파이썬 자료형을 이해하기 전에 알아야 될 개념들입니다.
- "파이썬의 모든 자료형은 클래스이다."
- "str, list, tuple, dict 등 for문에서 원소 하나씩 순회 가능한 자료형들을 파이썬에서는 Iterable(이터러블)이라고 합니다. int, float는 반복문을 쓸 수 없기에 이터러블이 아니다."
- 객체(클래스/인스턴스 모두)의 변수와 메소드를 모두 보여주는 함수 dir(), help()를 활용하면 해당 객체에서 사용할 수 있는 변수와 메소드를 다 알 수 있다.
-> 인자로 클래스, 인스턴스 모두 다 가능함
1. List + List 메소드
Mutable(수정 가능함) 반면, Tuple은 Immutable
Tuple은 수정하지 않을 자료에 사용해야 함
1) Slicing
- start는 포함됨. stop은 포함 안 되고, 그 전 값까지만 포함.
list_name[start : stop : step]2) 요소 추가하기 : append, insert, extend
courses = ['History', 'Math', 'Physics', 'CompSci']
courses_2 = ['Art', 'Business']
# 리스트 마지막에 추가
> courses.append('Math')
['History', 'Math', 'Physics', 'CompSci', 'Math']
# 리스트 특정 인덱스에 요소 추가
> courses.insert(0, 'Art')
['Art', 'History', 'Math', 'Physics', 'CompSci']
# 리스트를 추가할 때 요소만 추가하고 싶다면, extend를 사용
> courses.insert(0, courses_2)
[['Art', 'Business'], 'History', 'Math', 'Physics', 'CompSci']
> courses.append(courses_2)
['History', 'Math', 'Physics', 'CompSci', ['Art', 'Business']]
> courses.extend(courses_2)
['History', 'Math', 'Physics', 'CompSci', 'Art', 'Business']
> courses + courses_2
['History', 'Math', 'Physics', 'CompSci', 'Art', 'Business']3) 요소 삭제하기 : remove, pop
courses = ['History', 'Math', 'Physics', 'CompSci']
> courses.remove('Math')
['History', 'Physics', 'CompSci']
# 삭제된 요소와 남아있는 요소 각각을 변수로 사용 가능 (큐 처리에 유용)
> popped = courses.pop()
> print(courses)
> print(popped)
['History', 'Math', 'Physics']
CompSci4) 역순 및 정렬 : reverse, sort
courses = ['History', 'Math', 'Physics', 'CompSci']
> courses.reverse()
['CompSci', 'Physics', 'Math', 'History']
# 문자는 알파벳 오름차순, 숫자는 오름차순
> courses.sort()
['CompSci', 'History', 'Math', 'Physics']
# 정렬 역순
> courses.sort(reverse=True)
['Physics', 'Math', 'History', 'CompSci']
# 원래 리스트 수정 없이 새로운 변수에 정렬된 리스트 담기
> sorted_courses = sorted(courses)
['CompSci', 'History', 'Math', 'Physics']
리스트 삭제 (del, remove)
del list[인덱스]2. Tuple
- 한 번 선언되면 수정 불가
# Mutable
list_1 = ['History', 'Math', 'Physics', 'CompSci']
list_2 = list_1
list_1[0] = 'Art'
> print(list_1)
> print(list_2)
['Art', 'Math', 'Physics', 'CompSci']
['Art', 'Math', 'Physics', 'CompSci']# Immutable
tuple_1 = ('History', 'Math', 'Physics', 'CompSci')
tuple_2 = tuple_1
tuple_1[0] = 'Art'
> print(tuple_1)
> print(tuple_2)
TypeError: 'tuple' object does not support item assignment
# 리스트를 tuple로 변환
tuple(list)3. Set
cs_courses = {'History', 'Math', 'Physics', 'CompSci'}
art_courses = {'History', 'Math', 'Design', 'Music'}
# 중복되는 값 리턴
print(cs_courses.intersection(art_courses))
{'Math', 'History'}
# 중복되지 않는 값 리턴
print(cs_courses.difference(art_courses))
{'Physics', 'CompSci'}
# 중복되지 않는 고유한 값들을 합쳐서 리턴
print(cs_courses.union(art_courses))
{'Music', 'CompSci', 'Math', 'History', 'Design', 'Physics'}# 리스트 -> set으로 변환
set(list)
# set에 요소 추가/삭제 (Add, Remove)
my_set.add(4) # append가 아님에 유의
my_set.remove(3)
# 요소 찾아보기 (Look up)
my_set = {1, 2, 3}
if 1 in my_set:
print("1 is in the set")- Array와 달리 set은 요소들을 순차적으로 저장하지 않음
- Set에서 요소들이 저장될 때 순서는 다음과 같음
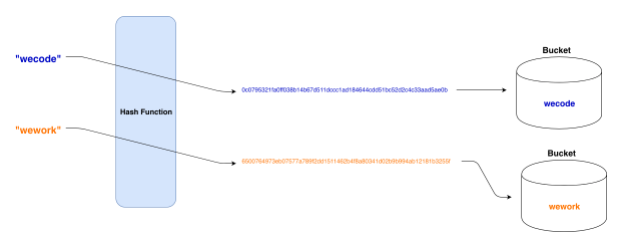
- 저장할 요소의 값의 hash 값을 구한다.
- 해쉬값에 해당하는 공간(bucket)에 값을 저장한다.
- 이렇게 set는 저장하고자 하는 값의 해쉬값에 해당하는 bucket에 값을 저장하기 때문에 순서가 없다. 순서가 없기 때문에 indexing도 없다.
- 그리고 해쉬값 기반의 bucket에 저장하기 때문에 중복된 값을 저장할 수 없는것이다.
- 해쉬값을 기반으로 저장하기 때문에 look up 이 굉장히 빠름.
- Look up: 특정 값을 포함하고 있는지를 확인 하는것 ==> 5 in my_set
- Set의 총 길이와 상관없이 단순히 해쉬값 계산 후 해당 bucket 을 확인하면 됨으로 O(1)
언제사용하는가?
- 중복된 값을 골라내야 할 때
- 빠른 look up을 해야 할 때
- 그러면서 순서는 상관 없을 때
[활용사례]
# 중복 검사 함수
def isDuplicated(arr):
in_set = set(arr)
return len(in_set)<len(arr)
my_list = [1,2,2,3,3,4,5]
my_list2 = [1,2,3]
print(isDuplicated(my_list))
print(isDuplicated(my_list2))
# 유일한 값을 가지는 list를 생성
new_list = list(set(my_list))
print(new_list)4. Empty list, tuple, set 만들기
# Empty Lists
empty_list = []
empty_list = list()
# Empty Tuples
empty_tuple = ()
empty_tuple = tuple()
# Empty Sets
empty_set = {} # This isn't right! It's a dict
empty_set = set()5. Dictionary
- Key-value 형태의 값을 저장할 수 있는 자료구조
- Set과 마찬가지로 특정 순서대로 데이터를 리턴하지 않음
- Key 값은 중복될 수 없음. 만약 중복된 key가 있다면 먼저 있던 key와 value를 대체함
- 수정 가능함(mutable)
Dictionary의 내부구조
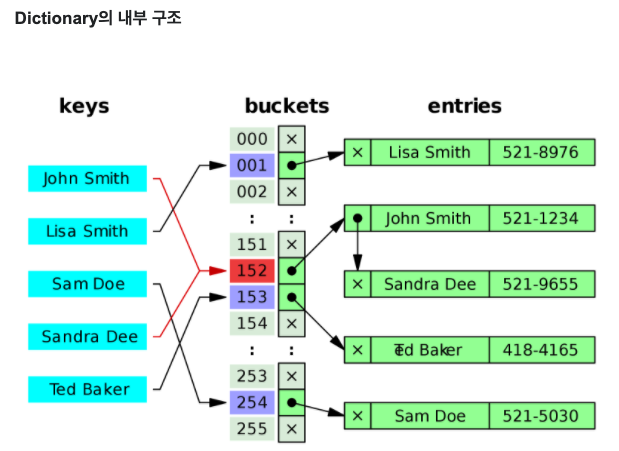
- Set과 비슷하게 key 값의 해쉬값을 구한 후 해쉬값에 속해있는 bucket에 값을 저장함
- 그럼으로 set과 마찬가지로 순서가 없고 중복된 key 값은 허용되지 않음
언제사용하는가?
- 데이터베이스처럼 키와 값을 묶어서 데이터를 표현할 때 사용함.
- 실제 데이터베이스에서 읽어들인 값을 dictionary로 변환해서 자주 사용함.
student = {'name': 'John', 'age': 25, 'courses': ['Math', 'CompSci']}
# 존재하지 않는 키를 호출 -> KerError 발생
> print(student['phone'])
KeyError: 'phone'
# 예방하기 위해 get 메소드 사용
> print(student.get('phone'))
None
> print(student.get('phone', 'Not Found'))
Not Found
# 딕셔너리 데이터 업데이트
> student.update({'name': 'Kane', 'age': 44})
> print(student)
{'name': 'Kane', 'age': 44, 'courses': ['Math', 'CompSci']}
# 데이터 삭제하기 (del student['age']도 가능)
> age = student.pop('age')
> print(student)
{'name': 'John', 'courses': ['Math', 'CompSci']}
> print(age)
25
# 키, 값 리스트로 보기
> print(len(student))
> print(student.keys())
> print(student.values())
> print(student.items())
3
dict_keys(['name', 'age', 'courses'])
dict_values(['John', 25, ['Math', 'CompSci']])
dict_items([('name', 'John'), ('age', 25), ('courses', ['Math', 'CompSci'])])
# For-loop : 그냥 돌리면 키만 출력됨
> for key in student:
> print(key)
name
age
courses
# 딕셔너리는 items으로 접근해서 루프를 돌려야 함
> for key, value in student.items():
> print(key, value)
name John
age 25
courses ['Math', 'CompSci']
안녕하세요!