배열 (Array)
데이터를 저장하고 구성하는 데 사용하는 가장 기본적인 데이터 구조 중 하나이다. 배열은 자료형이 같은 요소들을 저장한다.
- 배열의 구조
-요소 element: 배열에 저장된 각각의 자료
-인덱스 index: 요소에 매겨진 숫자의 배열 - 배열의 유형
-1차원 배열
-다차원 배열
-2차원 배열=행렬: 가장 기본적인 다차원 배열
리스트 (list)
선형 리스트 linear list or 연결 리스트 linked list
연결 리스트는 배열의 특별한 유형이라고 할 수 있다. 배열 요소는 메모리에 순차적으로 저장되지만, 리스트의 요소는 흩어진 상태로 메모리에 저장되어 메모리를 더 효과적으로 사용할 수 있다.
- 리스트의 요소 : 데이터 요소와 포인터(=참조)의 쌍으로 구성
-포인터: 리스트 내의 바로 다음 요소가 저장된 메모리 위치
-노드: 데이터 요소와 다음 요소를 가리키는 포인터 쌍
-헤드: 해당 리스트에 진입하는 지점 - 연결 리스트 유형
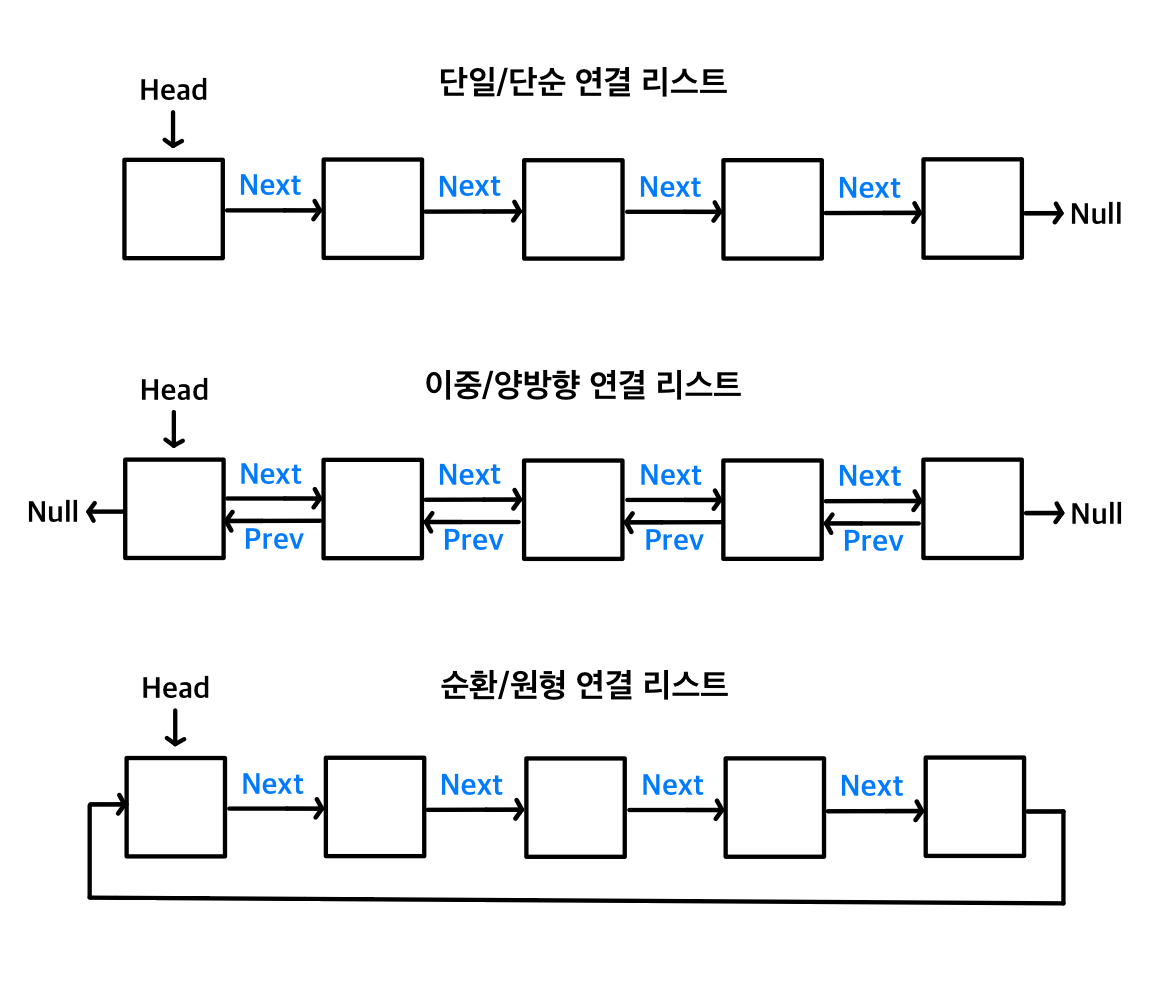
-단방향 연결 리스트: 노드 하나가 다른 노드를 가리키는 포인터 하나를 갖는 유형
-양방향 연결 리스트: 각 노드가 다음 노드를 가리키는 포인터와 이전 노드를 가리키는 포인터를 함께 갖는 유형
-순환 연결 리스트: 모든 노드가 원형으로 연결되며, 마지막 노드의 포인터가 널 값이 아닌 유형
🔗 연결 리스트 Linked lists
각 노드가 데이터와 포인터를 가지고 한 줄로 연결되어 있는 방식으로 데이터를 저장하는 자료 구조를 말한다.
(장점) 원소들이 링크라고 부르는 고리로 연결되어 있으므로, 가운데서 끊어 원소를 삽입하거나 삭제하는 것이 쉽다, 빠르다.
(단점) 데이터 구조 표현에 소요되는 저장 공간 소요가 크고, 무엇보다 'k번째의 원소'를 찾아가는 데에는 시간이 오래 걸린다.
연결 리스트의 구조
기본적으로 데이터와 링크 정보를 저장하고 있다.
- 노드에는 값을 담고 있는
데이터 - 다음 노드를 가리키는
링크
노드가 모여서 연결 리스트가 된다.
- 맨 앞 노드
헤드 (Head) - 맨 마지막 노드
테일 (Tail)
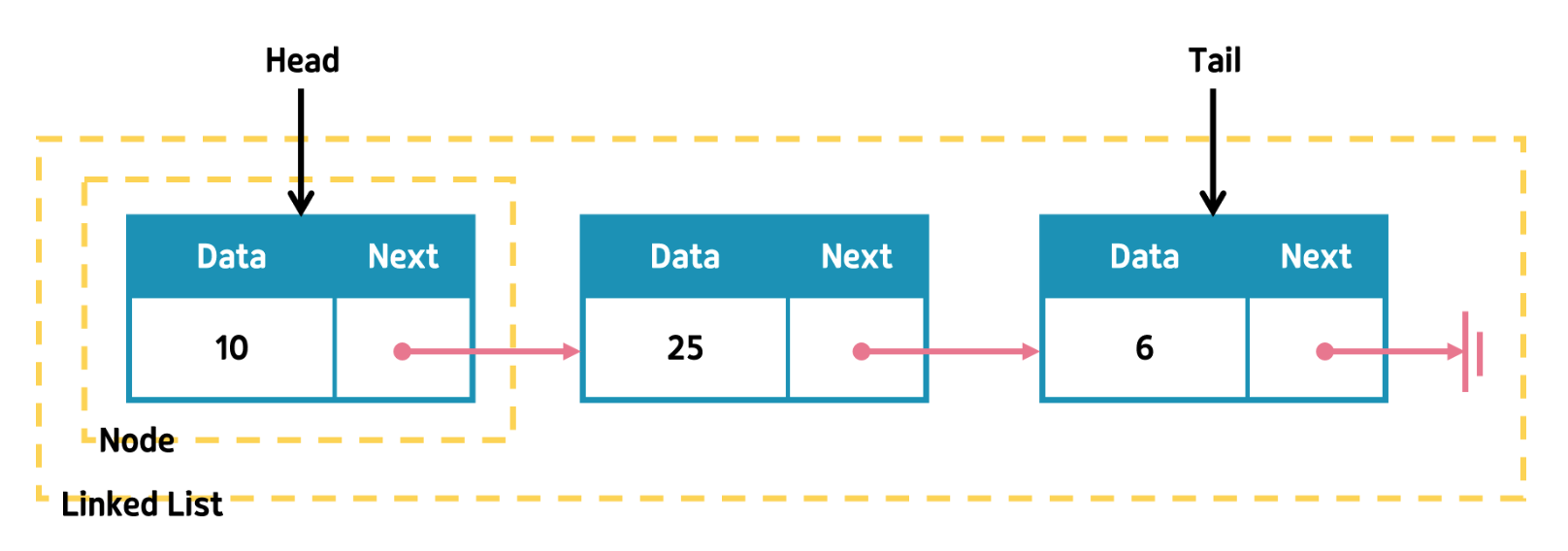
연결 리스트의 종류
추상적 자료 구조인 단일 연결 리스트, 양방향(이중) 연결 리스트, 그리고 순환/원형 연결 리스트가 있다.
📌 추상적 자료형 (ADT, Abstract data type)
문제를 해결하기 위해 필요한 자료의 형태 및 연산을 수학적으로 정의한 모델 (집합, 리스트, 스택, 큐, 트리 등)
- Data & A set of operations
자료 구조 (Data structure)
추상적 자료형이 정의한 연산들을 구현한 구현체로, 책장 속 책을 배열하는 방법 (콜 스택, 연결 리스트, 배열 등)
알고리즘 (Algorithm)
반복되는 문제를 풀기 위한 진행 절차나 방법으로, 책장에서 책을 찾는 방법 (정렬, 이진 탐색 등)
배열과의 차이
| 선형 배열 | 연결 리스트 | |
|---|---|---|
| 데이터 원소 | 번호가 붙여진 칸에 원소들 채워넣는 방식 | 각 원소들을 줄줄이 엮어서 관리하는 방식 |
| 저장 공간 | 연속한 위치 | 임의의 위치 |
| 특정 원소 지칭 | 매우 간편 | 선형탐색과 유사 |
| 복잡도 | O(1) | O(n) |
🔗 단방향(Singly, 단일, 단순)
자료 구조
class Node :
def __init__(self, item) :
self.data = item
self.next = None
class LinkedList :
def __init__(self) :
# 비어있는 연결 리스트
self.nodeCount = 0 # 노드의 수
self.head = None
self.tail = None- 이전 :
prev:pos-1 - 현재 :
curr:pos - 다음 :
next:pos+1
➀ 특정 원소 참조 (k번째)
def getAt(self, pos) :
if pos <= 0 or pos > self.nodeCount :
return None
i = 1
curr = self.head
while i < pos :
curr = curr.next
i += 1
return curr➁ 리스트 순회 (traversal)
➂ 길이 얻어내기
➃ 원소 삽입 (insertion)
def insertAt(self, pos, newNode):
if pos < 1 or pos > self.nodeCount + 1:
return False
if pos == 1:
newNode.next = self.head
self.head = newNode
else: # (2) 조정 부분
if pos == self.nodeCount + 1:
prev = self.tail
else:
prev = self.getAt(pos - 1)
newNode.next = prev.next
prev.next = newNode
if pos == self.nodeCount + 1:
self.tail = newNode
self.nodeCount += 1
return Truepos가 가리키는 위치에 (범위 : 1 <= pos <= nodeCount + 1) newNode를 삽입하고 성공/실패에 따라 True or False를 리턴한다. ➀ 원래 pos가 가리키는 위치를 구하고, ➁ 이에 newNode를 삽입한 후에 ➂ nodeCount에 1씩 더한다.
단, 코드 구현 시 주의해야 하는 사항이 있는데, (1) 삽입하려는 위치가 리스트 맨 앞일 때에는 prev가 없어서 Head 조정이 필요하다. 그리고 (2) 삽입하려는 위치가 리스트 맨 끝일 때에는 Tail 조정이 필요하다. 이 때 prev == tail과 같으며, 맨 앞에서부터 찾아갈 필요가 없다. 빈 리스트에 삽입하려고 할 때에는 이 두 조건에 따라 자동으로 처리된다.
연결 리스트 원소 삽입의 복잡도 비교 :
- 맨 앞에 삽입하는 경우 :
O(1) - 중간에 삽입하는 경우 :
O(n) - 맨 끝에 삽입하는 경우 :
O(1)
➄ 원소 삭제 (deletion)
pos가 가리키는 위치에 (범위 : 1 <= pos <= nodeCount + 1) 해당 node를 삭제하고 그 node의 데이터를 리턴한다.
단, 코드 구현 시 주의해야 하는 사항이 있는데, (1) 삭제하려는 node가 맨 앞일 때에는 prev가 없어서 Head 조정이 필요하다. 그리고 (2) 리스트 맨 끝의 node를 삭제하려고 할 때에는 Tail 조정이 필요하다. 이 경우는 curr=tail, pos == nodeCount가 되는데, prev를 찾을 방법이 없으므로 한 번에 처리할 수 없고, 앞에서부터 찾아와야 한다.
또한 (3) 유일한 노드를 삭제할 때에는 다른 조건이 필요하다.
연결 리스트 원소 삭제의 복잡도 비교 :
- 맨 앞에 삽입하는 경우 :
O(1) - 중간에 삽입하는 경우 :
O(n) - 맨 끝에 삽입하는 경우 :
O(n)
➅ 두 리스트 합치기 (concatenation)
def concat(self, L) :
self.tail.next = L.head
if L.tail :
self.tail = L.tail
self.nodeCount += L.nodeCount연결 리스트 self의 뒤에 또 다른 연결 리스트인 L을 이어 붙이는 방법이다. (L1 + L2) 그러기 위해선 ➀ self.tail.next = L2.head, 즉 현재 리스트(L1)의 맨 끝(tail) 다음(next)이 다음 리스트(L2)의 맨 앞(head)로 연결되어야 하고, ➁ self.tail = L2.tail, 즉 현재 리스트(L1)의 맨 끝(tail)을 다음 리스트(L2)dml 맨 끝(tail)으로 이어붙여야 한다. tail을 옮겨야 하므로 L1의 tail이 맨 끝으로 가야 하기 때문이다.
다만, L2가 빈 값일 경우를 고려하여 작성하여야 한다.
(정리) 단뱡향 연결 리스트 연산
class Node:
def __init__(self, item):
self.data = item
self.next = None
class LinkedList:
def __init__(self):
self.nodeCount = 0
self.head = None
self.tail = None
def __repr__(self):
if self.nodeCount == 0:
return 'LinkedList: empty'
s = ''
curr = self.head
while curr is not None:
s += repr(curr.data)
if curr.next is not None:
s += ' -> '
curr = curr.next
return s
def getAt(self, pos):
if pos < 1 or pos > self.nodeCount:
return None
i = 1
curr = self.head
while i < pos:
curr = curr.next
i += 1
return curr
def insertAt(self, pos, newNode):
if pos < 1 or pos > self.nodeCount + 1:
return False
if pos == 1:
newNode.next = self.head
self.head = newNode
else:
if pos == self.nodeCount + 1:
prev = self.tail
else:
prev = self.getAt(pos - 1)
newNode.next = prev.next
prev.next = newNode
if pos == self.nodeCount + 1:
self.tail = newNode
self.nodeCount += 1
return True
def getLength(self):
return self.nodeCount
def traverse(self):
result = []
curr = self.head
while curr is not None:
result.append(curr.data)
curr = curr.next
return result
def concat(self, L):
self.tail.next = L.head
if L.tail:
self.tail = L.tail
self.nodeCount += L.nodeCount(정리) dummy node 추가
연결 리스트의 최대 장점은 삽입과 삭제가 유연하다는 것이다. 쉽고, 빠르다. 맨 앞에 dummy node를 추가하여 이를 활용할 수 있다.
class Node:
def __init__(self, item):
self.data = item
self.next = None
class LinkedList:
def __init__(self):
self.nodeCount = 0
self.head = Node(None)
self.tail = None
self.head.next = self.tail
def __repr__(self):
if self.nodeCount == 0:
return 'LinkedList: empty'
s = ''
curr = self.head
while curr.next:
curr = curr.next
s += repr(curr.data)
if curr.next is not None:
s += ' -> '
return s
def getLength(self):
return self.nodeCount
def traverse(self):
result = []
curr = self.head
while curr.next:
curr = curr.next
result.append(curr.data)
return result
def getAt(self, pos):
if pos < 0 or pos > self.nodeCount:
return None
i = 0
curr = self.head
while i < pos:
curr = curr.next
i += 1
return curr
def insertAfter(self, prev, newNode):
newNode.next = prev.next
if prev.next is None:
self.tail = newNode
prev.next = newNode
self.nodeCount += 1
return True
def insertAt(self, pos, newNode):
if pos < 1 or pos > self.nodeCount + 1:
return False
if pos != 1 and pos == self.nodeCount + 1:
prev = self.tail
else:
prev = self.getAt(pos - 1)
return self.insertAfter(prev, newNode)
def concat(self, L):
self.tail.next = L.head.next
if L.tail:
self.tail = L.tail
self.nodeCount += L.nodeCount이처럼 리스트 맨 앞에 dummy node를 추가하는 것만으로도 코드가 좀 더 깔끔해질 수 있다.
🔗 양방향(이중, Doubly)
모든 연결이 양방향으로 이루어져 있는 연결 리스트 (인접한 두 개의 노드들이 서로 앞뒤로 연결) 이다.
(단점) 링크를 나타내기 위한 메모리 사용량이 늘어나고, 연산 시 앞/뒤 링크를 모두 조정해야 해서 코딩을 더 해야한다.
(장점) 유연하다. 데이터 원소들을 차례로 방문할 때, 앞에서 뒤로도 할 수 있지만 뒤에서부터 앞으로도 할 수 있다.
자료 구조
class Node:
def __init__(self, item):
self.data = item
self.prev = None
self.next = None
class DoublyLinkedList:
def __init__(self):
self.nodeCount = 0
self.head = Node(None)
self.tail = Node(None)
self.head.prev = None
self.head.next = self.tail
self.tail.prev = self.head
self.tail.next = None(정리) 양방향 연결 리스트
# doublylinkedlist
class Node:
def __init__(self, item):
self.data = item
self.prev = None
self.next = None
class DoublyLinkedList:
def __init__(self):
self.nodeCount = 0
self.head = Node(None)
self.tail = Node(None)
self.head.prev = None
self.head.next = self.tail
self.tail.prev = self.head
self.tail.next = None
def __repr__(self):
if self.nodeCount == 0:
return 'LinkedList: empty'
s = ''
curr = self.head
while curr.next.next:
curr = curr.next
s += repr(curr.data)
if curr.next.next is not None:
s += ' -> '
return s
def getLength(self):
return self.nodeCount
def traverse(self):
result = []
curr = self.head
while curr.next.next:
curr = curr.next
result.append(curr.data)
return result
def getAt(self, pos):
if pos < 0 or pos > self.nodeCount:
return None
if pos > self.nodeCount // 2:
i = 0
curr = self.tail
while i < self.nodeCount - pos + 1:
curr = curr.prev
i += 1
else:
i = 0
curr = self.head
while i < pos:
curr = curr.next
i += 1
return curr
def insertAfter(self, prev, newNode):
next = prev.next
newNode.prev = prev
newNode.next = next
prev.next = newNode
next.prev = newNode
self.nodeCount += 1
return True
def insertAt(self, pos, newNode):
if pos < 1 or pos > self.nodeCount + 1:
return False
prev = self.getAt(pos - 1)
return self.insertAfter(prev, newNode)🔗 순환(원형, Circular)
# 원형 이중 연결 리스트
from __future__ import annotations
from typing import Any, Type
class Node:
def __init__(self, data, prev, next) -> None:
self.data = data # 데이터
self.prev = prev or self # 앞쪽 포인터
self.next = next or self # 뒤쪽 포인터
class DoubleLinkedList:
def __init__(self) -> None:
self.head = self.current = Node() # 더미 노드를 생성
self.no = 0
def __len__(self) -> int:
return self.no
def is_empty(self) -> bool:
return self.head.next is self.head
def search(self, data) -> Any:
"""data와 값이 같은 노드를 검색"""
cnt = 0
ptr = self.head.next # 현재 스캔 중인 노드
while ptr is not self.head:
if data == ptr.data:
self.current = ptr
return cnt # 검색 성공
cnt += 1
ptr = ptr.next # 뒤쪽 노드에 주목
return -1 # 검색 실패
def __contains__(self, data) -> bool:
return self.search(data) >= 0
def print_current_node(self) -> None:
"""주목 노드를 출력"""
if self.is_empty():
print('주목 노드는 없습니다.')
else:
print(self.current.data)
def print(self) -> None:
"""모든 노드를 출력"""
ptr = self.head.next # 더미 노드의 뒤쪽 노드
while ptr is not self.head:
print(ptr.data)
ptr = ptr.next
def print_reverse(self) -> None:
"""모든 노드를 역순으로 출력"""
ptr = self.head.prev # 더미 노드의 앞쪽 노드
while ptr is not self.head:
print(ptr.data)
ptr = ptr.prev
def next(self) -> bool:
"""주목 노드를 한 칸 뒤로 이동"""
if self.is_empty() or self.current.next is self.head:
return False # 이동할 수 없음
self.current = self.current.next
return True
def prev(self) -> bool:
"""주목 노드를 한 칸 앞으로 이동"""
if self.is_empty() or self.current.prev is self.head:
return False # 이동할 수 없음
self.current = self.current.prev
return True
def add(self, data) -> None:
"""주목 노드의 바로 뒤에 노드를 삽입"""
node = Node(data, self.current, self.current.next)
self.current.next.prev = node
self.current.next = node
self.current = node
self.no += 1
def add_first(self, data:) -> None:
"""맨 앞에 노드를 삽입"""
self.current = self.head # 더미 노드 head의 바로 뒤에 삽입
self.add(data)
def add_last(self, data) -> None:
"""맨 뒤에 노드를 삽입"""
self.current = self.head.prev # 꼬리 노드 head.prev의 바로 뒤에 삽입
self.add(data)
def remove_current_node(self) -> None:
"""주목 노드 삭제"""
if not self.is_empty():
self.current.prev.next = self.current.next
self.current.next.prev = self.current.prev
self.current = self.current.prev
self.no -= 1
if self.current is self.head:
self.current = self.head.next
def remove(self, p: Node) -> None:
"""노드 p를 삭제"""
ptr = self.head.next
while ptr is not self.head:
if ptr is p: # p를 발견
self.current = p
self.remove_current_node()
break
ptr = ptr.next
def remove_first(self) -> None:
"""머리 노드 삭제"""
self.current = self.head.next # 머리 노드 head.next를 삭제
self.remove_current_node()
def remove_last(self) -> None:
"""꼬리 노드 삭제"""
self.current = self.head.prev # 꼬리 노드 head.prev를 삭제
self.remove_current_node()
def clear(self) -> None:
"""모든 노드를 삭제"""
while not self.is_empty(): # 리스트 전체가 빌 때까지
self.remove_first() # 머리 노드를 삭제
self.no = 0
def __iter__(self) -> DoubleLinkedListIterator:
"""반복자를 반환"""
return DoubleLinkedListIterator(self.head)
def __reversed__(self) -> DoubleLinkedListReverseIterator:
"""내림차순 반복자를 반환"""
return DoubleLinkedListReverseIterator(self.head)
class DoubleLinkedListIterator:
"""DoubleLinkedList의 반복자용 클래스"""
def __init__(self, head: Node):
self.head = head
self.current = head.next
def __iter__(self) -> DoubleLinkedListIterator:
return self
def __next__(self) -> Any:
if self.current is self.head:
raise StopIteration
else:
data = self.current.data
self.current = self.current.next
return data
class DoubleLinkedListReverseIterator:
"""DoubleLinkedList의 내림차순 반복자용 클래스"""
def __init__(self, head: Node):
self.head = head
self.current = head.prev
def __iter__(self) -> DoubleLinkedListReverseIterator:
return self
def __next__(self) -> Any:
if self.current is self.head:
raise StopIteration
else:
data = self.current.data
self.current = self.current.prev
return data출처
프로그래머스 데브코스 데이터 엔지니어링
Do it! 자료구조와 함께 배우는 알고리즘
