킬 수 있는 연습이 필요하다.
ARRAY를 사용하는 방법으로 다음 분석을 이어가도록 하자.
▷ 데이터 분석 (Analysis)
분석이 용이한 구조로 변환이 되었으므로 GROUP BY와 집계 함수(aggregation function)을 사용하여 간단한 분석을 진행한다.
- 첫번째 질문의 답을 찾기 위한 쿼리 - 과학자들이 가장 선호하는 도구는?
WITH tidy AS (
SELECT id, lang FROM (
SELECT id, [Python, R, SQL, C, Java, Javascript, Julia, Swift, Bash, MATLAB, Other] AS languages
FROM learning_club.survey_raw
), UNNEST(languages) AS lang
)
SELECT lang, COUNT(1) AS cnt
FROM tidy
WHERE lang IS NOT NULL
GROUP BY 1
ORDER BY 2 DESC;| Row | lang | cnt |
|---|---|---|
| 1 | Python | 21860 |
| 2 | SQL | 10756 |
| 3 | R | 5334 |
| 4 | Java | 4769 |
| 5 | C | 4709 |
| ... | ... | ... |
쿼리 수행의 결과셋으로 부터 질문에 대한 답을 확인 할수 있고 결과창의 Explore Data (데이터 탐색) 버튼을 클릭하면 Data Studio의 시각적 분석 환경으로 Seamless 하게 넘어갈 수 있다.
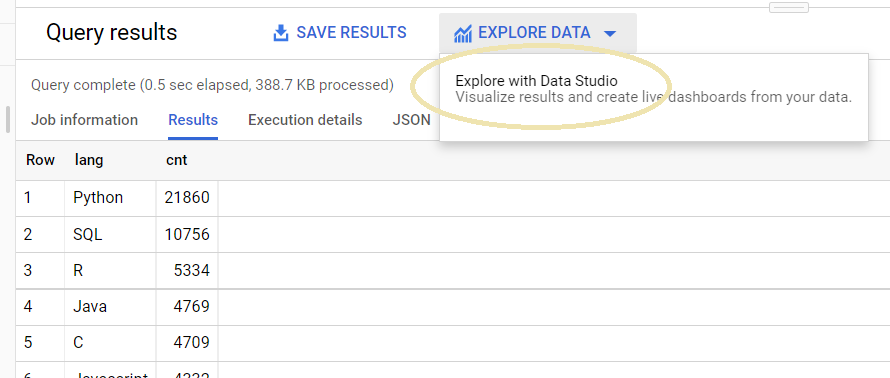
언어별 선호도 시각화
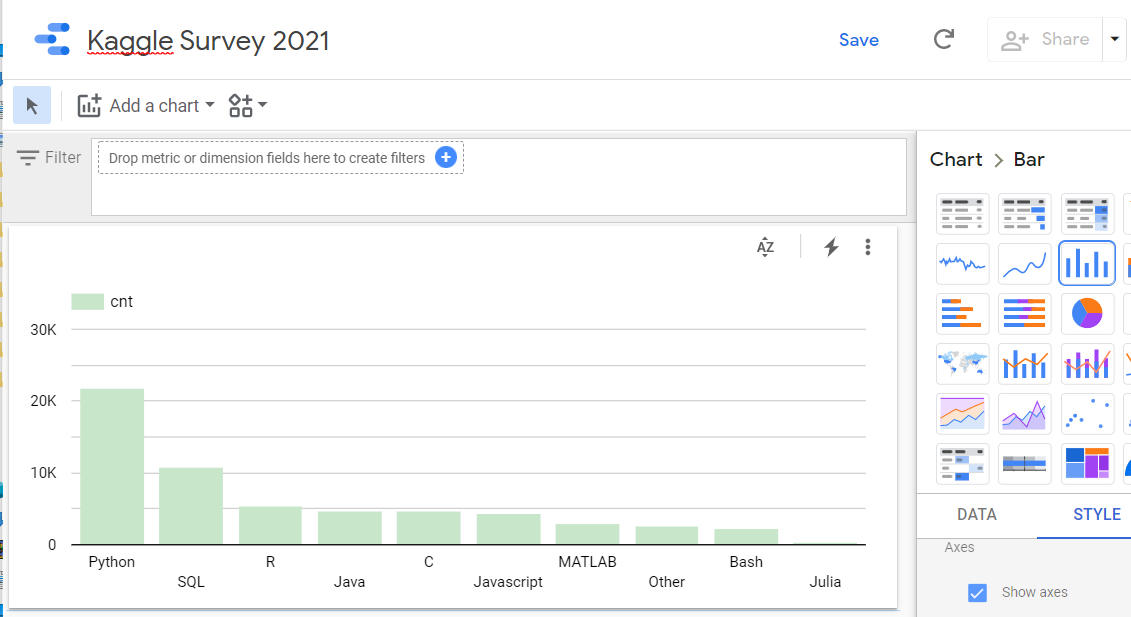
- 두번째 질문 - Kaggle 분석가들은 몇 가지 언어로 분석을 진행할까?
이 질문에 대한 답을 위해서는 사용자별로 사용하는 언어의 갯수를 먼저 집계한 후, 언어의 갯수를 차원(dimension)으로 하는 집계를 한 번 더 수행해야 한다.
WITH tidy AS (
SELECT id, lang FROM (
SELECT id, [Python, R, SQL, C, Java, Javascript, Julia, Swift, Bash, MATLAB, Other] AS languages
FROM learning_club.survey_raw
), UNNEST(languages) AS lang
)
SELECT languages, COUNT(1) AS cnt
FROM (
-- 사용자별로 사용하는 언어들을 배열로 묶음.
SELECT id, COUNT(1) AS languages
FROM tidy WHERE lang IS NOT NULL
GROUP BY 1
)
GROUP BY 1
ORDER BY 2 DESC;| Row | languages | cnt |
|---|---|---|
| 1 | 2 | 7589 |
| 2 | 1 | 6798 |
| 3 | 3 | 5493 |
| 4 | 4 | 2716 |
| 5 | 5 | 1207 |
- 세번째 질문 - 어떤 언어조합이 가장 많이 선호되고 있을까?
이 질문에 대한 쿼리를 작성하기 위해서 언어조합을 하나의 문자열로 표현하고 이를 GROUP BY하여 집계하였다.
WITH tidy AS (
SELECT id, lang FROM (
SELECT id, [Python, R, SQL, C, Java, Javascript, Julia, Swift, Bash, MATLAB, Other] AS languages
FROM learning_club.survey_raw
), UNNEST(languages) AS lang
)
SELECT ARRAY_TO_STRING(languages, ', ') langs, COUNT(1) AS cnt
FROM (
-- 사용자별로 사용하는 언어들을 배열로 묶음.
SELECT id, ARRAY_AGG(lang IGNORE NULLS ORDER BY lang) AS languages
FROM tidy GROUP BY 1
)
WHERE ARRAY_LENGTH(languages) = 2
GROUP BY 1 ORDER BY 2 DESC;| Row | langs | cnt |
|---|---|---|
| 1 | Python, SQL | 2636 |
| 2 | Python, R | 1018 |
| 3 | C, Python | 790 |
| 4 | MATLAB, Python | 652 |
| 5 | Java, Python | 575 |
결과로부터 Python과 SQL 조합을 데이터 과학자와 분석가들이 가장 선호하는 것을 알 수 있다.
이와 같이 분석을 위한 핵심 질문(Key Business Question, KBQ)을 생각하고 쿼리를 통해 답을 찾는 과정을 반복하며 데이터에 대한 이해와 통찰을 키워가는 과정이 BI 분석이라 할 수 있다. 이 과정에서 비즈니스 질문을 애드혹 쿼리로 변환하는 능력이 요구되며 쿼리 작성 능력이 분석생산력에 차이를 만든다.
