a. 문자열
문자열의 인덱스는 항상 0부터 시작한다. 문자열의 길이보다 더 긴 인덱스는 사용할 수 없으니 주의해야 한다.
 문자열은 길이를 가지는데, 문자열의 길이를 나타내는 함수를 len()함수라고 한다. 문자열 이외에도 매개 변수를 전달하면 길이를 계산해서 값을 반환한다.
문자열은 길이를 가지는데, 문자열의 길이를 나타내는 함수를 len()함수라고 한다. 문자열 이외에도 매개 변수를 전달하면 길이를 계산해서 값을 반환한다.
문자열을 읽고 필요한 데이터를 얻는 탐색 작업을 통해 반복문을 만들 수 있다.  반복 변수를 0으로 초기화한 후 반복 변수의 값을 1씩 증가시키는 방법을 사용한다면, 반복 변수가 원하는 문자열의 길이보다 작은 동안 코드를 반복시킬 수 있다.
반복 변수를 0으로 초기화한 후 반복 변수의 값을 1씩 증가시키는 방법을 사용한다면, 반복 변수가 원하는 문자열의 길이보다 작은 동안 코드를 반복시킬 수 있다.  같은 방식으로 for문을 사용하여 반복문을 만들 수도 있다. 문자열의 각 문자를 순서대로 확인하기 위해 반복문을 사용한다면, while문 대신 for문을 사용하는 것이 더욱 효과적이다. 코드의 길이도 줄일 수 있고, 반복 변수를 설정하지 않아도 되기 때문이다.
같은 방식으로 for문을 사용하여 반복문을 만들 수도 있다. 문자열의 각 문자를 순서대로 확인하기 위해 반복문을 사용한다면, while문 대신 for문을 사용하는 것이 더욱 효과적이다. 코드의 길이도 줄일 수 있고, 반복 변수를 설정하지 않아도 되기 때문이다.
 반복문을 활용한다면 가장 큰 문자를 찾거나, 가장 작은 문자를 찾거나, 문자가 존재하는지 탐색하거나, 특정 문자의 개수를 세는 등의 활동을 할 수 있다.
반복문을 활용한다면 가장 큰 문자를 찾거나, 가장 작은 문자를 찾거나, 문자가 존재하는지 탐색하거나, 특정 문자의 개수를 세는 등의 활동을 할 수 있다.
b. 문자열을 다루는 다양한 방법들
 슬라이싱이란, 문자의 조각을 가져오는 것이다. s[0:4](s 하위 0에서 4)는 좌표 0에서부터 시작해서 따라 올라가며 값을 읽고, 4가 되기 전인 3까지 값을 읽는다. 문자열의 길이보다 더 긴 인덱스를 사용해도 오류가 나지 않으며, 문자열의 마지막까지를 반환한다.
슬라이싱이란, 문자의 조각을 가져오는 것이다. s[0:4](s 하위 0에서 4)는 좌표 0에서부터 시작해서 따라 올라가며 값을 읽고, 4가 되기 전인 3까지 값을 읽는다. 문자열의 길이보다 더 긴 인덱스를 사용해도 오류가 나지 않으며, 문자열의 마지막까지를 반환한다. 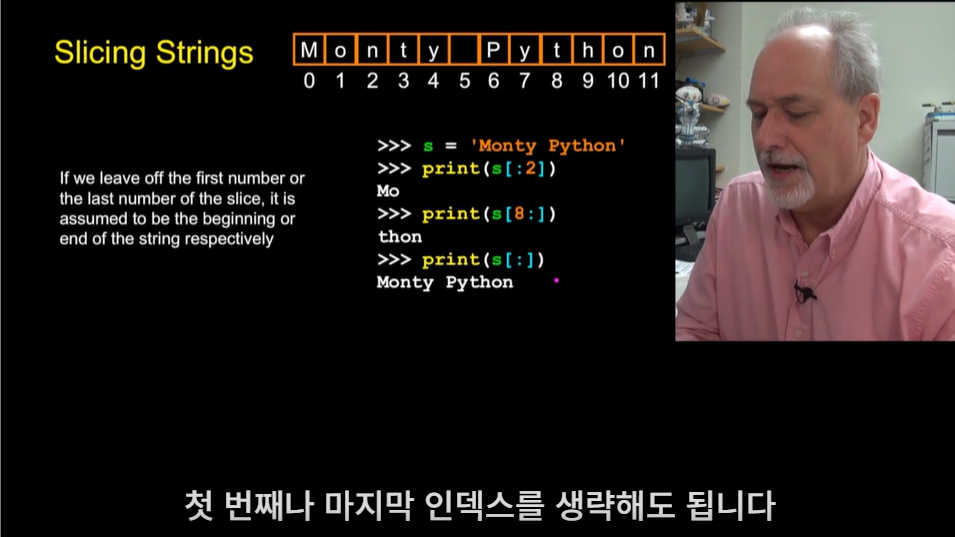 첫 번째나 마지막 인덱스를 생략해도 오류가 나지 않는다. 첫 번째 인덱스를 생략하면 문자열의 시작부터 실행되고, 마지막 인덱스를 생략하면 문자열의 마지막까지 실행된다. 전체 문자열을 반환하려면 [:]처럼 모든 인덱스를 생략하면 된다.
첫 번째나 마지막 인덱스를 생략해도 오류가 나지 않는다. 첫 번째 인덱스를 생략하면 문자열의 시작부터 실행되고, 마지막 인덱스를 생략하면 문자열의 마지막까지 실행된다. 전체 문자열을 반환하려면 [:]처럼 모든 인덱스를 생략하면 된다.
 +를 사용해서 문자열을 합칠 수도 있는데, print(x, y)의 경우 쉼표가 공백으로 변환되지만, +의 경우 공백이 생기지 않으니 공백 문자열을 별도로 합쳐야 하는 것에 주의해야 한다.
+를 사용해서 문자열을 합칠 수도 있는데, print(x, y)의 경우 쉼표가 공백으로 변환되지만, +의 경우 공백이 생기지 않으니 공백 문자열을 별도로 합쳐야 하는 것에 주의해야 한다.
in은 논리 연산자의 기호로도 사용될 수 있다. 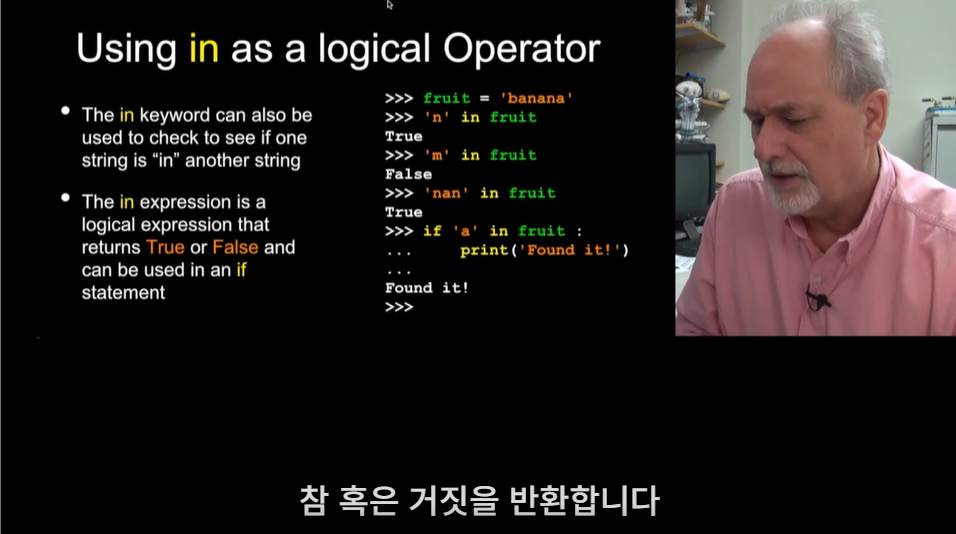 'n' in fruit 은 fruit 안에 n이 포함되어 있는지 파악하는 질문이고, 이에 대한 값은 참으로 나오게 된다.
'n' in fruit 은 fruit 안에 n이 포함되어 있는지 파악하는 질문이고, 이에 대한 값은 참으로 나오게 된다.
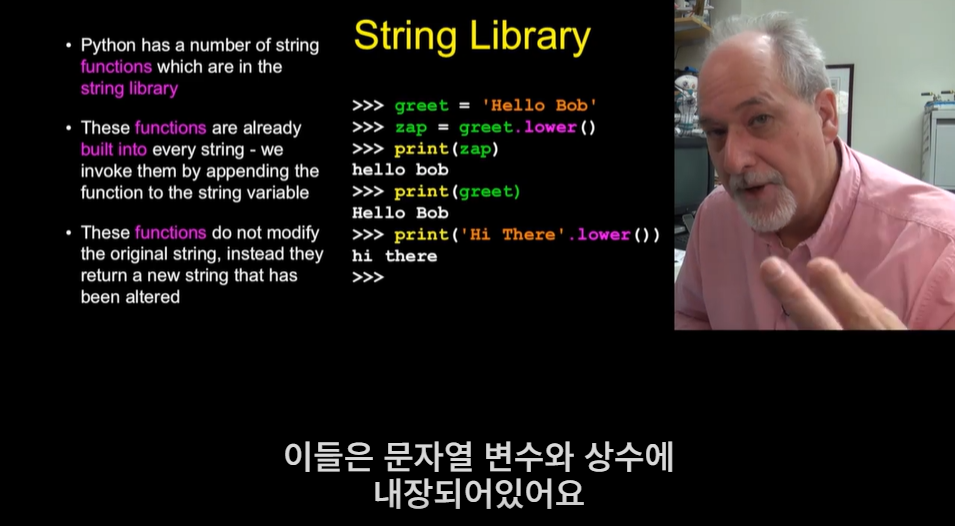 문자열은 객체이기 때문에 메소드를 가지는데, 메소드는 특수한 형태의 함수 호출(객체 지향 함수)이다. 함수에 매개 변수를 전달하는 대신, 객체에 온점과 함수 이름을 적는 것으로 함수 호출을 일으킬 수 있다.
문자열은 객체이기 때문에 메소드를 가지는데, 메소드는 특수한 형태의 함수 호출(객체 지향 함수)이다. 함수에 매개 변수를 전달하는 대신, 객체에 온점과 함수 이름을 적는 것으로 함수 호출을 일으킬 수 있다. 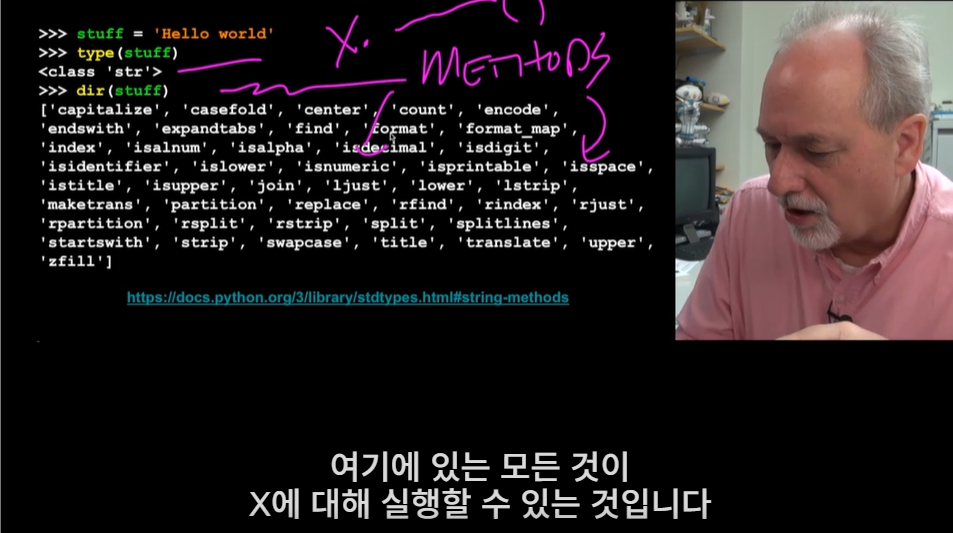 find 메소드는 해당 문자열을 탐색하고 첫 번째로 나타나는 위치를 찾아서 반환하고, 해당 문자열이 없으면 -1을 반환한다. find(' ', atpos) 라고 사용한다면, atpos의 위치 이후로 나오는 첫 번째 공백의 위치를 반환한다. 문자열에 upper 메소드와 lower 메소드를 사용하면 해당 문자열의 대문자, 소문자 버전을 알 수 있다. replace 메소드는 특정 문자열을 원하는 문자열로 바꿔주는 기능을 한다. lstrip 메소드는 문자열 시작에 있는 공백, rstrip 메소드는 문자열 마지막의 공백, strip 메소드는 양쪽 모두의 공백을 없앤다. startswith 메소드는 특정 문자열로 시작하는지 검사해서 참 또는 거짓의 값을 반환한다.
find 메소드는 해당 문자열을 탐색하고 첫 번째로 나타나는 위치를 찾아서 반환하고, 해당 문자열이 없으면 -1을 반환한다. find(' ', atpos) 라고 사용한다면, atpos의 위치 이후로 나오는 첫 번째 공백의 위치를 반환한다. 문자열에 upper 메소드와 lower 메소드를 사용하면 해당 문자열의 대문자, 소문자 버전을 알 수 있다. replace 메소드는 특정 문자열을 원하는 문자열로 바꿔주는 기능을 한다. lstrip 메소드는 문자열 시작에 있는 공백, rstrip 메소드는 문자열 마지막의 공백, strip 메소드는 양쪽 모두의 공백을 없앤다. startswith 메소드는 특정 문자열로 시작하는지 검사해서 참 또는 거짓의 값을 반환한다.
주의할 점은, 전부 원본 문자열은 변환시키지 않는다.
실습: 문자열 파싱
제시된 문자열에서 원하는 문자열만 출력하는 코드를 작성하였다. 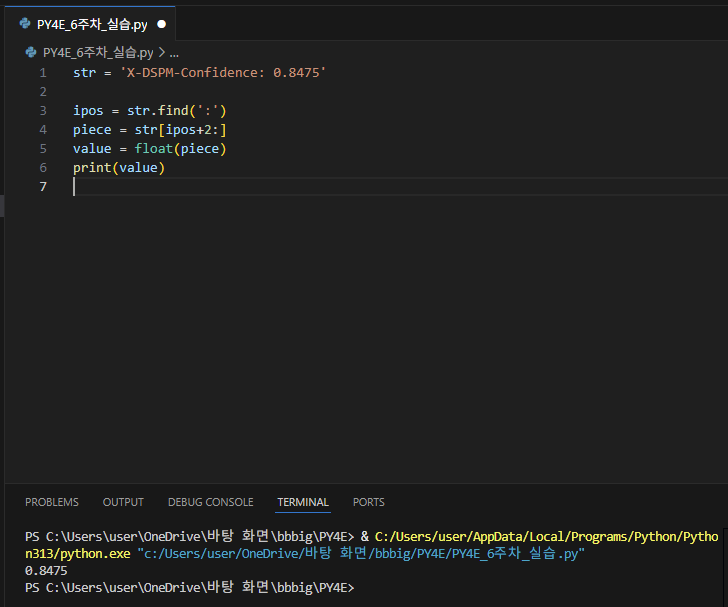 find 메소드, 슬라이싱, float()를 활용하여 실수 부분만 출력하였다.
find 메소드, 슬라이싱, float()를 활용하여 실수 부분만 출력하였다.
Quiz 6
문자열에 대한 퀴즈를 풀었다. 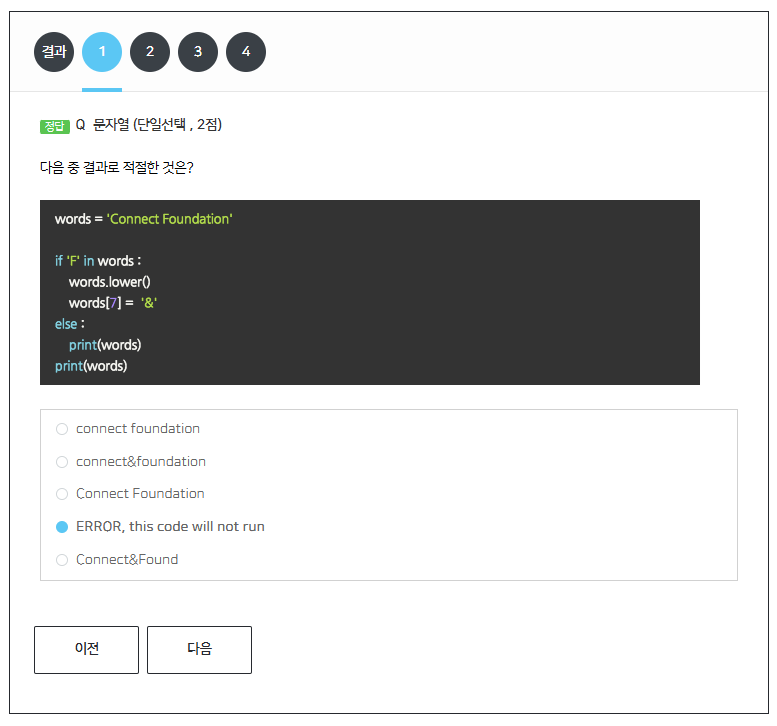 문제 1번을 첫 번째 시도에 맞추지 못했다... words.lower()의 반환값을 받는 변수가 존재하지 않아서 오류가 나는 것을 파악하지 못하였다. 코드를 더 꼼꼼히 보는 습관을 길러야 할 것 같다.
문제 1번을 첫 번째 시도에 맞추지 못했다... words.lower()의 반환값을 받는 변수가 존재하지 않아서 오류가 나는 것을 파악하지 못하였다. 코드를 더 꼼꼼히 보는 습관을 길러야 할 것 같다.