📕서론
naver의 Craft detect 모델을 준비 하였으니 이제 본격적으로 recognition 모델을 만들어 보자.
1. 학습 데이터 준비
먼저 학습데이터 준비는 다음과 같은 3가지 단계로 진행하였다.
1. 라벨링이 되어있는 공공 데이터 준비.
2. 데이터 증강 기법을 통해 부족한 데이터 보완.
3. 데이터를 분석한 뒤 부족한 패턴의 데이터는 라벨링을 통하여 준비.1. 데이터 다운로드 사이트 :
공공데이터 다운로드 사이트에는 OCR을 위한 많은 데이터들이 제공되고 있다.2. 데이터 증강 기법 :
네이버 clovaai에서 제공해주는 Synthtiger는
Synthetic Text Image GEneratoR Towrads Better Text Recognition Models의 약자로
원하는 폰트를 통해 다양한 글씨체를 만들 수 있고,
원근법, 회전, 기울기, 노이즈생성 등 여러가지 데이터를 만들어 낼 수 있다.3. 라벨링 프로그램 :
PPOCRLabel프로그램은 PaddlePaddle에서 제공 해 주는 라벨링 툴로
단축키, 이미지 Crop 등 다양한 기능들이 존재해서 편리하게 사용 가능하다.🎁
PPOCRLabel을 통해 라벨링을 하면 gt.txt파일이 생성 되는데 deep-text-recognition-benchmark의 학습데이터 구조는 이미지경로 - 정답 형태로 구조가 같다.
2. 학습 준비
먼저 deep-text-recognition-benchmark에서 학습 코드를 clone해오자.
논문에 따르면 MJ(MJSynth)데이터와 ST(SynthText)데이터를 함께 학습에 사용하여 성능을 측정한 지표를 나타내고 있다.
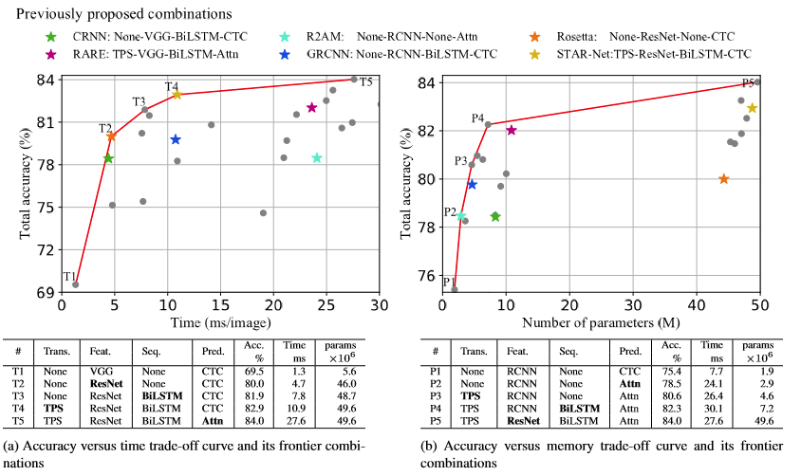
train.py의 코드를 보면 알겠지만 deep-text-recognition-benchmark는 Transformation(변환기법), FeatureExtraction(feature 추출기법), Prediction(예측방법)에 대해 많은 옵션들을 제공 해준다.
이 조합에 따라서 성능이 바뀌게 되고 위의 지표를 보면 특정 조합이 성능이 가장 좋다고 나와 있다.
하지만 이는 모델을 평가하는 데이터 셋에 따라 지표는 다시 바뀔 수 있기 때문에 나의 학습 데이터에 맞는 조합을 찾는것이 중요하다.
참고로 Attention기법을 적용하게 되면 모델의 인식 속도가 상당히 느려지게 되고 파라미터의 수가 많을수록(모델이 복잡할수록) ResNet의 성능이 높아지는 경향이 있다.
3. 학습
- CUDA_VISIBLE_DEVICES : 본인 PC의 가용 GPU번호를 작성
- nohup : 백그라운드 실행
- --train_data : train데이터 경로 지정
- --valid_data : valid데이터 경로 지정
- --select_data : MJ-ST 데이터셋 사용 안하기 때문에 "/"로 지정
- --batch_ratio : 커스텀셋 1종류 사용하기 때문에 1로 지정
- --lr : leraning_rate 지정
- --valInterval : 모델 평가 간격 설정
- --batch_max_length : 라벨링 text 최대길이 설정
- --workers : 데이터를 읽어들일 때 사용할 스레드 갯수 지정
- --batch_size : 가용 GPU 메모리에 맞게 조절
- --num_iter : 학습 반복횟수 지정
- --Transformation : 변환기법 None|TPS 중 선택
- --FeatureExtraction : VGG|RCNN|ResNet 중 선택
- --SequenceModeling : None|BiLSTM 중 선택
- --Prediction : CTC|Attn 중 선택
train.py의 argument 코드를 보면 더 많은 옵션이 존재하므로 제공해주는 기능들을 확인 해보길 바란다.
CUDA_VISIBLE_DEVICES=0,1 nohup python3 -u train.py --train_data path/to/your/train/dataset --valid_data path/to/your/valid/dataset --select_data / --batch_ratio 1 --lr 0.01 --valInterval 100 --batch_max_length 35 --workers 6 --batch_size 256 --num_iter 1000000 --Transformation TPS --FeatureExtraction ResNet --SequenceModeling BiLSTM --Prediction CTC --exp_name Folder/to/save4. 학습 결과 확인
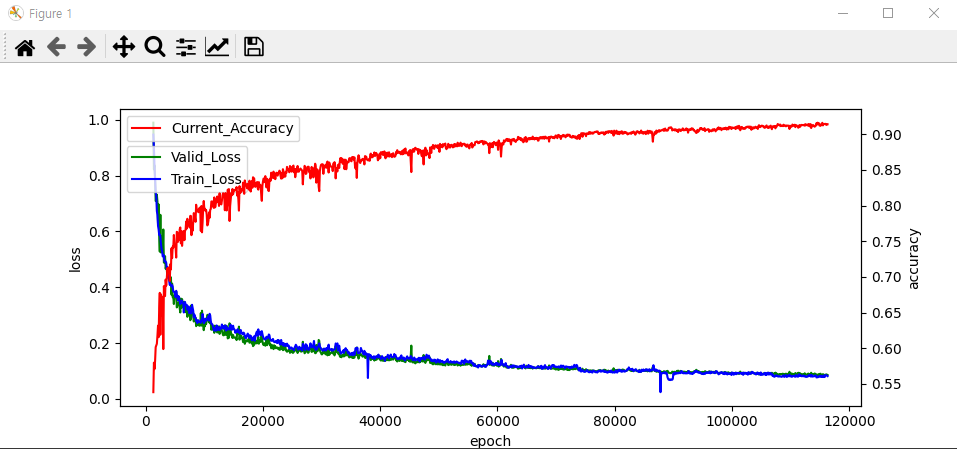
앞에서 설정한 모델 평가 step 마다 모델이 평가되고 가장 높은 정확도를 갖는 모델이 저장된다. 각 step마다 log파일도 저장되므로 이를 이용하여 모델의 학습 진척도를 확인 할 수 있다.
- matplotlib를 통해 시각화
import matplotlib.pyplot as plt
with open('path/to/your/log/folder/log_train.txt', 'r', encoding='utf-8') as file:
lines = file.readlines()
train_losses = [100] # Train loss를 저장할 리스트
valid_loss = [100] #valid_loss를 저장할 리스트
current_accuracy = [0] #accuaracy를 저장할 리스트
epoch = [0] # x 레이블을 저장할 리스트
step = False #accuracy 리스트에 append하는 동작을 컨트롤하기 위한 변수
for line in lines:
if 'Train loss' in line:
# 'Train loss' 문자열 이후의 숫자 값을 추출
tloss = float(line.split('Train loss:')[1].split(',')[0])
vloss = float(line.split('Valid loss:')[1].split(',')[0])
x_label = int(line.split('[')[1].split('/')[0])
#그래프의 가시성을 위해 loss가 1미만인 경우에만 표시
if tloss < 1 and vloss < 1:
train_losses.append(tloss)
valid_loss.append(vloss)
#학습 재시작 시 epoch이 0으로 초기화 되기 때문에 재시작 하기 전 마지막 epoch으로 맞춰주기 위함
if x_label < epoch[-1]:
x_label = epoch[-1] + 100
epoch.append(x_label)
else:
epoch.append(x_label)
continue
#train loss가 1밑으로 내려왔다가 다음 스텝에서 1보다 커지면 accuaracy스텝도 동작하지 않아야 하기 때문에 스텝변수 추가
step = True
elif 'Current_accuracy' in line:
if step:
step = False
continue
elif len(train_losses) == 0:
continue
else:
cAccuracy = float(line.split('Current_accuracy :')[1].split(',')[0]) /100
current_accuracy.append(cAccuracy)
# 그래프를 그립니다.
fig, loss_ax = plt.subplots(figsize=(12, 5))
acc_ax = loss_ax.twinx()
loss_ax.plot(epoch[1:], valid_loss[1:], 'g', linestyle='-', label = 'Valid_Loss')
loss_ax.plot(epoch[1:], train_losses[1:], 'b', linestyle='-', label = 'Train_Loss')
acc_ax.plot(epoch[1:], current_accuracy[1:], 'r', linestyle='-', label = 'Current_Accuracy')
loss_ax.set_xlabel('epoch')
loss_ax.set_ylabel('loss')
acc_ax.set_ylabel('accuracy')
loss_ax.legend(loc='upper left', ncol=1, bbox_to_anchor=(0, 0.9))
acc_ax.legend(loc='upper left')
plt.show()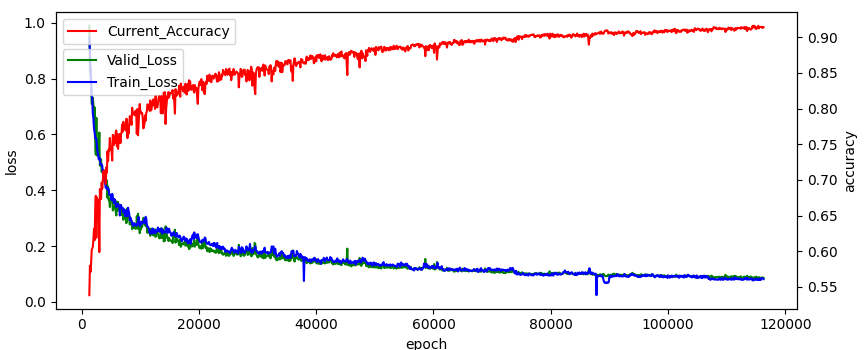
📗 결론
데이터 셋의 저작권 및 개인정보 보안 문제로 공개할 수 없지만 학습 결과를 보면 90%이상의 정확도를 보이고 실제 다양한 이미지로 테스트 해 보아도 만족스러운 체감을 받는 모델을 만드는데 성공 하였다. 추후에는 더 다양한 프레임워크를 통해 성능을 끌어 올릴 수 있는 방안을 모색 해 보겠다.
