들어가며
BigQuery가 JSON을 문자열이 아닌 하나의 데이터 타입으로 지원하기 시작했다. 어떤 내용인지 살펴보자.
- BigQuery Release Note
BigQuery standard SQL now supports the JSON data type for storing JSON data. The JSON data type is in Preview. For more information, see Working with JSON data in Standard SQL.
[주의] 현재('22년 1/7일) Preview 단계이고 기능을 사용하기 위해서는 별도의 사용 신청이 필요하다. BigQuery JSON Preview Enrollment
JSON
JSON은 Semi-Structured 데이터를 교환/저장하기 위한 목적으로 자주 사용되는 표현 형식이다.
BigQuery내에서 JSON은 STRUCT 자료형과 비교될 수 있는데 STRUCT이 schema-on-write 접근을 취한다고 하면 JSON은 schema-on-read 전략을 사용한다. 즉, STRUCT 자료형을 저장하기 위해서는 사전에 스키마가 결정되어 있어야 하고 이를 따르는 값만이 저장 가능했다면 JSON은 스키마와 무관하게 값을 저장한 후 읽는 순간에 스키마(ex. json path)를 지정한다. 이러한 유연함으로 스키마가 고정되어 있지 않은 반정형(semi-structured) 데이터를 다룰 때 JSON 형식의 문자열을 사용하곤 한다.
BigQuery가 JSON을 Native 데이터 타입으로 지원함으로써 앞으로는 JSON함수를 사용하지 않고 필드 접근 연산자(field access operator)를 통해서 JSON내 필드를 읽을 수 있게 되어 간결하고 효율적인 쿼리 작성이 가능하게 되었다.
JSON Value
JSON 값을 만들어 내기 위해서는 다음과 같은 방법들을 사용한다.
- Literal로 표현하기
- JSON 문자열로부터 생성
- 다른 데이터 타입으로부터 생성
1. JSON Literal
리터럴(Literal)은 소스 코드 안에 작성된 특정 데이터 타입의 변수가 아닌 상수(constant) 값 표기를 의미한다.
a literal is a notation for representing a fixed value in source code (wikipedia)
BigQuery에서 DATE 값을 표현할 때 DATE '2021-01-07' 이라는 리터럴로 나타내듯이 이제 JSON 값을 아래와 같은 방식으로 기술할 수 있게 되었다.
SELECT JSON '{"name": "Alice", "age": 30}' AS `new`, -- JSON type
'{"name": "Alice", "age": 30}' AS old, -- [참고] json-formatted STRING다른 JSON Type들의 Literal 표현은 다음과 같다.
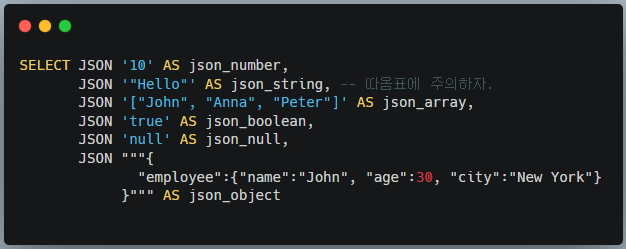

2. JSON 문자열로부터 생성
PARSE_JSON 함수로 JSON 문법을 따르는 문자열을 파싱해서 JSON 형식의 데이터를 생성할 수 있다.
SELECT PARSE_JSON('{"coordinates":[10,20],"id":1}') AS json_data;
+--------------------------------+
| json_data |
+--------------------------------+
| {"coordinates":[10,20],"id":1} |
+--------------------------------+JSON 표현에 대한 표준에 대해서는 아래 사이트를 참고하면 도움이 된다.
3. 다른 데이터 타입으로부터 생성
TO_JSON 함수는 기존 BigQuery 타입을 JSON 타입의 값으로 변환시켜 준다.
--- ex1.
SELECT TO_JSON(STRUCT(1 AS id, [10,20] AS coordinates)) AS json_data;
+--------------------------------+
| json_data |
|--------------------------------|
| {"coordinates":[10,20],"id":1} |
+--------------------------------+
--- ex2.
With CoordinatesTable AS (
(SELECT 1 AS id, [10,20] AS coordinates) UNION ALL
(SELECT 2 AS id, [30,40] AS coordinates) UNION ALL
(SELECT 3 AS id, [50,60] AS coordinates))
SELECT TO_JSON(t) AS json_objects
FROM CoordinatesTable AS t;
+--------------------------------+
| json_objects |
+--------------------------------+
| {"coordinates":[10,20],"id":1} |
| {"coordinates":[30,40],"id":2} |
| {"coordinates":[50,60],"id":3} |
+--------------------------------+TO_JSON() 함수를 사용하지 않고 BigQuery Type을 JSON Type으로 Type Casting 을 시도하는 경우에는 아래와 같은 에러를 만나게 된다.

Invalid cast from STRING to JSON at [1:13] Learn More about BigQuery SQL Functions.
[Note] JSON Value의 형변환
JSON Native Type을 소개하고 있는 아래 블로그의 예시 쿼리에 Type Casting이 아니고 STRING() 함수에 의해서 JSON 객체를 BigQuery 형으로 변환 가능한 것처럼 작성되어 있다.
SELECT
AVG(FLOAT64(labels.threatRating)) AS avg_threat_failures
FROM
`json_example.streaming_events`
WHERE
STRING(labels.type) = "login failure"(update -'22년1월10일)
JSON Preview 사용 승인이 이루어진 GCP Project에서 위와 유사한 코드를 수행시키면 아래와 같이 STRING() 함수는 JSON을 인자로 취하지 않는다는 오류가 발생한다.Query error: No matching signature for function STRING for argument types: JSON. Supported signatures: STRING(TIMESTAMP, [STRING]); STRING(DATE); STRING(TIME); STRING(DATETIME) at [19:8]
또한 다음과 같이
CAST(cart.name AS STRING) = 'login failure'Type Casting을 시도하더라도 역시 형변환이 불가능하다는 메시지가 나온다.Query error: Invalid cast from JSON to STRING at [19:13] Learn More about BigQuery SQL Functions.
blog 예시 쿼리가 잘 못 작성된 듯. GA 단계에서 바뀔 수도 있겠지만(update - '22년4월30일)
현재는 STRING()나 FLOAT64()와 같은 형변환 함수가 JSON을 인자로 취해서 BigQuery 의STRING과FLOAT64형으로 변환해 준다. 따라서, 위의 쿼리는 현재 valid 하다.
JSON Column
JSON 컬럼을 가진 테이블은 다음과 같이 DDL(Data Definition Language)문 내에 JSON 타입을 지정함으로써 생성할 수 있다.
CREATE TABLE mydataset.table1 (
id INT64,
cart JSON
);[주의] JSON 데이터간에는 동등(equality) 연산이나 비교(comparison) 연산이 정의되어 있지 않기 때문에 JSON 컬럼은 테이블 파티셔닝이나 클러스터링을 위한 컬럼으로는 사용이 불가하다.
JSON 데이터 조회
우선 다음과 같이 JSON 컬럼을 가지는 예시 테이블을 생성한 후 새롭게 바뀐 JSON 필드 조회 방법을 살펴보자.
CREATE OR REPLACE TABLE mydataset.table1(id INT64, cart JSON);
INSERT INTO mydataset.table1 VALUES
(1, JSON """{
"name": "Alice",
"items": [
{"product": "book", "price": 10},
{"product": "food", "price": 5}
]
}"""),
(2, JSON """{
"name": "Bob",
"items": [
{"product": "pen", "price": 20}
]
}""");JSON Value 조회
필드 접근 연산자는 dot 연산자로도 불리며 STRUCT 구조체의 필드에 접근하기 위한 목적으로 제공되고 있었다. 이제 dot 연산자가 JSON Type에도 지원되기 시작하여 STRUCT에서와 비슷한 방식으로 사용 가능하게 되었다.
STRUCT와 JSON 의 dot 연산 결과에서 보여지는 차이는 참고해 두면 좋을 듯 하다.
STRUCT- 앞서의 설명처럼schema-on-write방식이기 때문에 필드가 존재하지 않는 경우 에러가 발생한다.JSON-schema-on-read로 필드가 없는 경우 에러가 아닌NULL이 리턴된다.
-- ex1.
SELECT cart.name FROM mydataset.table1
+---------+
| name |
+---------+
| "Alice" |
| "Bob" |
+---------+여기서 필드 접근 연산자를 사용한 cart.name은 JSON 함수를 사용한 JSON_QUERY(cart, "$.name")의 syntactic sugar 로 볼 수 있다.
주의할 것은 필드 접근 연산자의 결과는 여전히 JSON 데이터형의 값이라는 것이다. 위의 결과를 자세히 보면 문자열이 따옴표(")로 감싸져 있고 이는 "Alice" 라는 값이 여전히 JSON 세상의 값이라는 의미이다. 이를 BigQuery 세상의 값으로 변경하기 위해서는 JSON 함수를 사용해야 한다.
-- ex2.
SELECT JSON_VALUE(cart.name) AS name FROM mydataset.table1;
+-------+
| name |
+-------+
| Alice |
| Bob |
+-------+JSON함수를 적용한 JSON_VALUE(cart.name) 의 결과값은 BigQuery 문자열이 되고 직전 결과에서 보였던 "(double quote)가 사라져있다.
다음으로 WHERE 절에서 JSON 컬럼값을 비교하는 예시는 아래와 같다. WHERE 절에 보이는 "Alice"는 BigQuery 문자열이므로 cart.name에 의해서 리턴되는 JSON 객체를 JSON_VALUE로 변환해 줘야 동일한 BigQuery 문자열간 비교가 가능해진다.
-- ex3.
SELECT cart.items[0] AS first_item
FROM mydataset.table1
WHERE JSON_VALUE(cart.name) = "Alice";
+-------------------------------+
| first_item |
+-------------------------------+
| {"price":10,"product":"book"} |
+-------------------------------+Quiz
[Quiz] 위의 예시에서 WHERE 절을 WHERE cart.name = JSON '"Alice"';과 같이 변경했을 경우에도 동작을 할까?
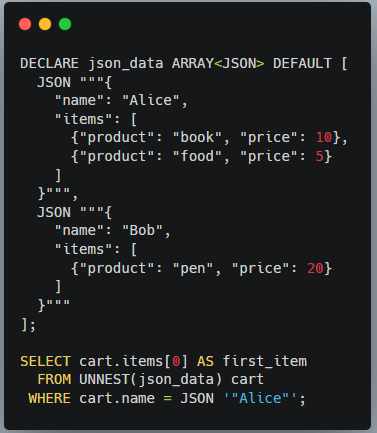
[Answer] 앞서 JSON 컬럼은 파티셔닝이나 클러스터링을 위한 컬럼으로 사용할 수 없다고 했고 그 이유를 설명하면서 JSON 형에 대해서는 동등(equality)연산이나 비교(comparision)연산이 정의되어 있지 않아서라고 언급했다. 동일한 이유로 위의 WHERE 절에서의 JSON 값들을 비교하는 것은 정의되지 않은 연산이기 때문에 수행시 아래와 같은 오류를 출력한다.
Query error: Equality is not defined for arguments of type JSON at [19:8]
정리하면 JSON 세상의 값을 BigQuery 세상의 값으로 변환하기 위해서는 아래의 과정을 거쳐야 한다.
dot연산자를 통해서 JSON 객체의 필드 값을 추출한다. 이 값은 여전히 JSON 세상의 값으로 JSON 세상에서 정의된 Type을 갖고 있다. (ex. cart.items[0].price는JSON numbertype)- JSON_VALUE() 함수로 JSON 세상의 값을 BigQuery 세상의 값으로 변환한다. 하지만 이 과정에서 JSON 세상에서 정의된 모든 Type들은 BigQuery 세상에서 String Type의 새 신분을 부여받는다. (ex. 그림에서
first_item_price1는INT64처럼 보이나 문자열임) - 부여 받은 새 신분을 세탁해야 한다. BigQuery
CAST()를 통해서 JSON 세상에서의 Type과 상응하는 BigQuery Type으로 변환시키자. (ex. 그림에서first_item_price2는INT64형임)
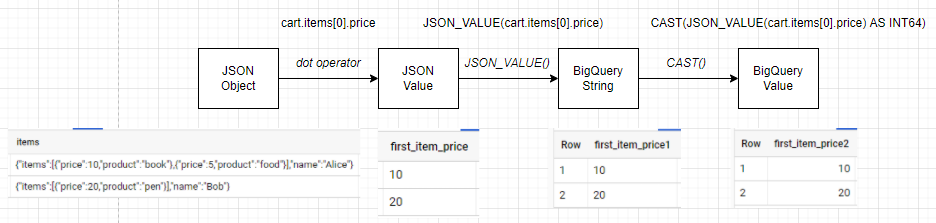

[update 22/4/30] 추가된 JSON Type 변환 함수를 사용하여
CAST()가 아닌 좀 더 간결한 방식으로 BigQuery의 여러 타입으로 변환이 가능해졌다.
--> Type Cast 함수를 이용한 예시
SELECT CAST(JSON_VALUE(cart.items[0].price) AS INT64)
--> Type 변환 함수를 이용한 예시 (recommended)
SELECT INT64(cart.items[0].price)추가로 SAFE.INT64(cart.items[0].price) 와 같이 Safe Casting이 되도록 작성하는 것이 좋다.
JSON Array 조회
JSON 배열에 접근하기 위해서는 JSON subscript(하부첨자) 연산자를 사용한다.
SELECT cart.items[0] AS first_item FROM mydataset.table1
+-------------------------------+
| first_item |
+-------------------------------+
| {"price":10,"product":"book"} |
| {"price":20,"product":"pen"} |
+-------------------------------+JSON subscript 연산자는 배열의 요소에 접근하기 위한 목적 외에도 JSON 객체의 멤버를 이름으로 조회하기 위한 용도로도 사용된다.
SELECT cart['name'] FROM mydataset.table1
+---------+
| name |
+---------+
| "Alice" |
| "Bob" |
+---------+JSON 객체에서 배열을 추출할 때는 기존 JSON 배열함수를 사용한다.
JSON_QUERY_ARRAY: JSON의 배열을 리턴한다.ARRAY<JSON>JSON_VALUE_ARRAY: BigQuery 문자열(STRING)의 배열을 리턴한다.ARRAY<STRING>
-- ex1.
SELECT JSON_QUERY_ARRAY(cart.items) AS items
FROM mydataset.table1;
+----------------------------------------------------------------+
| items |
+----------------------------------------------------------------+
| [{"price":10,"product":"book"}","{"price":5,"product":"food"}] |
| [{"price":20,"product":"pen"}] |
+----------------------------------------------------------------+-- ex2.
SELECT id, JSON_VALUE(item.product) AS product
FROM mydataset.table1, UNNEST(JSON_QUERY_ARRAY(cart.items)) AS item
ORDER BY id;
+----+---------+
| id | product |
+----+---------+
| 1 | book |
| 1 | food |
| 2 | pen |
+----+---------+JSON nulls
JSON의 null은 BigQuery(SQL)에서의 NULL과는 다르게 취급된다. 따라서 JSON_QUERY 함수가 리턴하는 JSON null과 JSON_VALUE가 리턴하는 SQL NULL은 다른 값이다.
SELECT
json.a AS json_query, -- Equivalent to JSON_QUERY(json, '$.a')
JSON_VALUE(json, '$.a') AS json_value
FROM (SELECT JSON '{"a": null}' AS json);
+------------+------------+
| json_query | json_value |
+------------+------------+
| null | NULL |
+------------+------------+나가며
이상으로 간단하게 BigQuery의 JSON Type에 대해서 알아보았다. 빅쿼리에서 STRUCT를 사용하여 Nested and Repeated 구조를 갖는 테이블로 만들곤 했었는데 JSON Type을 이용하면 Schema Free한 좀 더 유연한 형태의 Nested 테이블을 만들어 활용할 수 있을 듯 하다.
참고자료
