"표를 사러 일렬로 늘어선 사람들로 이루어진 줄"이라는 의미로, 자료를 보관할 수 있는 선형 구조이다. 대기열이라고도 한다. (비선형 데이터 구조의 큐도 존재한다.)
큐는 각 요소에 우선순위를 부여한다.
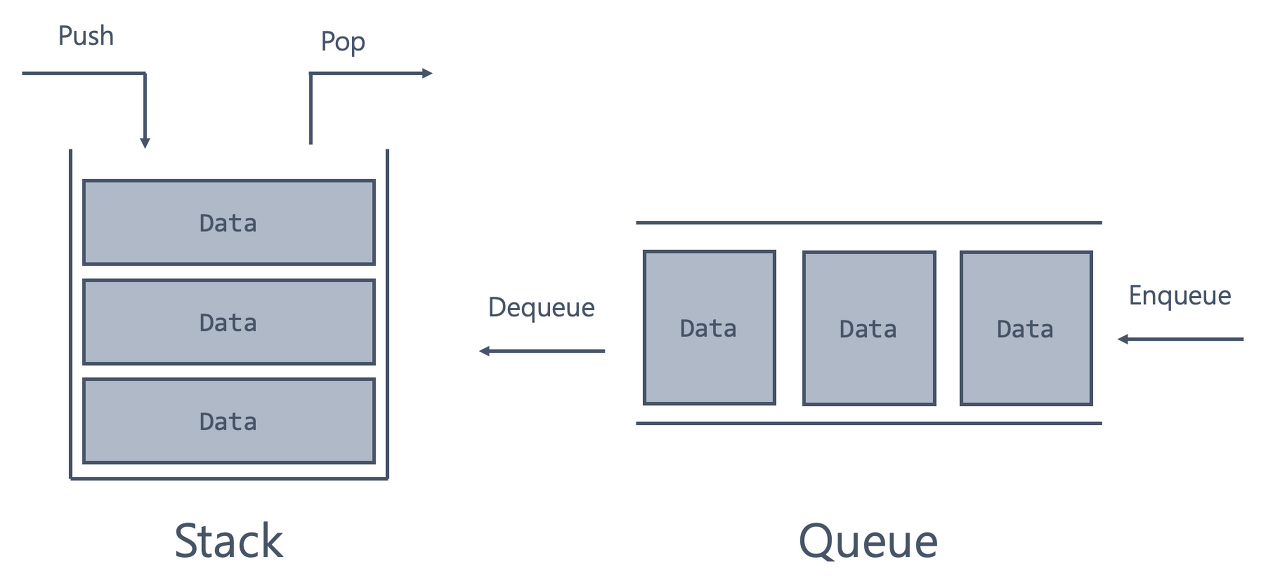
선입선출 구조 (FIFO, First-In First-Out): 데이터가 순서대로 쌓이며 가장 처음에 삽입된 자료가 가장 먼저 삭제- 데이터를 꺼내는 쪽을
프런트 front, 넣는 쪽을리어 rear라고 한다.
큐의 핵심 연산은 다음과 같다.
- 데이터 원소를 큐에 넣는 동작 :
인큐 (enqueue) 연산 - 큐로부터 데이터 원소를 꺼내는 동작 :
디큐 (dequeue) 연산
큐가 잘 활용되는 경우 다음과 같다.
- 자료를 생성하는 작업과 그 자료를 이용하는 작업이 비동기적으로 일어나는 경우
- 자료를 생성하는 작업이 여러 곳에서 이용하는 경우
- 자료를 이용하는 작업이 여러 곳에서 일어나는 경우
- 자료를 생성하는 작업과 그 자료를 이용하는 작업이 양쪽 다 여러 곳에서 일어나는 경우
- 자료를 처리하여 새로운 자료를 생성하고, 나중에 그 자료를 또 처리해야 하는 작업의 경우
큐의 동작
- 초기 상태 :
비어 있는 큐 (empty queue) Q.enqueue(Data)형태를 통해서 데이터를 쌓을 수 있고,Q.dequeue()형태를 통해서 맨 앞의 데이터를 꺼낼 수 있다.
추상적 자료 구조로 구현하기
여러 방법이 있지만, 대표적으로 배열을 이용하거나 연결 리스트를 이용해서 스택을 추상적 자료 구조로 구현할 수 있다.
- 방법1. 배열을 이용하여 구현하기
- 방법2. 연결 리스트를 이용하여 구현하기
큐의 추상적 자료구조 구현을 위한 연산은 다음과 같다.
size(): 현재 큐에 들어 있는 데이터 원소의 수를 구함isEmpty(): 현재 큐가 비어 있는지를 판단 (size() == 0?)enqueue(x): 데이터 원소 x 를 큐에 추가dequeue(): 큐의 맨 앞에 저장된 데이터 원소를 제거 (또한, 반환)peek(): 큐의 맨 앞에 저장된 데이터 원소를 참조 (반환), 그러나 제거하지는 않음
각각 배열과 연결리스트로 구현한 큐의 연산 복잡도 :
- 배열 :
dequeue()만Q(n)이고, 나머지는Q(1)이다. dequeue의 경우, 맨 앞의 원소를 꺼내면 뒤에 있는 원소들이 한 칸씩 앞으로 이동해야 하기 때문에 길이에 비례하게 연산이 이루어진다. - 반면 연결리스트로 구현한 큐의 연산 복잡도는?
from doublylinkedlist import Node
from doublylinkedlist import DoublyLinkedList
# 방법 1. 배열로 큐의 자료구조 구현하기
class AraayQueue :
def __init__(self) : # 빈 큐 초기화
self.data = []
def size(self) : # 큐의 크기를 리턴
return len(self.data)
def isEmpty(self) : # 큐가 비어있는지 판단 (T/F)
return self.size() == 0
def inqueue(self, item) : # 데이터 원소 추가
self.data.append(item)
def dequeue(self) : # 데이터 원소 삭제
return self.data.pop(0)
def peek(self) : # 큐의 맨 앞 원소 반환
return self.data[0]
# 방법 2. (양방향/이중) 연결 리스트로 스택의 자료구조 구현하기
class LinkedListQueue:
def __init__(self):
self.data = DoublyLinkedList()
def size(self):
return self.data.getLength()
def isEmpty(self):
return self.size() == 0
def inqueue(self, item):
node = Node(item)
self.data.insertAt(self.size() + 1, node)
def dequeue(self):
return self.data.popAt(self.size())
def peek(self):
return self.data.getAt(self.size()).data사실 파이썬에 이미 라이브러리가 존재한다.
from pythonds.basic.queue import Queue
환형 큐 (Circular Queue)
배열을 이용한 큐는 deaueue를 이용할 시 복잡도가 증가한다. 이러한 단점을 보완하기 위해 환형 큐(원형 큐)를 이용할 수 있다.
링 버퍼 ring buffer- 정해진 개수의 저장 공간을 빙 돌려가며 이용
front (데이터 꺼내는 곳),rear (데이터 입력하는 곳)두 개의 인덱스 변수가 존재
환형 큐의 추상적 자료구조 구현을 위한 연산은 다음과 같다. 나머지는 기본 큐와 동일하고, isFull() 연산이 새롭게 추가되었다.
size(): 현재 큐에 들어 있는 데이터 원소의 수를 구함isEmpty(): 현재 큐가 비어 있는지를 판단 (size() == 0?)isFull(): 큐에 데이터 원소가 꽉 차 있는지를 판단enqueue(x): 데이터 원소 x 를 큐에 추가dequeue(): 큐의 맨 앞에 저장된 데이터 원소를 제거 (또한, 반환)peek(): 큐의 맨 앞에 저장된 데이터 원소를 참조 (반환), 그러나 제거하지는 않음
# 선형 배열로 구현한 환형 큐
class CircularQueue :
def __init__(self, n) : # 빈 큐를 초기화, 인자로 주어진 최대 큐 길이 설정
self.maxCount = n
self.data = [None]*n # 실제 데이터를 저장하려는 공간
self.count = 0 # 현재 큐에 들어있는 데이터의 갯수
self.front = -1
self.rear = -1
def size(slef) : # 현재 큐 길이 반환
return self.count == 0
def isEmpty(self) : # 큐가 비어있는가?
return self.count == 0
def isFull(self) : # 큐가 꽉 차있는가?
return self.count == self.maxCount
def endqueu(self, x) :
if self.isFull() :
raise IndexError('Queue full')
# IndexError('Queue full') exception 으로 처리
self.data[self.rear] = x
self.rear += 1
self.count += 1
if self.rear == self.maxCount :
self.rear = 0
def dequeue(self) :
if self.isEmpty():
raise IndexError('Queue empty')
x = self.data[self.front]
self.front += 1
self.count -= 1
if self.front == self.maxCount :
self.front = 0
return x
def peek(self) :
if self.isEmpty():
raise IndexError('Queue empty')
return self.data[self.front]# 추가적으로 구현할 수 있는 기능
def find(self, value):
# 큐에서 value를 찾아 인덱스를 반환
for i in range(self.count):
idx = (i + self.front) % self.maxCount
if self.data[idx] == value:
return idx
return -1
def count_value(self, value):
# 큐에 있는 value의 개수를 반환
c = 0
for i in range(self.count) :
idx = (i + self.front) % self.maxCount
if self.data[idx] == value:
c += 1
return c
def __contains__(self, value):
# 큐에 value가 있는지 판단
return self.count_value(vlaue)
def clear(self):
# 큐의 모든 데이터를 비움
self.count = self.front = self.rear = 0우선순위 큐 Priority Queue
먼저 들어오는 데이터가 아니라, 우선순위가 높은 데이터가 먼저 나가는 형태의 자료구조이다. 큐에서 원소를 꺼내는 원칙은 원소들 사이의 우선순위를 따른다.
우선순위 큐는 키와 값의 체계를 사용해 큐의 요소들을 정렬한다. 모든 요소는 우선순위가 있으며 이는 키에 해당한다.
키 key: 값을 식별하고 검색하는 데 사용값 value: 실제 사용하는 데이터
우선순위 큐는 일부 알고리즘뿐만 아니라 데이터 압축, 네트워킹, 수많은 컴퓨터 과학 분야의 응용 프로그램에서도 사용된다.
우선순위 큐의 구현
접근 방법 :
➀ 큐에 원소를 넣을 때 (enqueue) 우선순위 순서대로 정렬해두는 방법
➁ 큐에서 원소를 꺼낼 때 (dequeue) 우선순위가 가장 높은 것을 선택하는 방법
⇨ ➀이 더 유리하다.
구현 방법 :
➀ 배열 : 공간적 유리
➁ 연결 리스트 : 시간적 유리
⇨ 이 중에선 시간적으로 유리한 ➁를 선택한다.
➂ 힙을 통한 구현
# 연결 리스트로 구현한 우선순위 큐
from doublylinkedlist import Node, DoublyLinkedList
class PrioityQueue :
def __init__(self, x) : # 빈 큐 초기화
self.queue = DoublyLinkedList()
def enqueue(self, x) :
newNode = Node(x)
curr =
while and : # 끝을 만나지 않을 조건, 우선순위 조건
curr = curr.next
slef.queue.(curr, newNode) # InsertBefore? After?
양방향 연결 리스트의 getAt() 메서드는 이용하지 않고, curr가 하나하나 이동하게 해야 한다. getAt() 메서드를 이용하면 어떤 포지션이 주어졌을 때, 반복문이 실행되는 동안 매번 그 포지션까지 칸을 세어가면서 진행을 하게 되기 때문이다.
출처
programmers
roi-data.com
