.jpeg) ### 1. 크롤링을 위한 사전준비
### 1. 크롤링을 위한 사전준비
설치할 모듈 설치 및 import하기
- requests
- Beautiful Soup
from bs4 import BeautifulSoup
import requests2. requests 이해하기
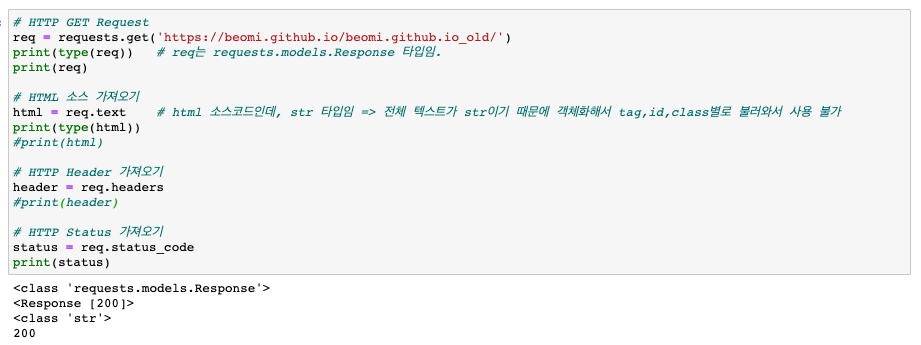
- requests.get 함수로 괄호 안의 url주소에 접속을 요청하여 해당 페이지안의 데이터를 받아와서 req 변수에 담기
- req.text로 변수 안에서 html 소스코드만 추출함
- requests로 가져온 데이터는 그냥 str이기 때문에 tag, id, class별로 객체화하여 속성값에 접근하는 것이 안 됨
- 이 때문에 해당 html 소스를 tag, id, class로 객체화하여 쓸 수 있는 BeautifulSoup이 등장함
3. BeautifulSoup 이해하기
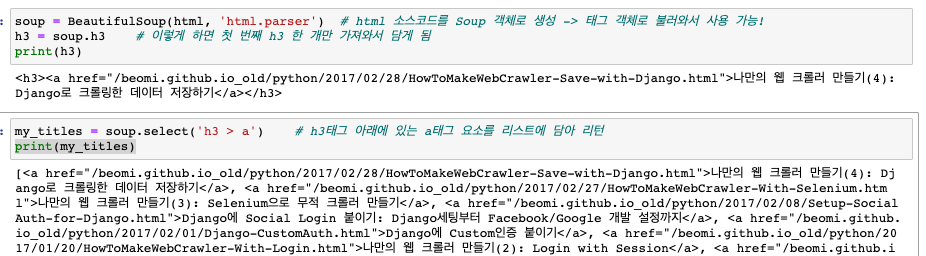

- html 소스를 BeautifulSoup을 이용해 객체화한 뒤 soup이란 변수에 담기
- 담은 변수를 통해 다양한 속성값에 접근을 할 수 있음
[주요 명령어]
soup.prettify() # preffity() 메소드를 통해서 구조적으로 이쁘게 보이게 함
soup.title # 타이틀 태그를 가져옴
soup.title.parent.name # 타이틀의 부모태그 이름을 가져옴
soup.p # 첫 번째 p 태그 정보를 가져옴
soup.find_all('a') #a태그들을 리스트로 가져옴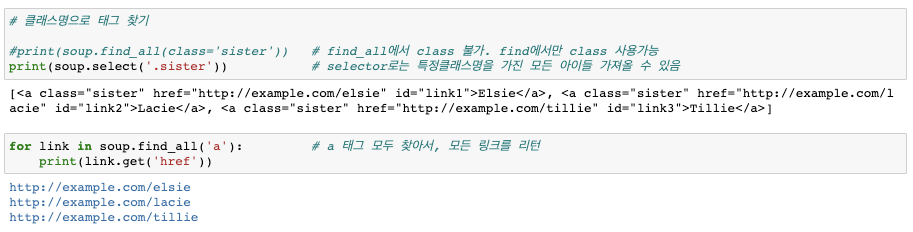
[참고 사이트] https://www.crummy.com/software/BeautifulSoup/bs4/doc.ko/

안녕하세요!