이 책을 읽는 목적은 일단 단 하나,
프로그래머들로 하여금 컴포넌트들이 어떻게 동작하고 프로그램의 성능과 정확성에 어떤 영향을 주는지 이해하도록 하여 이들이 프로그램을 더 잘 개발할 수 있도록 하기 위해 쓰여졌다.
이 책을 읽는 '방법'과 '내 마음가짐'은
디테일을 뭉개는 한이 있더라도, 추상화하여 내 것으로 만들기.
Overview
심플한 'hello world' 파일이 돌아가는 걸 탐색하면서 컴퓨터 시스템의 주요 아이디어들을 소개.
1.1 정보는 비트+컨텍스트

이 프로그램이 실행되어 종료되기 위해서는 시스템 주요 부분들이 조화롭게 동작해야한다. 어떤 의미에서 이 책의 목적은 hello 프로그램을 실행하면 무슨 일이 일어나고, 그 이유를 이해하는 것을 도와주기 위함이다.
hello 프로그램은 프로그래머가 에디터로 작성한 소스프로그램(또는 소스파일)으로 시작, hello.c 라는 텍스트 파일로 저장된다. 소스프로그램은 0 또는 1로 표시 되는 비트들의 연속이며, 바이트라는 8비트 단위로 구성된다. 각 바이트는 프로그램의 텍스트 문자를 나타낸다.
대부분의 컴퓨터 시스템은 텍스트 문자를 아스키(ASCII) 표준을 사용하여 표시한다.

hello.c 프로그램은 연속된 바이트들로 파일에 저장된다. 각 바이트는 특정문자에 대응되는 정수 값을 갖는다. 이처럼 오로지 아스키 문자들로만 이루어진 파일들은 text file이라고 부른다. 다른 모든 파일들은 바이너리 파일이라고한다. ( 텍스트 파일 vs 바이너리 파일 )
hello.c의 표시방법은 기본 개념을 분명히 보여준다. 모든 시스템 내부의 정보-디스크 파일,메모리상의 프로그램, 데이터, 네트워크를 통해 전송되는 데이터-는 비트들로 표시된다. 서로 다른 객체들을 구분하는 유일한 방법은 이들을 바라보는 컨텍스트에 의해서다. 일례로 다른 컨텍스트에서는 동일한 일련의 바이트가 정수, 부동소수, 문자열 또는 기계어명령을 의미할수 있다.
1.2 프로그램은 다른 프로그램에 의해 다른 형태로 번역된다.
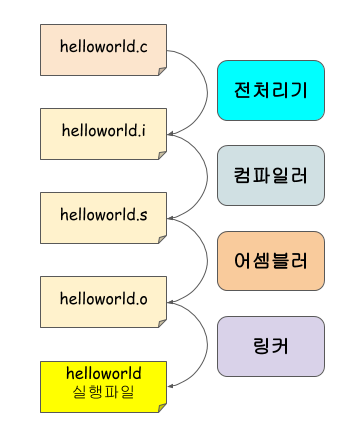
(출처)
hello.c 파일을 시스템에서 실행시키는 과정.
'소스파일' 적는다고 바로 뚱땅뚱땅 RAM위에서 프로그램이 실행되는 것은 아니다. '컴파일 시스템(전처리기, 컴파일러, 어셈블러, 링커)'을 통해 '번역'이 이루어진다.
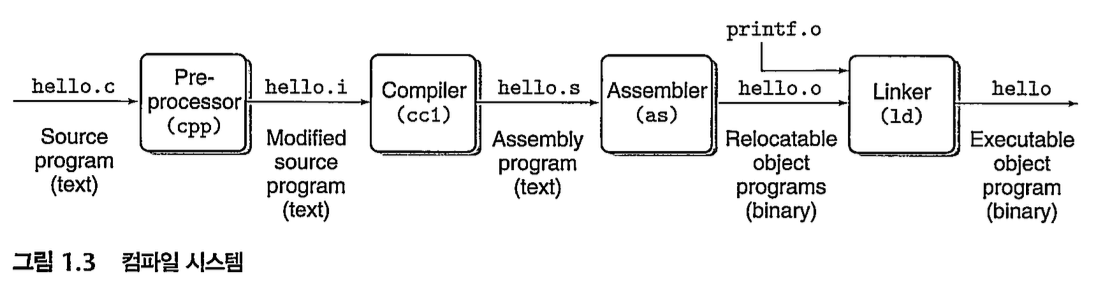
위 컴파일 시스템을 거치는 걸 조금 더 간략하게 표현하면 아래와 같다.
C source file --(via some programs)--> low level machine language instructions--(packaging)--> Executable object program(=executable object files)
유닉스 시스템에선 위 번역 과정을 'compiler driver'가 한다. (hello.c -> hello)
linux> gcc -o hello hello.c
컴파일 시스템은 총 4단계로 세분화 되는데, 살펴보자면
- (1) 전처리단계
- 전처리기(cpp)가 '#' 문자로 시작하는 선행처리 지시문을 directive에 따라, 기존 C프로그램을 수정함.- #include<stdio.h> : 전처리기에게 시스템 헤더파일(stdio.h)를 프로그램 문장에 직접 삽입하라고 지시함.
- .c ==> .i파일이 생성
- (2) 컴파일단계
- 컴파일러(ccl)가 .i ==> .s파일로 번역. 해당 파일에는 어셈블리어 프로그램이 저장.
- 어셈블리어 프로그램은 다음과 같은 main함수의 정의를 포함. low level machine lang instruction을 텍스트 형식으로 표현해놓은 듯한?
- 어셈블리어가 유용한 점은, 서로 다른 컴파일러가 같은 어셈블리어로 결과물을 생성하기 때문이다.

- (3) 어셈블리 단계
- 어셈블러(as)가 .s 텍스트 파일을 드디어 machine language instruction으로 번역. 이들을 'relocatable object program' 형태로 묶어서 .o 형식의 object file(바이너리 파일임)에 결과를 저장함.
- (4) 링크 단계
- 링커 프로그램(ld)가 printf 함수가 담긴 printf.o 같은 파일을 위의 'hello.o'파일과 결합시킴- 결과로, 실행파일이 메모리에 적재되어 시스템에 의해 실행됨.
1.3 컴파일 시스템 동작의 이해
중요한 이유 3가지
- 프로그램 성능 최적화를 위해
- 함수 호출할 때 발생하는 오버헤드는 얼마나 되나? while은 for문보다 효율적이냐? 컴파일러가 어떻게 C문장들을 기계어 코드로 번역하는지? - 링크 에러를 이해하기 위해
- 보안 약점 피하기(security hole); buffer overflow
1.4 '프로세서'는 메모리에 저장된 인스트럭션을 읽고 해석한다.
1.4.1 시스템의 하드웨어 조직
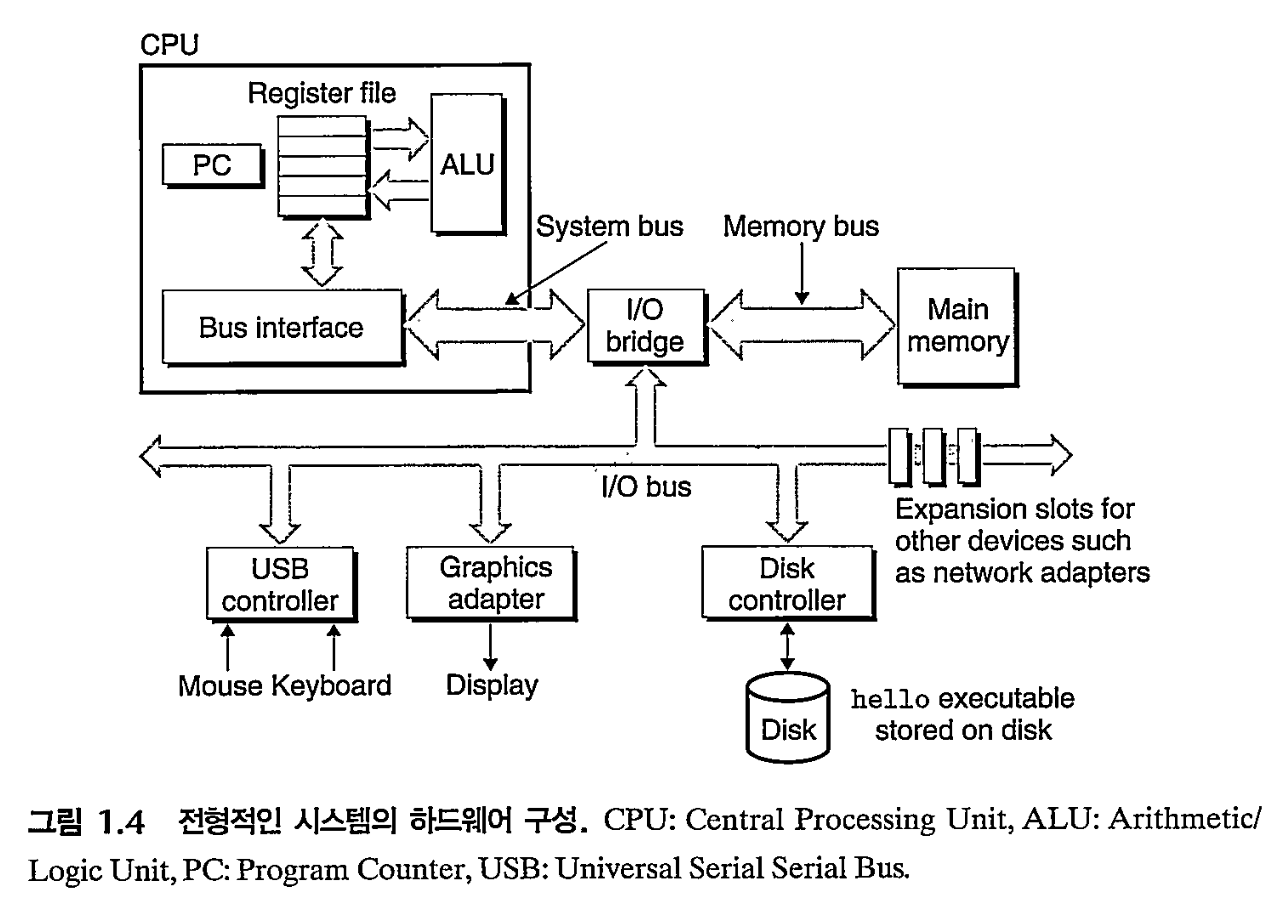
해당 그림은 일반적인 Intel system을 표현한 것. 근데 시스템들 다 비슷비슷하다.
- Buses
- 컴포넌트 간 정보의 왕래를 돕는 전자회로. 'words'라는 'fixed size of bytes'를 단위 삼아 통신함. words는 보통 4/8bytes(32, 64bits)크기임. - 입출력 장치(I/O)
- 위 그림에서는 controller, adapter, disk, memory. - 메인 메모리
- 프로세서가 프로그램을 돌릴 때, 프로그램&데이터를 임시로 저장해두는 장치.
- (물리적으론)DRAM 칩들로 구성되어 있음.
- (논리적으로 보면)유니크한 주소를 가지고 있는 byte들의 연속임. - 프로세서(CPU; Central Processing Unit)
- 메인메모리에 있는 instruction들을 실행하는 엔진.
-중심에 PC(Program Counter) 는 word 크기의 저장장치(or 레지스터)임. 이 PC는 메인메모리에 있는 machine language instruction을 가리키고 있음. 특히 '다음에 인출할 명령어의 주소를 가지고 있는 레지스터'임.- 예를 들어, 해당 컴퓨터 시스템이 32bit word일때, PC가 메모리 100번을 가리키고 있다가, 당장의 instruction이 끝나면, PC는 다음 instruction이 담긴 메모리 104번을 가리키며 업데이트가 된다.
- CPU를 더 살펴보면 작은 임시저장공간 개념의 register file과 연산or논리를 수행하는 ALU(arithmetic/logic unit)이 있음. 정말 중요하고, 빠르게 수행되어야 하는 값들은 register file에 넣어두고 수행함.
CPU 작업의 예시는,
(1) Load: 메인메모리의 word/byte를 레지스터로 덮어쓰면서 복사
(2) Store: 레지스터의 word/byte를 메인메모리로 덮어쓰면서 복사
(3) Operate: 2개의 레지스터에 있는 값을 ALU로 복사하고, 2개의 word로 연산을 실행하고, 결과를 레지스터에 덮어쓰면서 저장
(4) Jump: instruction에서 word를 추출하고 PC에 덮어쓰면서 복사
위 내용들의 시각화를 도와줄 출처는 아래와 같다. 큰 도움을 받았다 :0
https://youtu.be/Fg00LN30Ezg
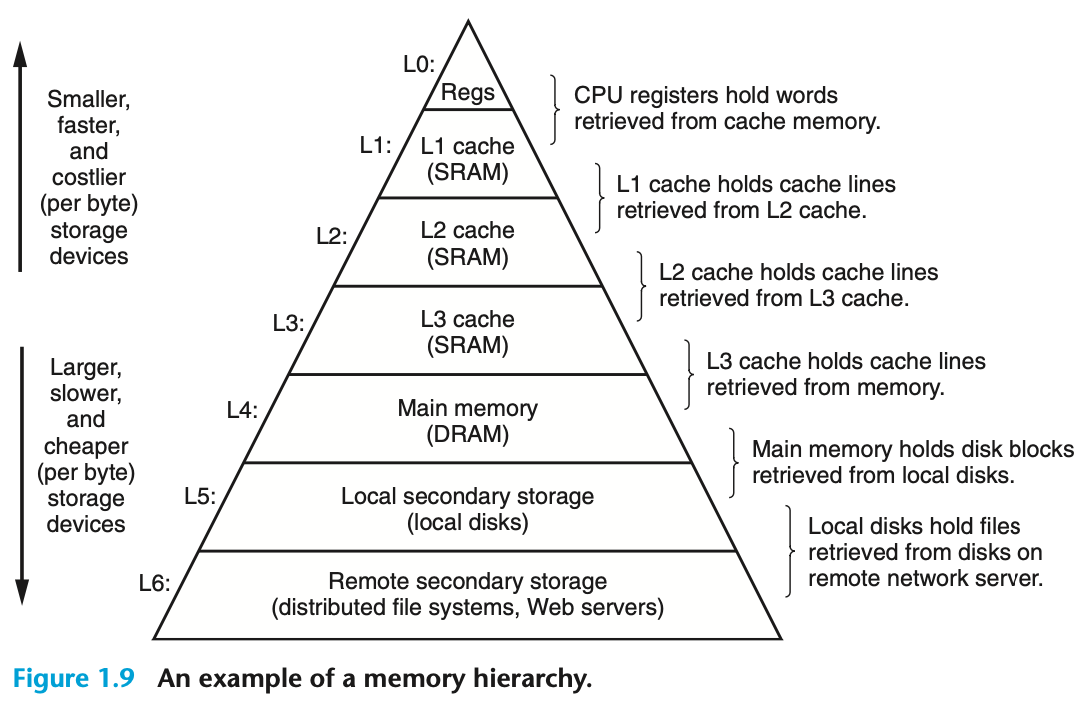
1.5 캐시!
cpu의 동작 과정에서 수많은 '복사' 과정들은 실제 작업을 느리게 하는 원인이다. 시스템 설계자들은 이 복사 과정을 빠르게 동작시키려고 한다.
저장장치: 공간의 사이즈 <-> 속도는 서로 반비례.
실제로 '프로세서'는 '레지스터' 파일을 읽는 데에, '메인메모리'보다 거의 100배 빨리 읽을 수 있음. 이러한 프로세서~메모리 격차를 줄이기 위해, '캐시(캐시메모리)'가 고안됨. L1, L2, L3 캐시는 순차적으로 용량이 크고, 속도가 떨어짐. L1 캐시는 프로세서 칩 내에서, 거의 레지스터급의 속도를 보여주는 임시저장공간이다.
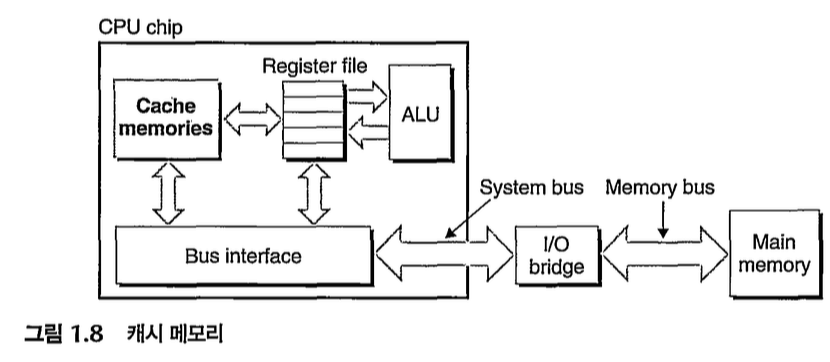
1.6 저장장치들에는 계층 구조가 있다
메모리 hierarchy의 주요 아이디어는, 한 레벨의 저장장치가 다음 하위레벨 저장장치의 캐시역할을 한다는 것임.
1.7 OS는 HW를 관리한다 (난이도: 상)
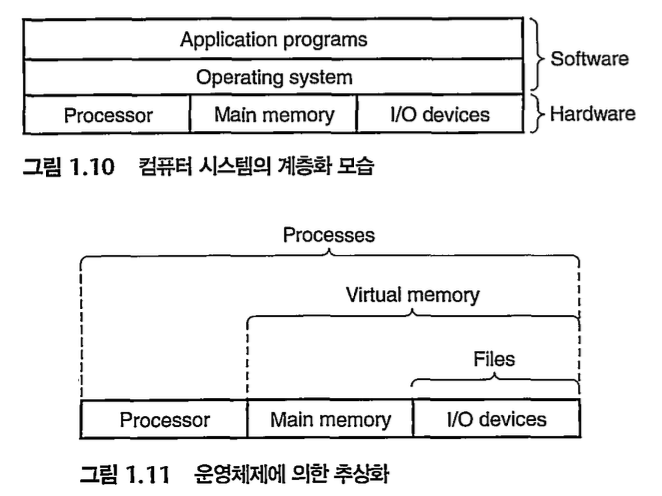
프로세스:
'단일 프로세서'를 가정해보자. (멀티코어는 1.9에서)
OS는 프로세스가 실행되는데 필요한 모든 상태정보들의 변화를 추적한다.
단일 프로세서는 한 순간에 한 개의 프로세스에 대한 코드만 실행하는데, 다른 프로세스로 제어를 옮길 때, 현재 프로세스의 context를 저장해두고, 새 프로세스의 context를 복원하는 context switching이 진행된다. (이 과정에도 많은 알고리즘과 기법이 사용된다)
hello world 예시에선 Shell process와 hello process가 concurrently 진행된다.
shell process가 혼자 동작하다가, 명령줄에서 입력을 기다린다.
hello 프로그램을 실행하라는 명령을 받으면, shell은 system call이라는 특수함수를 호출하여 os로 제어권을 넘긴다.
이 때, os는 shell의 context를 저장하고, hello 프로세스와 context를 생성한 뒤, hello 프로세스에게 제어권을 넘겨준다.
hello가 종료되면, os는 shell 프로세스의 context를 복구시키고 제어권을 넘겨주면서 다음 명령 줄 입력을 기다린다.
- kernel
os 코드의 일부분으로, 모든 프로세스를 관리하기 위해 시스템이 이용하는 코드&자료구조의 집합.
항상 메모리에 상주한다. 운영체제 자체도 소프트웨어로서 전원이 켜짐과 동시에 메모리에 올라가야하지만, 운영체제처럼 규모가 큰 프로그램이 모두 메모리에 올라간다면 한정된 메모리 공간의 낭비가 심하다.
-> 따라서 운영체제 중 항상 필요한 부분만을 전원이 켜짐과 동시에 메모리에 올려놓고 그렇지 않은 부분은 필요할 때 메모리에 올려서 사용하게 된다. 이 때 메모리에 상주하는 운영체제의 부분을 커널이라 한다. 좁은 의미의 운영체제!
응용프로그램이 os에 의한 어떤 작업을 요청하면, 컴퓨터는 파일 읽기, 쓰기 같은 특정 system call을 실행하여 kernel에 제어를 넘겨준다. kernel은 요청 작업을 수행하고 응용 프로그램으로 리턴.
생각보다 중요한 개념이다. 쉽게 요약하자면, OS = kernel + app/utility.
쓰레드; Thread:
최근 시스템에선, process는 thread라고 하는 다수의 실행 유닛으로 구성된다.
쉽게 생각하려면, thread는 process 중 한 갈래라고 생각하면 될 듯하다.
각 쓰레드는 해당 프로세스의 context에서 실행되면서 동일한 코드와 전역 데이터를 공유한다. (같은 프로세스 내에서만 한정이다!)
다수의 프로세스들에서보다 데이터 공유가 쉽고, 프로세스보다 더 효율적이라 중요성이 커지는 모델이다.
물론 단점도 있다. 같은 프로세스 내에서 서로다른 쓰레드가 같은 변수에 접근할때, 에러가 발생할 수 있다.
가상 메모리
리눅스 프로세스들의 가상주소 공간이다. 아래->위 (사용자 코드->유저 스택)로 가면서 주소가 증가한다. 최상위 공간은 모든 프로세스들이 공통으로 쓰는 os code, data를 위한 것이고, 하위 공간은 사용자 프로세스의 code, data를 저장한다.
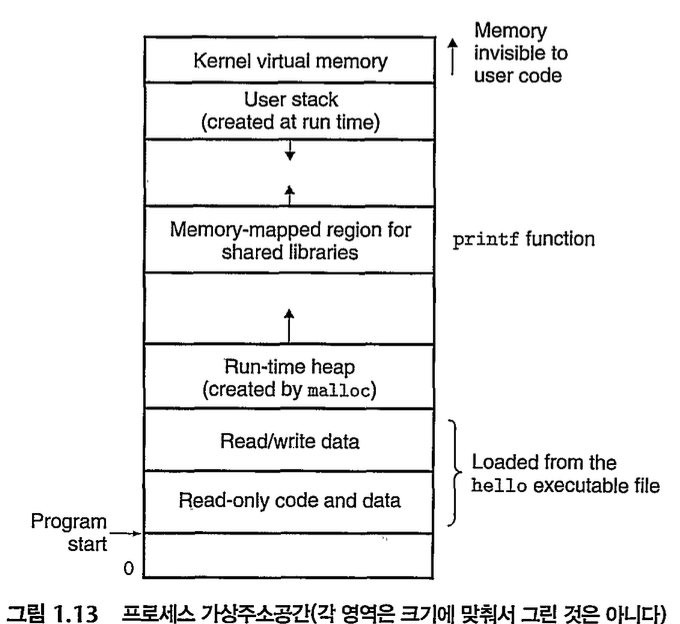
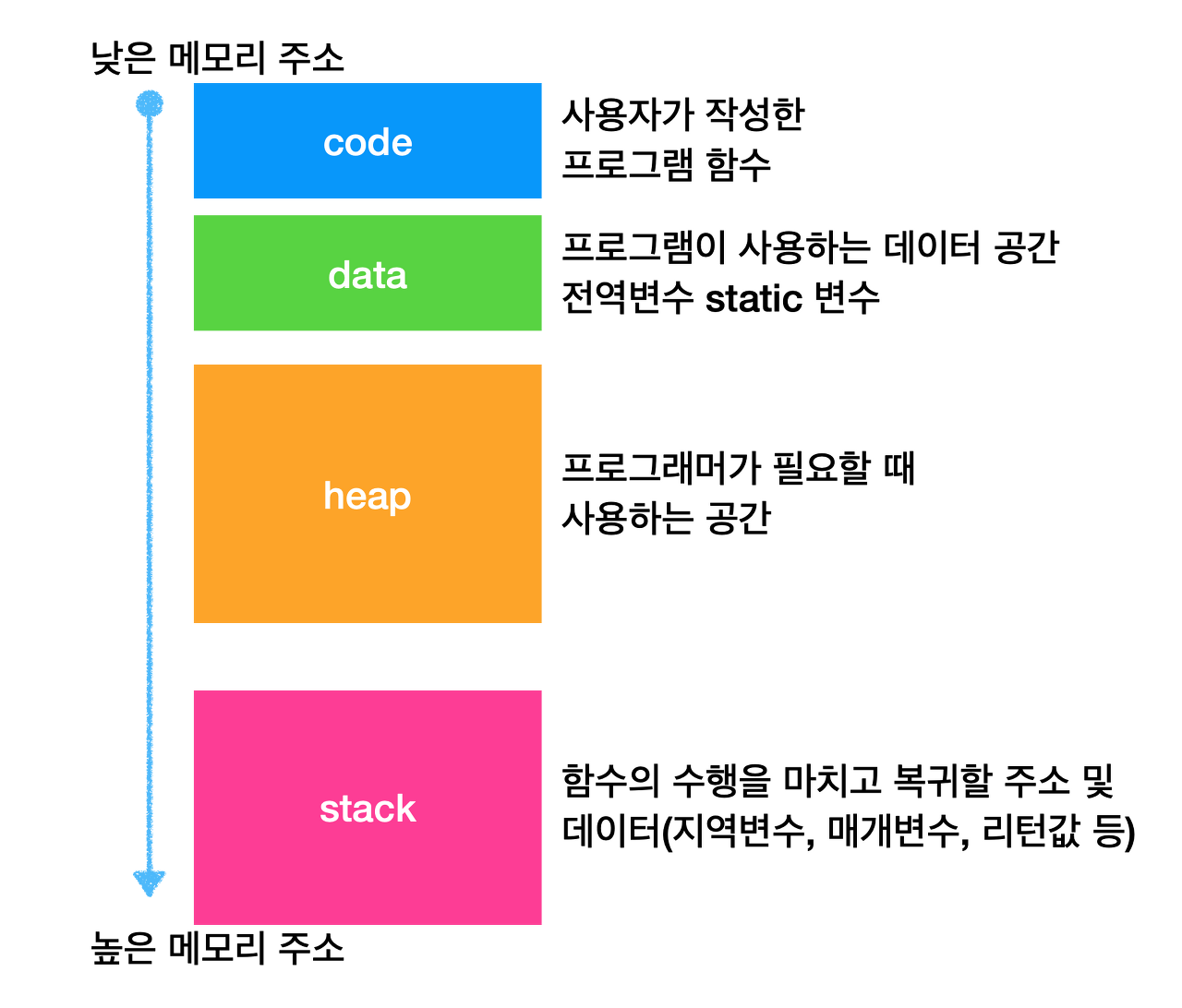
위 사진들을 참고하여 각 공간에 대한 설명을 기술해보자면,
-
code 영역
사용자가 작성한 프로그램 함수들의 코드가, cpu에서 수행할 수 있는 기계어 명령 형태로 변환되어 저장되는 공간이다. code는 모든 프로세스들이 같은 고정 주소에서 시작하며, 다음에 C 전역변수에 대응되는 데이터 위치들이 따라온다. 컴파일 타임에 결정되고, 중간에 코드를 바꿀 수 없게 read-only이다. -
data 영역
전역변수, static 변수 등 프로그램이 사용하는 데이터를 저장하는 공간. 전역 변수 또는 static 값을 참조한 코드는 컴파일이 완료되면 data 영역의 주소값을 가르키도록 바뀐다. 전역변수가 변경 될 수도 있어 read-write로 되어있다. -
code, 데이터 영역은 executable obj file 'hello'로부터 직접 초기화된다.
-
heap 영역
프로그래머가 필요할 때마다 사용하는 메모리 영역. 위의 code&data영역과 다르게, 프로세스가 실행되면서 C 표준함수인 malloc이나 free를 호출하면서 런타임에 동적으로 크기가 늘고, 줄고 한다. (Java에서는 객체가 heap 영역에 생성되고 garbage collector에 의해 정리됨) -
공유 라이브러리
-
stack 영역
호출된 함수의 수행을 마치고 복귀할 주소, 데이터(지역변수, 매개변수, 리턴값 등)를 임시로 저장하는 공간. 여기는 함수 호출 시 기록하고, 수행이 완료되면 사라진다. -
kernel 가상메모리
응용프로그램들은 여기 내용을 읽기, 쓰기 금지. 커널 코드 내에 정의된 함수 직접 호출도 금지.
파일
연속된 bytes. 모든 I/O는 파일로 모델링한다.
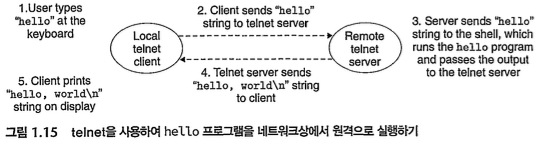
1.8 시스템은 네트워크를 통해 다른 시스템과 통신한다.
이 책에서 네트워크는, 단순 또 다른 입출력장치 중 하나로 취급된다.
컴퓨터 1의 메인메모리->네트워크 어댑터-(네트워크)->컴퓨터2의 메인메모리
1.9 important themes
- Amdahl의 법칙
- 시스템의 일부 성능 개선의 효율성에 대한 직관
- 시스템 성능에 대한 효과 = 개선한 부분이 얼마나 중요한지 + 개선한 부분이 얼마나 빨라졌는지

실제 책에 나온 예시를 대입해보면, alpha=0.6, k=3일 때에도 전체 속도향상은 고작 1.67이다. 이 결과 자체가 Amdahl 법칙의 의미라고 보면 된다.
- 동시성과 병렬성 (Concurrency & Parallelism)
- 동시성: 다수의 동시에 벌어지는 일을 갖는 시스템에 관한 일반 개념
- 병렬성: 동시성을 사용해, 시스템을 보다 빠르게 동작하도록 하는 것
(참고: 여러 그림, 표로 아주 잘 설명!)
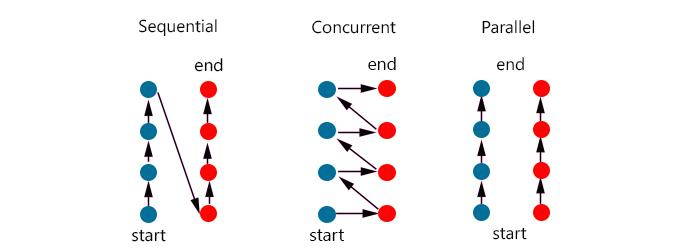
- 위 개념들을 여러 시스템 계층에서 강조해보면.
쓰레드 수준 동시성
- 멀티프로세스 시스템: 여러 개 프로세스 가지고 하나의 운영체제 커널의 제어 하에 동작하는 시스템
인스트럭션 수준 병렬성 - 보다 최근의 프로세서들로 넘어오면서, 교묘한 테크닉을 통해, 인스트럭션들은 시작~종료까지 훨씬 긴 시간을 소요하지만서도, 한 번에 100개의 인스트럭션까지 처리할 수 있게 되었다
- 멀티프로세스 시스템: 여러 개 프로세스 가지고 하나의 운영체제 커널의 제어 하에 동작하는 시스템
- 추상화(Abstraction)
- 중요한 개념이지만, 글 몇 개 읽고 컴퓨터 시스템에서의 추상화 개념을 완전 이해할 수는 없다고 함
- 승용차를 운전하는 사람이, 차체 내의 엔진 시스템을 몰라도 운전을 할 수 있듯, 컴퓨터에서도 마찬가지이다
- 관련하여 좋은 글: 나같은 초보도 부담없이 읽으면서 추상화, 가상화에 대한 감을 잡을 수 있음 https://digiconfactory.tistory.com/entry/%EC%B6%94%EC%83%81%ED%99%94Abstraction%EC%99%80-%EA%B0%80%EC%83%81%ED%99%94Virtualization
