사용자와 스키마
오라클디비는 표를 만들고 그 표에 정보를 기록하고 읽는 것이 목적이고,
스키마는 연관된 표들을 묶어주는 일종의 디렉토리다.
사용자에 해당되는 스키마가 만들어진다.
사용자 생성
cmd에서 sqlplus 입력 후 user-name, password 입력
cmd -> sqlplus 입력
sys: 기본적으로 주어지는 사용자
SYSDBA: 시스템 데이터베이스 관리자로서 사용하겠다

오라클 사이트에서 create user 문서 확인하기
오라클 사용자 생성 바로가기
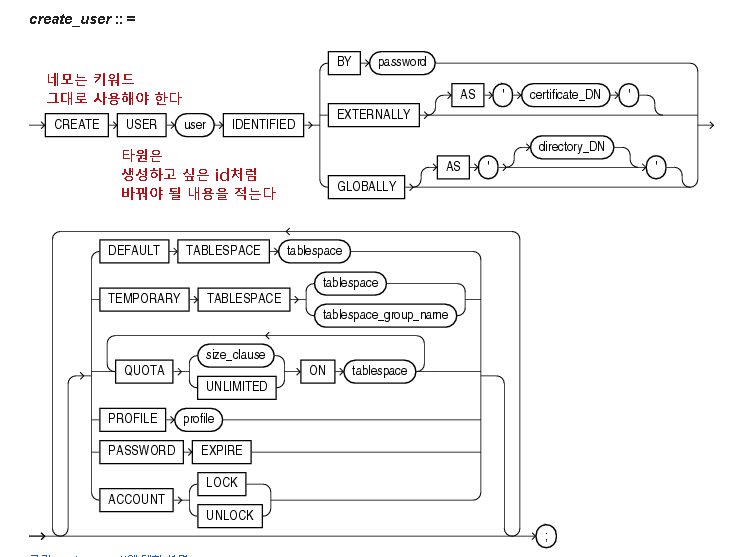
출처 : 오라클 doc
CREATE USER user-name IDENTIFIED BY password 입력
키워드는 대문자로 적는다.(CREATE USER, IDENTIFIED BY)
예시
user-name: userCreate
password: 111111

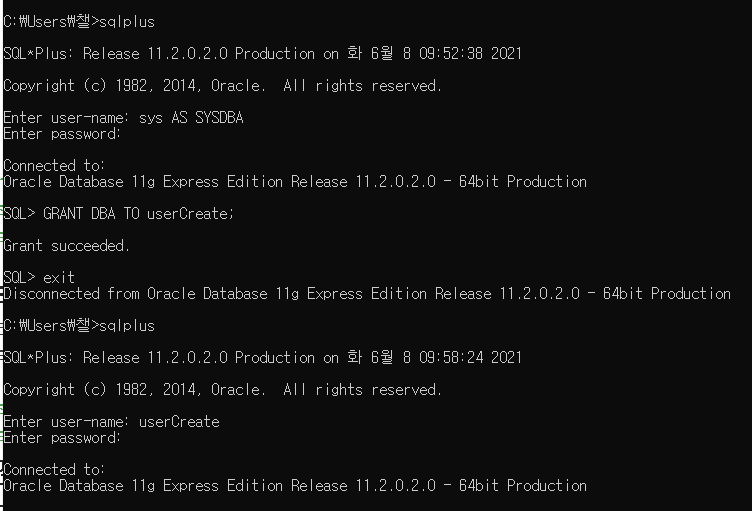
사용자 권한 부여
cmd에서 sqlplus 입력 후 user-name, password 입력
sys AS SYSDBA로 접속한다.
GRANT DBA TO user-name; 입력
데이터 베이스 사용자에게 데이터베이스 관리자의 권한을 주겠다라는 의미다.
userCreate를 만들고 나서 접속을 하려고 할 때 권한이 없다는 에러가 떴는데,
사용자를 생성하고 나서 sys AS SYSDBA로 접속해 권한을 주는 명령를 실행 하고 나면
생성된 데이터 베이스 사용자에 접속할 수 있다.
테이블 생성-1
구글에 create table sql references oracle 검색
오라클 테이블 생성 바로가기
오라클 사이트와 구글에서 검색된 테이블 생성과 관련된 포스팅을 찾아본다.
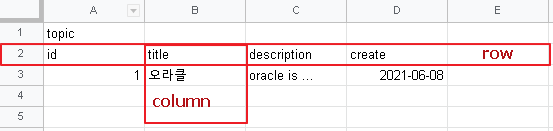
엑셀 같은 프로그램으로 테이블을 만들어 본다.
테이블 생성-2
필요한 명령을 구글에 검색하여 만든다.
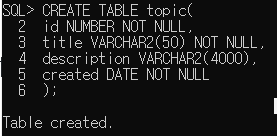
-- 토픽이라는 테이블을 만들라고 데이터베이스에게 지시한다.
CREATE TABLE topic(
-- 첫번째 컬럼은 id이고 반드시 숫자만 넣을 수 있다.
id NUMBER NOT NULL,
-- 몇 글자가 들어올 건지 VARCHAR2 뒤에 적는다.
-- 제목을 반드시 써야하고 50자 보다 크면 자른다.
title VARCHAR2(50) NOT NULL,
description VARCHAR2(4000),
created DATE NOT NULL
);
어떤 표가 나의 스키마에 존재하는지 알아보기 위해 TABLE 목록 조회를 검색하여 만든다.
SELECT table_name FROM all_tables WHERE OWNER = user_name;행 추가
INSERT INTO table-name
가독성을 높이기 위해 아래로 내려서 작성하였다.
INSERT INTO topic
(id, title, description, created)
VALUES
(1, 'ORACLE', 'ORACLE is ...', SYSDATE);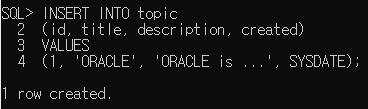
행이 만들어진 후 commit;을 입력한다.
SQL이란?
엑셀은 행을 추가할 때 한계가 있다.
데이터 베이스는 저장장치의 한계가 없다면 엄청나게 많은 데이터를 저장할 수 있고,
원하는 데이터를 꺼내올 때 설계를 잘한다면 0.1초도 안걸리게 가지고 올 수 있다.
그리고 명령어를 통해서 데이터베이스를 제어할 수 있다.(자동화가 가능하다.)
여기서 명령어는 SQL이라고 부른다.
SQL은 Structured Query Language의 약자이며 구조화된 정보를 다루는 언어다라는 뜻이다.
행 읽기 - Select문의 기본 형식
read를 sql을 통해서 하는 방법을 살펴본다.
read는 데이터 베이스를 가져오는 작업이며 기능이 많아서 어렵다.
SELECT * FROM table-name;
모든 행을 가져오는 명령이다.

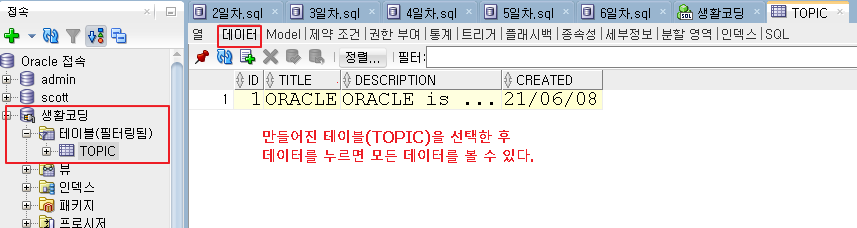
SQL Developer에서 테이블 -> Data 탭 클릭
행 읽기 - 행과 컬럼 제한하기
SELECT column-name, column-name FROM table-name;
cloumn을 제한하는 방법으로,
table-name의 테이블의 컬럼 중에 coloum-name을 보겠다는 명령이다.
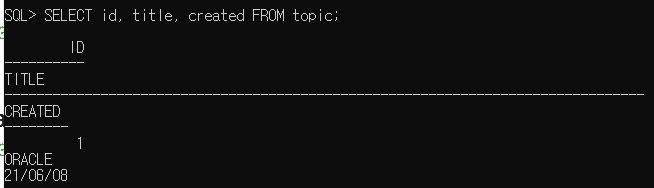
예시
topic에서 id, title, created를 가져오기
SELECT * FROM table-name WHERE column-name 연산자 column-name에 들어있는 값;
row를 제한하는 방법으로,
table-name의 테이블의 컬럼 중에 조건이 맞는 coloum-name의 row의 데이터를 가지고 온다.
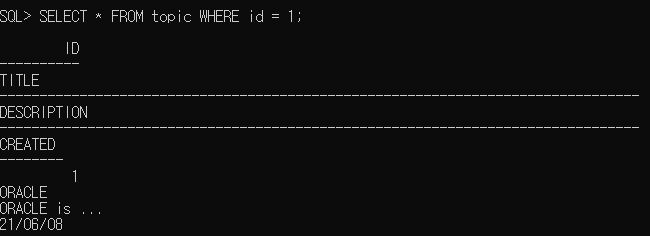
예시) topic에서 id가 1인 row만 가져오기
SELECT * FROM topic WHERE id = 1;
예시) topic에서 id가 1보다 큰 값을 가지고 있는 row 가져오기
SELECT * FROM topic WHERE id > 1;
행 읽기 - 정렬과 페이징
출력된 결과의 정렬 상태를 바꾸고 출력되는 행의 개수를 바꾸는 방법을 알아본다.
SELECT * FROM table-name ORDER BY column-name DESC/ASC;
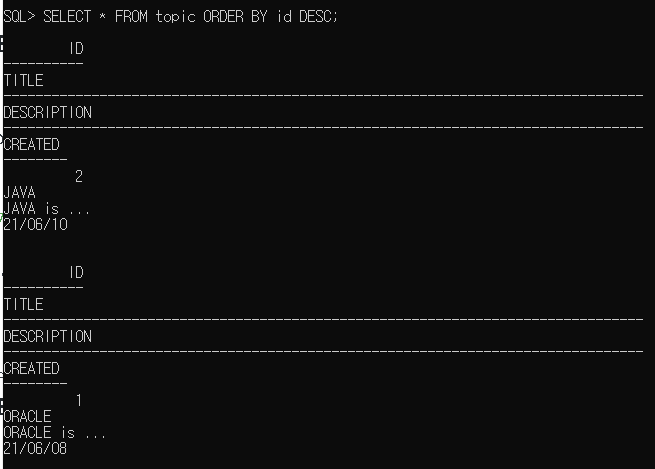
예시) topic 테이블의 컬럼인 id를 정렬을 하는데 큰 숫자가 먼저 나오게 하기
페이징
데이터가 너무 많을 때 사용하는 기법이다. 데이터가 조각 조각내서 가져온다.
사용 예시
SELECT * FROM topic OFFSET 1 ROWS FETCH NEXT 2 ROWS ONLY;
행 수정(UPDATE)
UPDATE table-name SET column-name = '바꿀 값' WHERE 조건;
예시) topic 테이블에서 id가 3인 행의 title을 MSSQL로 변경하기
UPDATE topic SET title = 'MSSQL' WHERE id=3;
수정 후에 실제로 반영되도록 commit을 꼭 해야한다.
행 삭제(DELETE)
DELETE FROM table-name WHERE 조건;
예시) topic 테이블에서 id가 3인 행을 삭제하기
DELETE FROM topic WHERE id=3;
PRIMARY KEY
PRIMARY KEY를 지정할려면 테이블을 생성할 때 추가하는 것이 좋다.
기존 토픽 테이블을 제거하고(DROP TABLE topic;)
테이블을 다시 생성하면서 id에 PRIMARY KEY를 준다.
--테이블 생성 코드
CREATE TABLE topic(
id NUMBER NOT NULL,
title VARCHAR2(50) NOT NULL,
description VARCHAR2(4000),
created DATE NOT NULL,
---여기까지 위에서 생성한 코드와 동일
---PRIMARY KEY 관련 추가한 내용
CONSTRAINT PK_TOPIC PRIMARY KEY(id)
);행을 다시 추가하면서 id 값이 동일한 행을 추가해본다.
INSERT INTO topic
(id, title, description, created)
VALUES
(1, 'ORACLE', 'ORACLE is ...', SYSDATE);
--위에서 추가한 행과 id값 동일
INSERT INTO topic
(id, title, description, created)
VALUES
(1, 'JAVA', 'JAVA is ...', SYSDATE);unique constraint violated 에러가 뜬다.
즉, PRIMARY KEY가 지정된 값을 가진 행은 그 표안에서 유일무이하다는 것을 알 수 있다.
그래서 PRIMARY KEY가 지정된 값을 테이블에서 찾는 것은 속도가 빠르다.
SEQUENCE
SEQUENCE는 PRIMARY KEY와 자주 함께 사용된다.
SEQUENCE와 관련된 다양한 옵션이 있다.
CREATE SEQUENCE sequence-name;
시퀀스를 생성하는 명령이다.
예시로 SEQ_TOPIC이라는 SEQUENCE를 생성한다면
CREATE SEQUENCE SEQ_TOPIC;sequence-name.NEXTVAL
행을 추가할 때 id 값을 1씩 증가하게 sequence를 넣기 위해 사용한다.
테이블에 행을 추가한다면 id 자리에 SEQ_TOPIC.NEXTVAL를 추가하면 된다.
INSERT INTO topic
(id, title, description, created)
VALUES
(SEQ_TOPIC.NEXTVAL, 'JAVA', 'JAVA is ...', SYSDATE);SELECT sequence-name.CURRVAL FROM table-name;
현재 SEQUENCE 값을 알아볼 때 사용한다.
테이블의 분해 조립 - 분해하기
Relation
표라고 하는 데이터의 형태로 데이터를 다룬다.
표를 필요에 따라서 잘게 쪼갤 수 있고, 결합하여 사용할 수 있다.
하나의 표를 성격에 따라서 쪼개면 불필요한 반복 수정을 줄일 수 있다.
예시) topic 테이블에서 author라는 성격을 가진 테이블 따로 분해하기
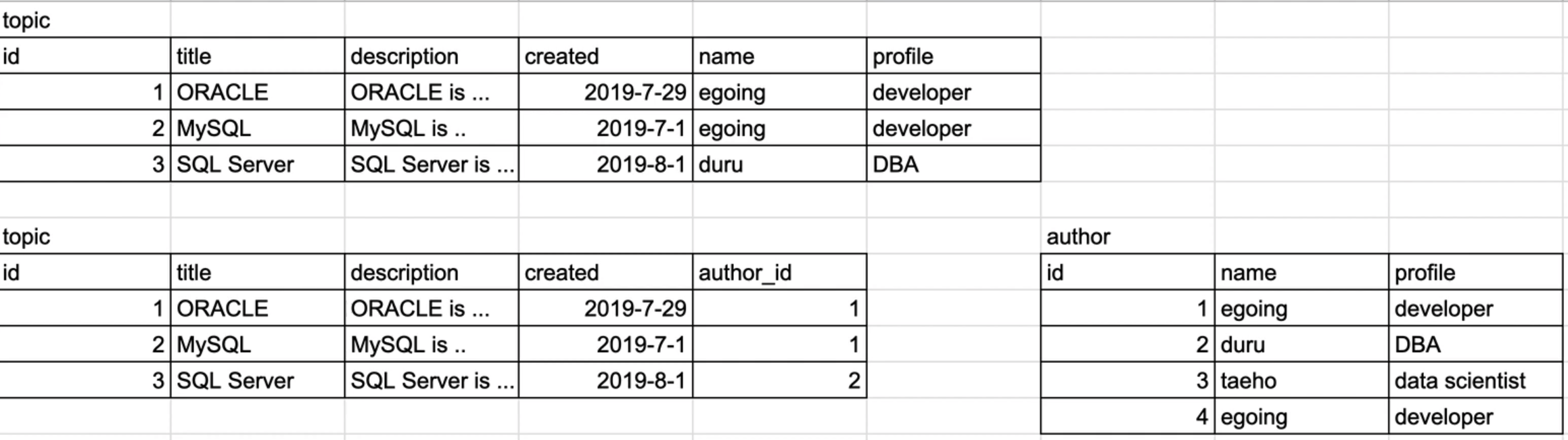
테이블의 분해의 장점과 단점, 해결방법
- 수정이 편해진다
- 읽기가 불편하다
- 해결 방법 : 필요에 따라 표들을 조립해서 마치 원래 있었던 표처럼 만든다. => 조인
테이블의 분해 조립 - 조립하기
테이블 성격에 맞게 topic과 author테이블로 나누었는데,
topic의 author_id 안에 author 테이블의 row 중 조건이 맞는 값을 넣어서 출력하려고 한다.
topic

author
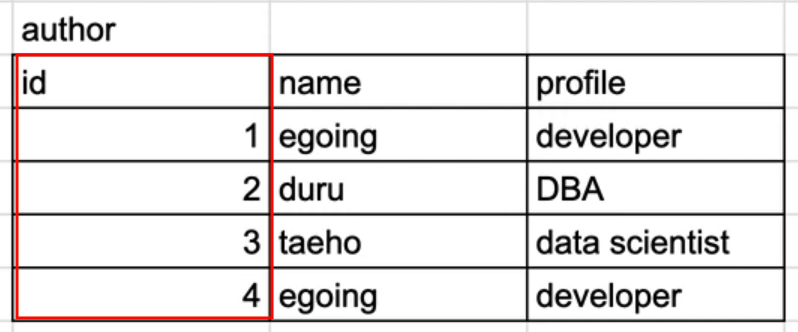
JOIN의 사용
author의 id와 topic의 author_id의 값이 같을 경우 topic의 행을 보여줄 때 author의 해당하는 행도 함께 붙여서 보여주기 위해 명령을 작성한다.
SELECT * FROM topic LEFT JOIN author ON topic.author_id = author.id;SQL Developer를 이용하여 테이블 생성하고, JOIN 해보기
TOPIC, AUTHOR 테이블 생성
예시)AUTHOR 테이블 생성
등록한 데이터베이스를 우클릭하고 새 테이블을 누른다.
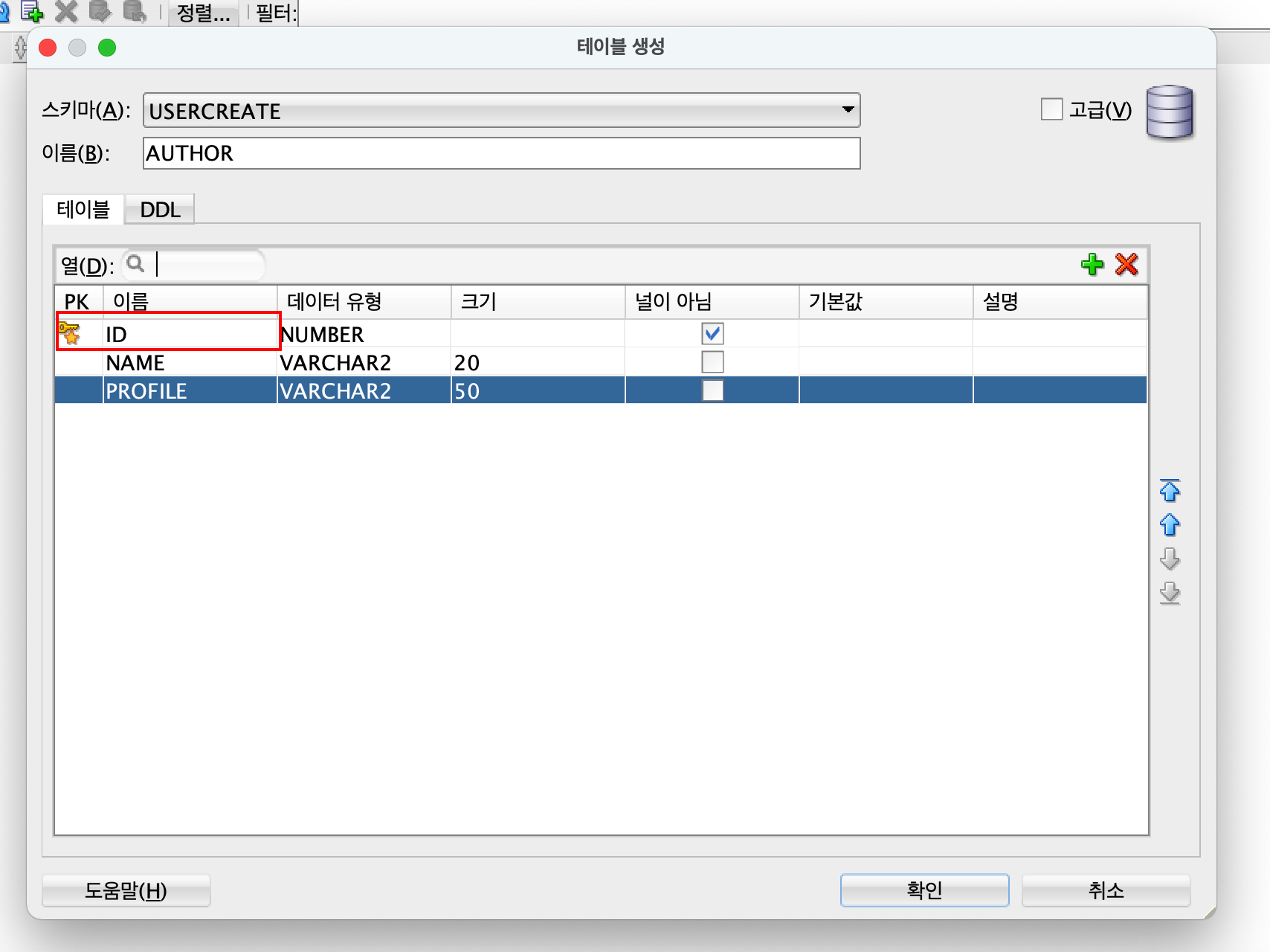
이름과 필요한 행을 추가하고 다 추가하였으면 확인을 누른다.
DDL을 누르면 내가 추가한 행을 sql 명령으로 바꿔서 보여준다.
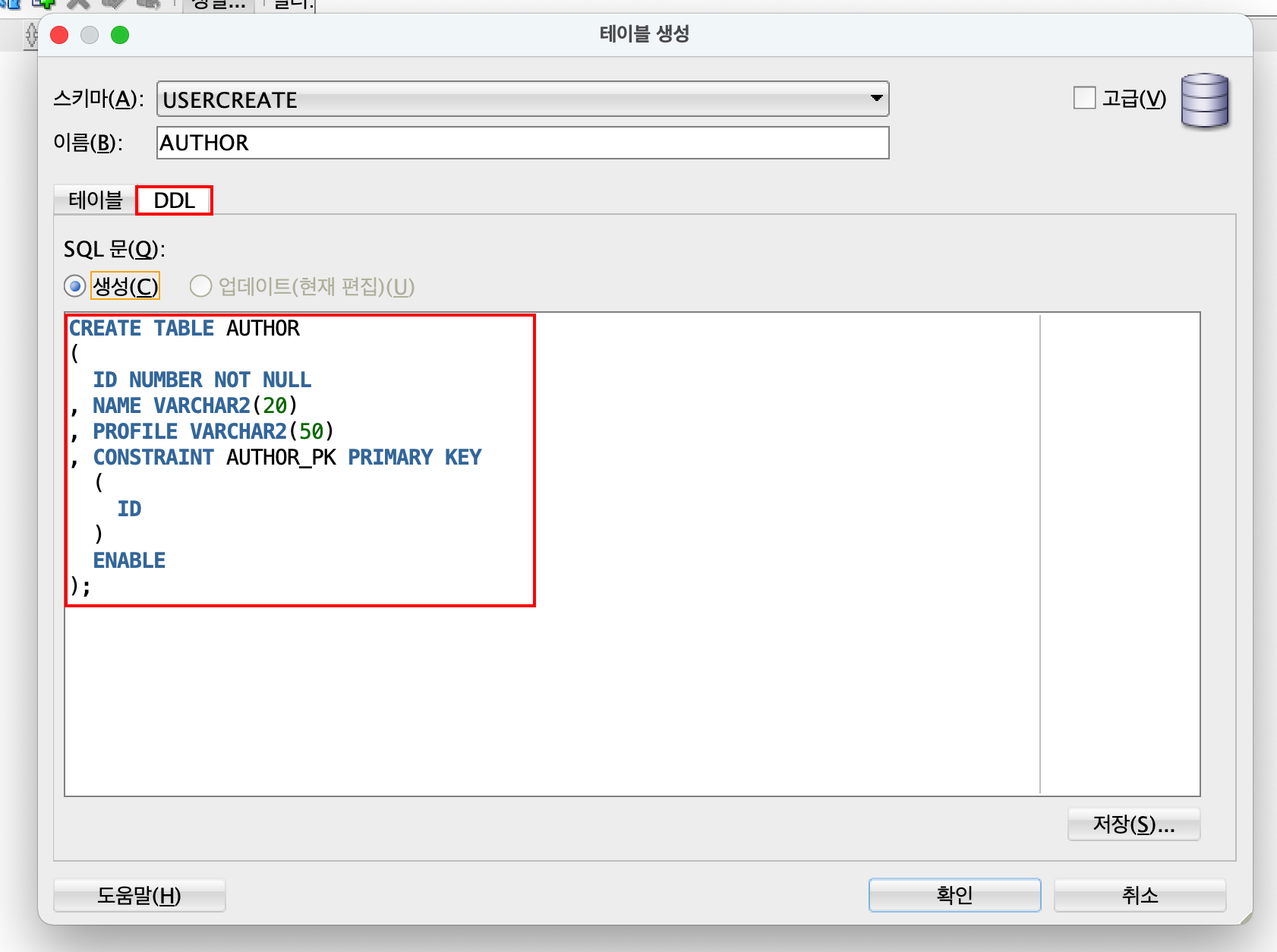
AUTHOR의 id는 PRIMARY KEY로 지정을 하였고 행 추가시 사용할 SEQUENCE를 생성한다.
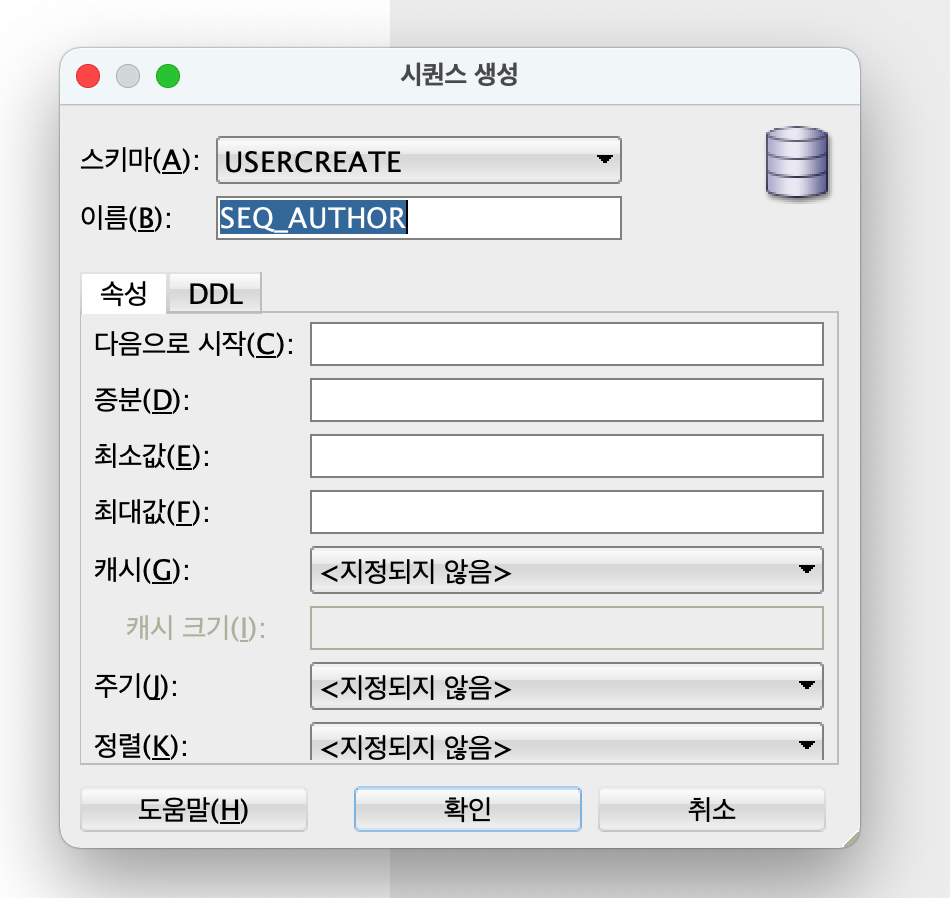
AUTHOR의에 행을 추가하기 위해 데이터 베이스의 워크시트를 열고 행을 추가한다.
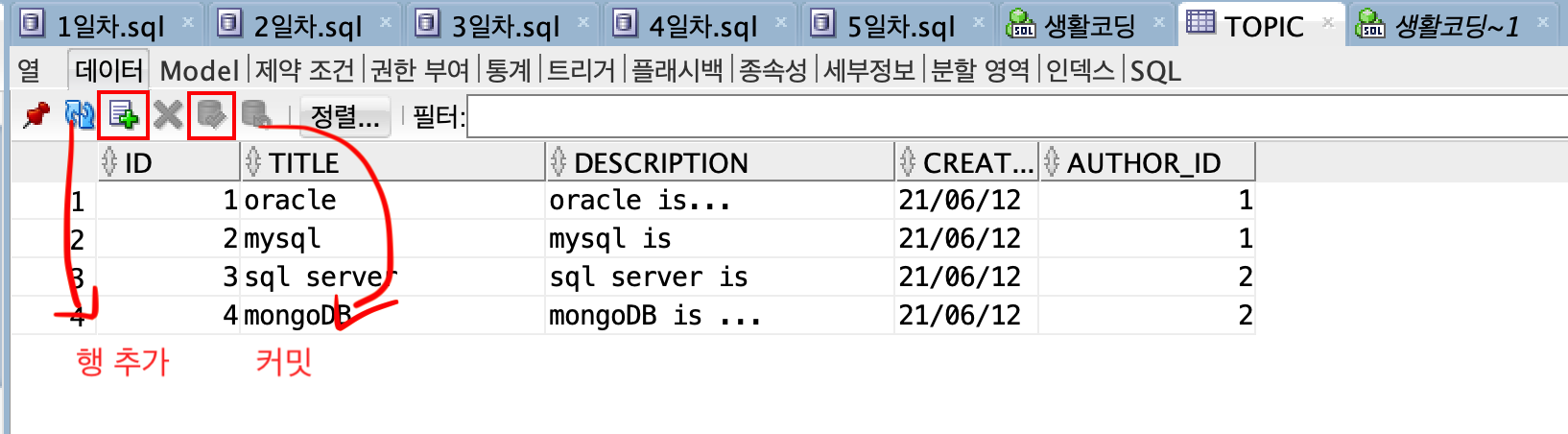
행 추가를 테이블의 데이터 탭에서도 할 수 있는데 추가 후 커밋을 꼭 해줘야한다.
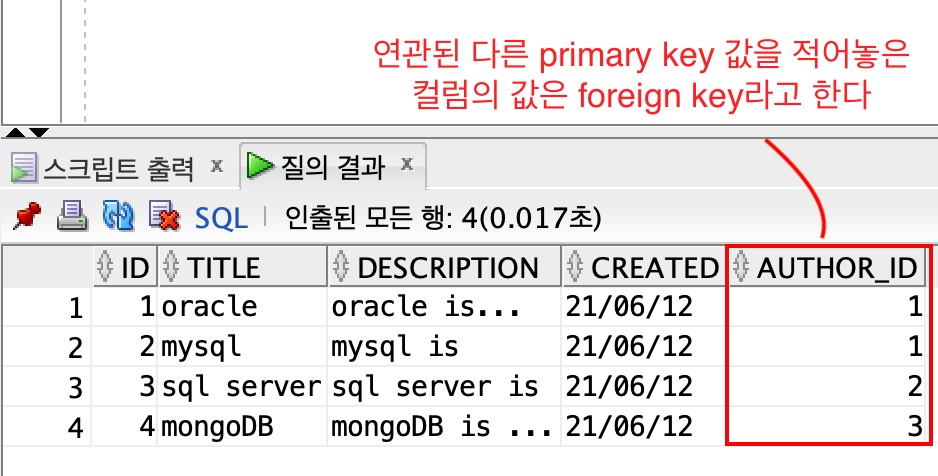
FOREIGN KEY
author 테이블의 id는 PRIMARY KEY로 지정이 되어있고,
topic 테이블의 author_id는 author 테이블의 id와 연관되어 있다.
이런 컬럼의 값을 FOREIGN KEY라고 한다.
JOIN문을 이용한 명령
topic에서 topic의 author_id와 author의 id가 같은 행을 찾아 해당 행의 내용을 topic의 오른쪽에 붙여서 실행한다.
SELECT * FROM topic
LEFT JOIN author ON topic.author_id = author.id
;
id, title, name만 찾으려고 하였으나 column명을 모호하게 적어서 에러가 난다.
--id, title, name 찾아보기: column ambiguously defined 발생
SELECT id, title, name FROM topic
LEFT JOIN author ON topic.author_id = author.id
;id 앞에 테이블 명을 붙여서 더 명확하게 찾는다.
--id 앞에 테이블 명을 붙여 찾기
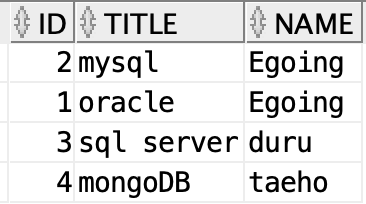
SELECT topic.id, title, name FROM topic
LEFT JOIN author ON topic.author_id = author.id
;
id 값에 이름(TOPIC_ID)을 붙여서 출력 결과에서 더 보기 좋게 찾는다.
--id 값에 이름(TOPIC_ID)을 붙여서 찾기
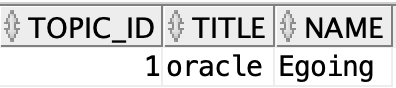
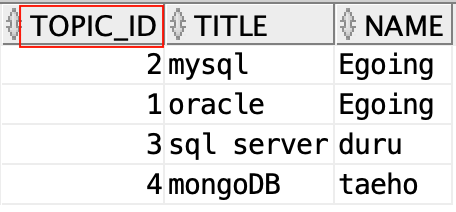
SELECT topic.id TOPIC_ID, title, name FROM topic
LEFT JOIN author ON topic.author_id = author.id
;
테이블에 이름을 붙여서 명령을 단축시켜서 찾는다.
--테이블에 이름을 붙여서(topic: T, author: A) 원하는 행(topic 테이블의 id가 1) 찾기
SELECT
T.id TOPIC_ID,
title,
name
FROM topic T
LEFT JOIN author A
on T.author_id = A.id
WHERE
T.id = 1
;