a. 딕셔너리 개념 및 특징
파이썬 딕셔너리란, 컬렉션(변수가 여러 개의 정보를 저장하는 것)의 종류 중 하나이다. 리스트는 요소들에 크기와 순서가 존재하지만, 딕셔너리는 순서가 존재하지 않고 키가 존재한다는 차이점이 있다. 키와 값 사이에 연결 관계가 존재한다는 점에서 딕셔너리는 연관 배열이라고도 불린다.
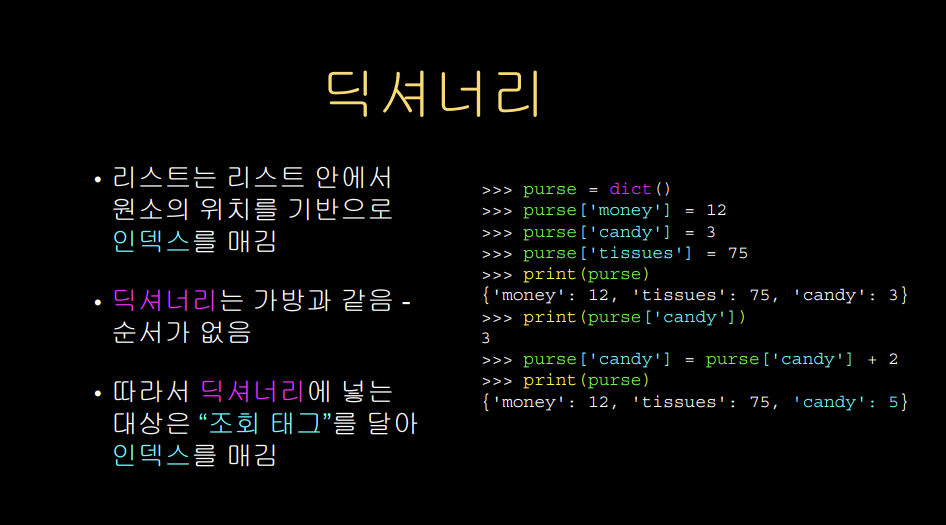 purse = dict() 라는 코드는 purse라는 이름의 변수에 빈 딕셔너리를 생성하는 코드이다. 이후 purse['money'] = 12 라는 코드를 입력하게 되면, 라벨(키값)이 money인 12(값)가 딕셔너리 안에 추가된다. purse['money']를 프린트하면 money의 값인 12가 출력되고, purse['money']+2를 다시 purse['money']에 대입하면 14로 값이 수정된다.
purse = dict() 라는 코드는 purse라는 이름의 변수에 빈 딕셔너리를 생성하는 코드이다. 이후 purse['money'] = 12 라는 코드를 입력하게 되면, 라벨(키값)이 money인 12(값)가 딕셔너리 안에 추가된다. purse['money']를 프린트하면 money의 값인 12가 출력되고, purse['money']+2를 다시 purse['money']에 대입하면 14로 값이 수정된다.
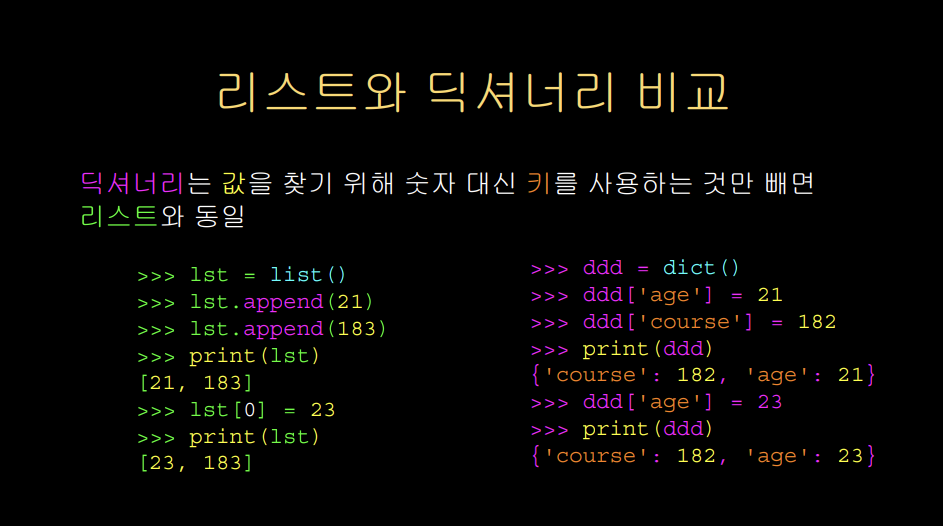 리스트와 딕셔너리는 인덱싱 메커니즘을 제외하고 거의 동일한 일을 수행한다. 끝부분에 새로운 값을 추가하고, 원하는 위치의 값을 수정할 수도 있다. 리스트에서 키는 항상 위치이지만, 딕셔너리에서 키는 문자열(혹은 다른 타입)이라는 것이 차이점이다.
리스트와 딕셔너리는 인덱싱 메커니즘을 제외하고 거의 동일한 일을 수행한다. 끝부분에 새로운 값을 추가하고, 원하는 위치의 값을 수정할 수도 있다. 리스트에서 키는 항상 위치이지만, 딕셔너리에서 키는 문자열(혹은 다른 타입)이라는 것이 차이점이다.
딕셔너리 표현법은 print 구문과 같은 문법을 사용한다. 중괄호로 시작해서 중괄호로 끝나며, 그 안에 연속해서 키, 콜론, 값이 들어있다.
b. 딕셔너리를 활용한 데이터 빈도수 측정
딕셔너리는 가장 일반적으로 히스토그램을 만드는 데 사용된다. 히스토그램은 빈도수를 세는 것으로, 각각의 원소가 얼마나 있는지를 파악하는 데 용이하다.
딕셔너리에 존재하지 않는 키는 찾을 수 없다. 이때, in 연산자를 사용하면 키가 존재하는지 검사하여 그 결과(True/False)를 반환할 수 있다. 이러한 사실과, 이름이 키이고 값이 1인 딕셔너리를 활용하면(이름이 호명될 때마다 값에 1을 추가), 각각의 이름이 호명된 횟수를 히스토그램으로 나타낼 수 있다. 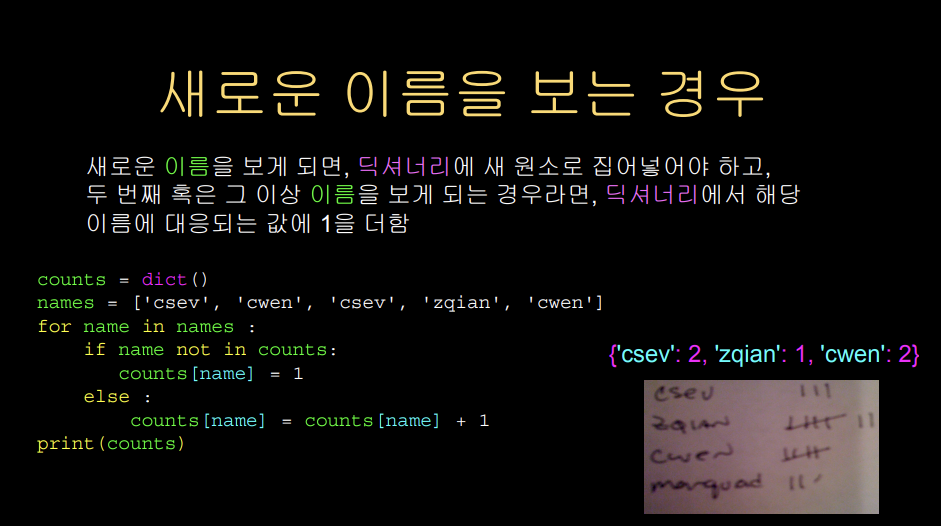
키가 딕셔너리에 있는지 없는지 검사하는 것은 get이라는 메서드를 활용할 수 있다. counts라는 이름의 딕셔너리에 counts.get(name, 0) 이라는 코드를 사용하면, 딕셔너리 안에 name이라는 키가 존재하면 키의 값을 반환하고 아니라면 기본값인 0을 반환한다. get 메서드를 활용하면 히스토그램을 만드는 코드를 짧고 간단하게 새로 만들 수도 있다.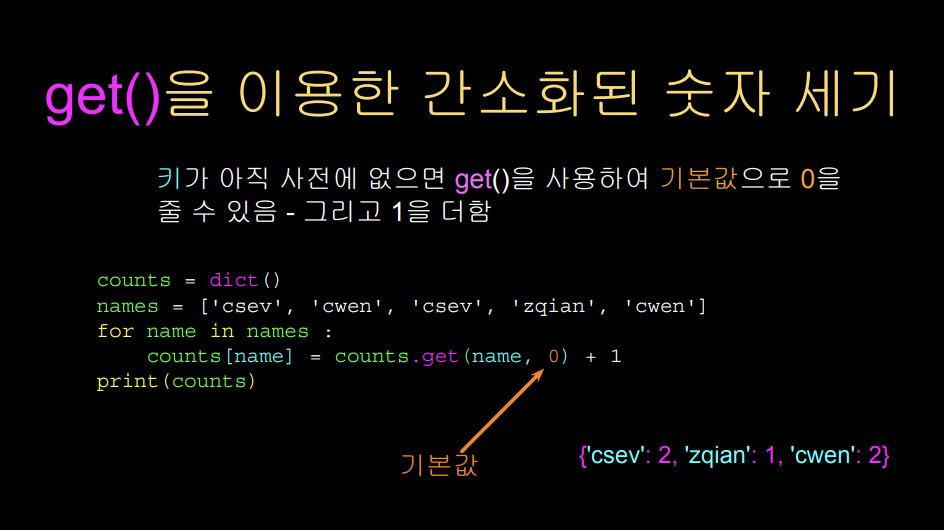
c. 딕셔너리 활용하기
counts = dict()
line = input('Enter a line of text: ')
words = line.split()
print('Words: ', words)
for word in words:
counts[word] = counts.get(word, 0) + 1
print('Counts', counts)이 코드를 사용하면 문자열에 있는 단어들이 총 몇 번 등장하는지에 대한 히스토그램이 출력된다. split을 사용해서 공백을 기준으로 문자열을 나누고, get을 사용해서 단어들의 빈도수를 구한다.
counts = { 'chuck' : 1 , 'fred' : 42, 'jan': 100}
for key in counts:
print(key, counts[key])이 코드는 반복문(for문)을 통해 딕셔너리의 모든 원소를 돌며 키와 값을 출력한다. 딕셔너리에 루프를 적용하는 방법으로, 딕셔너리를 만들 때 루프를 이용하는 것이 아니라 딕셔너리에 저장된 데이터를 다룰 때 루프를 사용하는 코드이다.
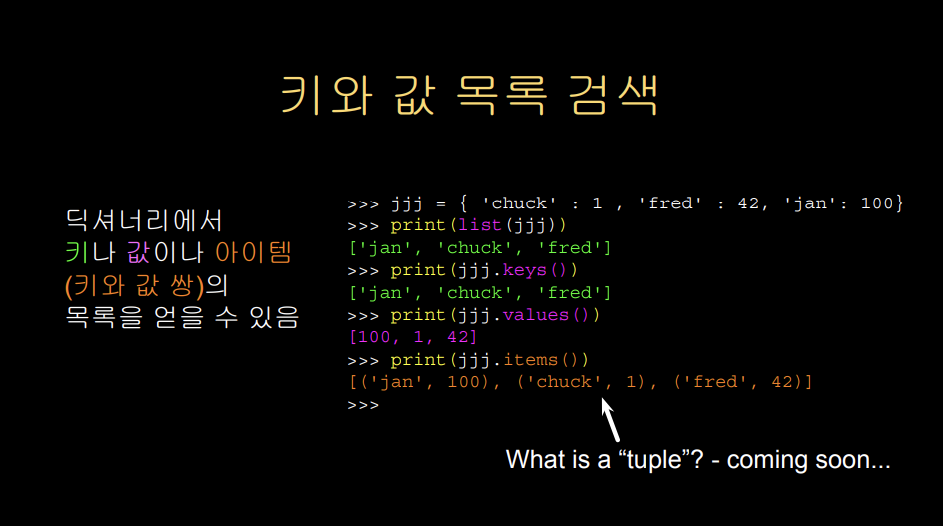 딕셔너리에 keys() 메서드를 사용하면 딕셔너리의 키만 리스트로 얻을 수 있고, values() 메서드를 사용하면 딕셔너리의 값만 리스트로 만들 수도 있다. 두 메서드의 경우 어떤 원소가 먼저 리스트에 들어갈지 순서는 예측할 수 없지만, 무조건 키와 값이 대응되는 같은 순서로 리스트가 만들어진다. items() 메서드를 사용하면 딕셔너리의 원소가 튜플 형태(키, 값의 원소 포함)인 리스트가 만들어진다.
딕셔너리에 keys() 메서드를 사용하면 딕셔너리의 키만 리스트로 얻을 수 있고, values() 메서드를 사용하면 딕셔너리의 값만 리스트로 만들 수도 있다. 두 메서드의 경우 어떤 원소가 먼저 리스트에 들어갈지 순서는 예측할 수 없지만, 무조건 키와 값이 대응되는 같은 순서로 리스트가 만들어진다. items() 메서드를 사용하면 딕셔너리의 원소가 튜플 형태(키, 값의 원소 포함)인 리스트가 만들어진다.
items 메서드를 사용하면 키와 값이 하나의 쌍으로 원소가 된 리스트가 만들어지기 때문에, 이를 반복문에서 사용하려면 두 개의 반복 변수가 필요하다.
jjj = { 'chuck' : 1 , 'fred' : 42, 'jan': 100}
for aaa,bbb in jjj.items() :
print(aaa, bbb)name = input('Enter file:')
handle = open(name)
counts = dict()
for line in handle:
words = line.split()
for word in words:
counts[word] = counts.get(word,0) + 1
bigcount = None
bigword = None
for word,count in counts.items():
if bigcount is None or count > bigcount:
bigword = word
bigcount = count
print(bigword, bigcount)이 코드는 두 개의 반복문을 사용하여 입력되는 파일에서 가장 많이 등장하는 단어와 그 횟수를 출력한다. 딕셔너리의 키는 word에, 키의 빈도수는 count에 저장하고, 값이 가장 큰 단어를 bigword에, 그 단어의 빈도수를 bigcount에 저장하는 방식으로 가장 많이 나온 단어와 그 빈도수를 출력한다.
딕셔너리는 가장 강한 컬렉션으로, 하나 이상의 대상을 자신의 내부에 포함하여 다룰 수 있게 한다.
실습: 딕셔너리를 활용한 데이터 빈도수 측정
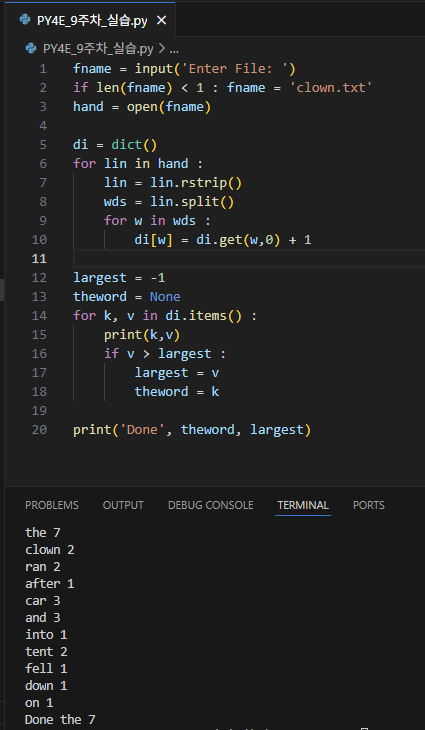 get 메서드를 활용해서 각 단어의 빈도수를 딕셔너리에 저장하고, 빈도수가 가장 큰 단어를 theword, 그 빈도수를 largest에 저장하여 가장 많이 등장하는 단어를 출력하는 코드이다. the가 7번으로 가장 많이 등장한다.
get 메서드를 활용해서 각 단어의 빈도수를 딕셔너리에 저장하고, 빈도수가 가장 큰 단어를 theword, 그 빈도수를 largest에 저장하여 가장 많이 등장하는 단어를 출력하는 코드이다. the가 7번으로 가장 많이 등장한다.
Quiz 9
 딕셔너리의 데이터형, 출력 결과, get에 대한 문제를 풀었다. 딕셔너리의 키와 값에 대한 개념을 복습해 볼 수 있었다.
딕셔너리의 데이터형, 출력 결과, get에 대한 문제를 풀었다. 딕셔너리의 키와 값에 대한 개념을 복습해 볼 수 있었다.
