컴퓨터의 데이터는 0과 1로만 이루어져있다. 이번 포스팅은 컴퓨터가 0과 1로 숫자와 문자를 표현하는 법을 알아보겠다.
1. 0과 1로 숫자를 표현하는 방법
1.1 정보 단위
컴퓨터는 0과 1로 모든 정보를 표현하고, 0과 1로 표현된 정보만 이해할 수 있다.
비트(bit): 0과 1을 나타내는 가장 작은 정보 단위
- n비트는 2n 가지 정보를 표현할 수 있다.
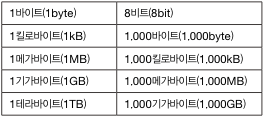
1kB는 1,024byte, 1MB는 1,024kB... 이런 식으로 표현하는 것은 잘못된 관습이다.
이전 단위를 1,024개 묶어 표현한 단위는 kB, MB, GB, TB가 아닌 KiB, MiB, GiB, TiB이다.
워드(word) : CPU가 한 번에 처리할 수 있는 데이터 크기
- CPU가 한 번에 16비트를 처리할 수 있다면 1워드는 16비트
- CPU가 한 번에 32비트를 처리할 수 있다면 1워드는 32비트
1.2 이진법
이진법(binary) : 0과 1만으로 모든 숫자를 표현하는 방법
- 이진수: 이진법으로 표현한 수
십진법 : 숫자가9를 넘어가는 시점에 자리 올림한 방법
- 우리가 일상적으로 십진법을 사용한다.
- 십진수 : 십진법으로 표현한 수
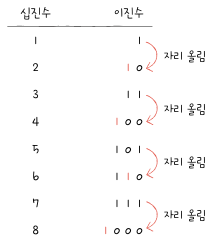
이진수 8 표기
- 1000(2)
- 주로 수학적으로 표기할 때
- 0b1000
- 주로 코드 상에서 이진수를 표기할 때
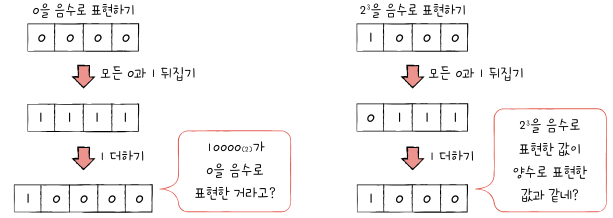
1.2.1 이진수의 음수 표현
2의 보수(two's complemnt): 어떤 수를 그보다 큰 2n에서 뺀 값
- 0과 1만으로 음수를 표현하는 방법 중 가장 널리 사용되는 방법
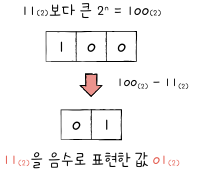
2의 보수를 쉽게 표현하는법
- 모든 0과 1을 뒤집는다.
- 거기에 1을 더한다
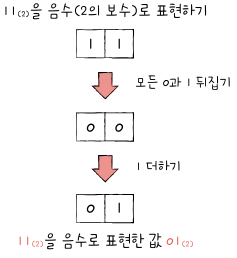
- 모든 0과 1을 뒤집은 수: 1의 보수
- 1의 보수에서 1을 더한 수: 2의 보수
컴퓨터 내부에서 어떤 수를 다룰 때는 이 수가 양수인지 음수인지 구분하기 위해 플래그(flag)를 사용한다.
- 쉽게 말해 부가 정보다.
2의 보수 표현의 한계
2의 보수는 아직까지도 가장 널리 사용되는 방식이지만, 완벽한 방식은 아니다.
- 0이나 2n 형태의 이진수에 2의 보수를 취하면 원하는 음수값을 얻을 수 없다.
1.2 십육진법
십육진법(hexadecimal): 수가 15를 넘어가는 시점에 자리 올림을 하는 숫자 표현 방식
- 이진법은 모든 숫자를 표현하다 보니 숫자의 길이가 너무 길어져서 데이터를 표현할 때 이진법 이외에 십육진법도 자주 사용된다.
- 십육진법을 사용하는 주된 이유 중 하나는 이진수와의 변환이 쉽다.

십육진수도 마찬가지로 숫자 뒤에 아래첨자 (16)를 붙이거나 숫자 앞에 0x를 붙여 구분한다.
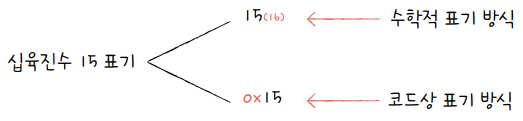
1.2.1 십육진수를 이진수로 변환하기
간편한 방법 중 하나는 십육진수 한 글자를 4비트의 이진수로 간주하는 것이다.
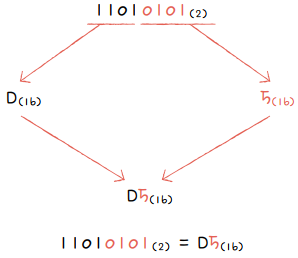
1.2.2 이진수를 십육진수로 변환하기
- 이진수 숫자를 네 개씩 끊는다.
- 끊어 준 네 개의 숫자를 하나의 십육진수로 변환한다.
- 그대로 이어 붙이면 된다.
이진수를 십진수로 변환할 때는 이렇게 간단하지 않기에 이진수를 십육진수로 묶어 표현한다.
2. 0과 1로 문자를 표현하는 방법
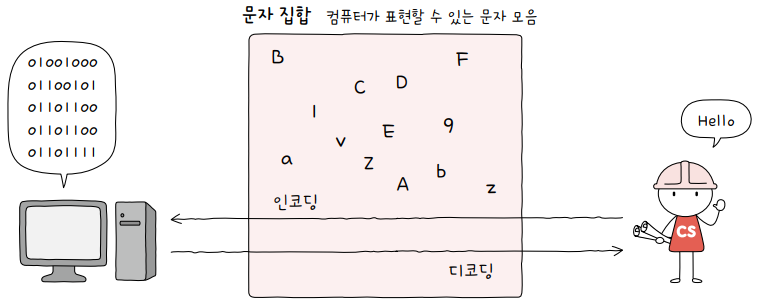
2.1 문자 집합과 인코딩
문자 집합(character set): 컴퓨터가 인식하고 표현할 수 있는 문자의 모음
문자 인코딩(character encoding): 컴퓨터가 이해할 수 있게 문자를 0과 1로 변환하는 과정
문자 디코딩(character decoding): 0과 1로 이루어진 문자 코드를 사람이 이해할 수 있는 문자로 변환하는 과정
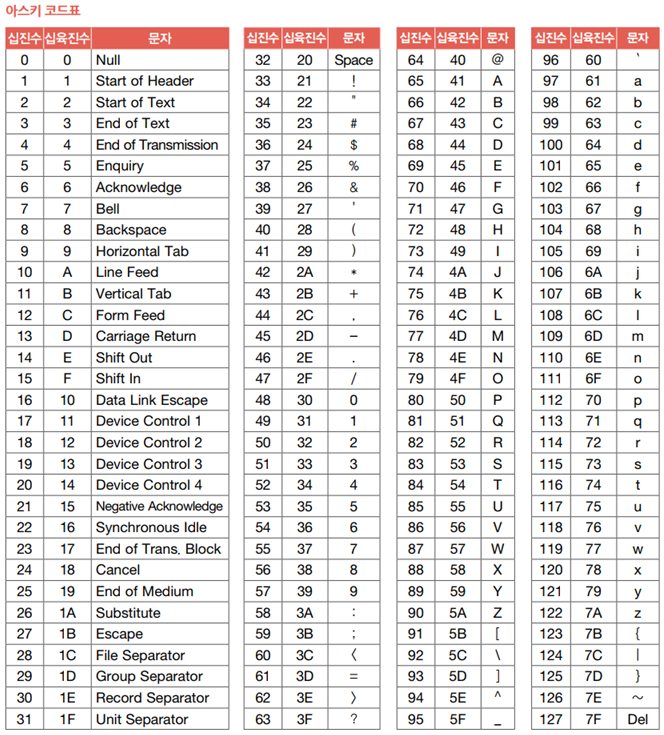
2.2 아스키 코드
아스키(ASCII: American Standard Code for Information Interchange):
초창기 문자 집합 중 하나로, 영어 알파벳과 아라비아 숫자, 그리고 일부 특수 문자를 포함한다.
아스키 문자들은 각각 7비트로 표현되는데, 27개로, 총 128개문자를 표현할 수 있다.
실제로는 하나의 아스키 문자를 나타내기 위해 8비트(1바이트)를 사용한다.
하지만 8비트 중 1비트는 패리티 비트(parity bit)라고 불리는, 오류 검출을 위해 사용되는 비트이기 때문에 실질적으로 문자 표현을 위해 사용되는 비트는 7비트이다.
아스키 코드는 간단하게 인코딩 되지만 한글, 아스키 문자 집합 외의 문자, 특수문자를 표현할 수 없다.
2.3 EUC-KR
한글 인코딩에는 두 가지 방식, 한글 완성형 인코딩과 한글 조합형 인코딩이 존재한다.
완성형 인코딩: 완성된 하나의 글자에 고유한 코드를 부여하는 인코딩 방식
- 예를 들어 '가'는 1, '나'는 2, '다'는 3
조합형 인코딩: 초성, 중성, 종성을 위한 비트열을 할당하여 그것들의 조합으로 하나의 글자 코드를 완성하는 인코딩 방식

EUC-KR 인코딩은 초성, 중성, 종성이 모두 결합된 한글 단어에 2바이트 크기의 코드를 부여한다.
EUC-KR 인코딩 방식으로 총 2,350개 정도의 한글 단어를 표현할 수 있다.
문자 집합에 정의되지 않은 '쀍', '쀓', '믜'같은 글자는 표현할 수 없다.
- 그래서 EUC-KR 인코딩을 사용하는 웹 사이트의 한글이 깨진다.
2.4 유니코드와 UTF-8
유니코드(unicode): 현대 문자를 표현할 때 가장 많이 사용되는 표준 문자 집합
UTF-8: 유니코드 문자에 부여된 값을 인코딩하는 방식
마치며
책을 정리하면서 느낀것은 단순히 암기를 하는 것이 아닌 흐름 대로 읽는 것이 중요한 것 같다.
