
👨👩👧👦그룹화
CREATE TABLE students (
s_id INT PRIMARY KEY AUTO_INCREMENT,
s_name VARCHAR(10) NOT NULL,
s_age INT NOT NULL,
s_gender CHAR(1) NOT NULL,
p_id INT
);
CREATE TABLE professors(
p_id INT PRIMARY KEY AUTO_INCREMENT,
p_name VARCHAR(10) NOT NULL,
p_age INT
);
INSERT INTO professors (p_name, p_age)
VALUES
('hulk', 45),
('ironman', 41),
('tor', 1500),
('dr_st', 50);
INSERT INTO students (s_name, s_age, s_gender, p_id)
VALUES
('smith', 20, 'M', 1),
('jason', 28, 'M', 3),
('peter', 22, 'M', 1),
('jane', 20, 'F', 3),
('lily', 18, 'F', 2),
('ken', 31, 'M', 1),
('july', 22, 'F', 2);
-- 성별 학생수를 구하라.
SELECT s_gender, COUNT(*) FROM students GROUP BY s_gender;
-- 성별 학생수를 구하라.(단, 구성원 수가 4명이상인 그룹만 표기한다.)
SELECT s_gender, s_name, COUNT(*) FROM students GROUP BY s_gender HAVING COUNT(*) >= 4;→ GROUP BY : 복수의 의미를 가진다.
하나의 값을 가지는(= 같은 값을 가지는) 것들을 묶으라는 의미를 가진다.
즉, 의미를 가질려면 공통적인 값을 가져야 한다.
집계함수를 쓸 수 없다.
GROUP BY의 레코드 수는 그룹화 시키는 열의 값 종류 수 와 같다.
<GROUP BY에 조건 달기>
→ WHERE 은 레코드별(레코드 하나씩) 검사하기에 여러줄을 검사할 수 없다.
그러므로 WHERE 보다 HAVING을 이용해야 한다.
HAVING은 그룹 자체를 검사한다.
HAVING은 개별로 다른 값을 가지는 것은 사용할 수 없다.
집계함수를 쓸 때, HAVING을 사용하면 된다.
⇒ 그러면 아예 WHERE을 사용할 수 없는가?
: 그룹화 하기 전에 조건에 맞게 거를 수 있다.
--담당교수 별 여학생 수를 구하라.
-- HAVING 안되는 이유 : 그룹별로 통일된 값을 주지 못해서
SELECT p_id, COUNT(*) FROM students GROUP BY p_id HAVING s_gender = 'F';
SELECT p_id, COUNT(*) FROM students WHERE s_gender = 'F' GROUP BY p_id;→ 위 쿼리문을 보면 그룹화 시키고 HAVING을 쓰는 거는 적절하지 않다.
HAVING은 그룹 자체를 검사하는데 그룹에게 성별을 묻는 것이 이상하기 때문이다.
(그룹 자체가 여자인지 남자인지 구별할 수 없으므로)
그러므로 WHERE로 먼저 거르고 그룹화 시켜야한다.
연산 순서
: FROM(어떤 테이블에서 가져오는 지 확인) → WHERE(조건에 맞게 거르기) → GROUP BY(그룹화 하기) → HAVING → SELECT
⭐️중복 제거하기
CREATE TABLE sales_record (
num INT PRIMARY KEY AUTO_INCREMENT,
s_name CHAR(10) NOT NULL,
sales INT NOT NULL,
today CHAR(10) NOT NULL
);
INSERT INTO sales_record (s_name, sales, today)
VALUES
('IU', 2000, '2023-05-01'),
('ailee', 4000, '2023-05-01'),
('yoona', 1000, '2023-05-01'),
('IU', 1500, '2023-04-31'),
('ailee', 300, '2023-04-31'),
('yoona', 4000, '2023-04-31'),
('IU', 5000, '2023-04-30'),
('yoona', 2500, '2023-04-30'),
('ailee', 2500, '2023-04-29'),
('ailee', 4000, '2023-04-28'),
('yoona', 3000, '2023-04-28'),
('IU', 9000, '2023-04-27'),
('ailee', 7000, '2023-04-27'),
('IU', 6000, '2023-04-26'),
('ailee', 2000, '2023-04-26'),
('yoona', 4000, '2023-04-26');
--모든 판매일을 구하라.
SELECT today FROM sales_record;
SELECT DISTINCT today FROM sales_record;→ DISTINCT : 중복을 제거해준다.
⭐️JOIN
join : 물리적으로 분리된 테이블을 논리적으로 하나의 테이블로 합치는 것을 말한다.(즉, 한 테이블로 만드는 것)
💜JOIN의 종류
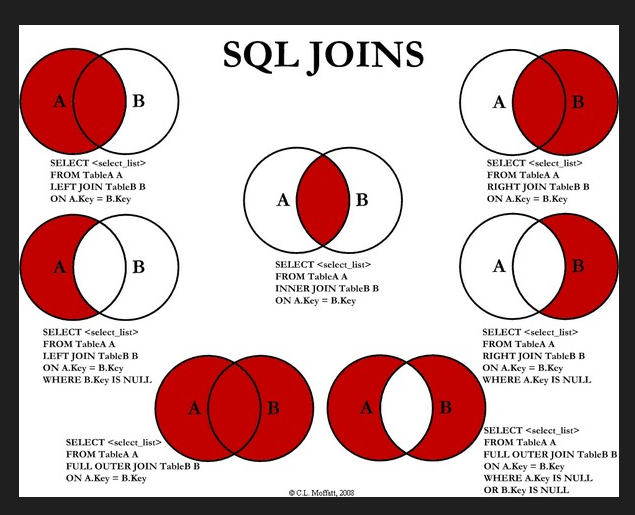
1) inner - join
2) outer - join
3) self - join
4) cross - join
💙inner - join
→ join의 기본, 표준이다.
→ 결합 조건이 맞는 애들만 대상으로 하여 연산한다.
쉽게 말해 교집합을 의미한다.
(연관성이 있는 애들(연관있는 레코드만)을 join한다.)
SELECT p_name FROM students, professors WHERE students.p_id = professors.p_id AND s_name = 'jason';
-- 표준 = inner join(위와 같은 표현)
SELECT p_name FROM students INNER JOIN professors ON students.p_id = professors.p_id WHERE s_name = 'jason';
-- inner join의 축약형(연결되는 열 이름이 같을때)
SELECT p_name FROM students NATURAL JOIN professors WHERE s_name = 'jason';→ 위의 쿼리문을 참고하면 된다.
→ NATURAL JOIN : inner join의 축약형으로 연결되는 열 이름이 같을 때 사용한다.
(값과는 아무 상관 없다. 외래키로 사용되는 이름과 그 외래키를 주key로 사용하는 테이블에서의 이름과 같아야 한다.)
다른 점은 실행해보면 아는데, INNER JOIN은 같은 열이 중복되서 나오고 NATURAL JOIN은 중복된 열이 없다.
💙outer - join
→ 결합조건에 포함되지 않는 애들까지 대상으로 한다.
→ left outer join, right outer join, full outer join 을 가진다.
-- 담당학생이 아무도 없는 교수이름은?
SELECT * FROM students RIGHT OUTER JOIN professors ON students.p_id = professors.p_id WHERE s_id IS NULL;
SELECT * FROM professors LEFT OUTER JOIN students ON students.p_id = professors.p_id WHERE s_id IS NULL;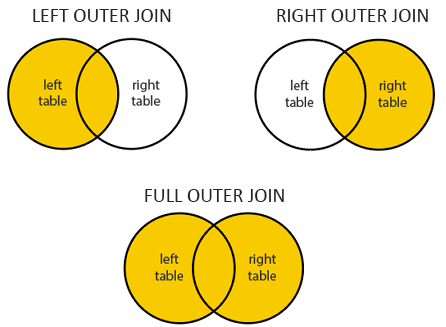
→ 위의 그림과 쿼리문을 참고하면 된다.
예를 들어 위에서 담당하는 학생이 한명도 없는 교수는 누구인가를 구할 때 사용한다.
→ left outer join과 right outer join 을 구별해서 쓸려면?
: NULL이 포함되어 있는 테이블이 어디 있는지를 먼저 확인하면 된다.
→ mysql에서는 full outer join을 지원하지 않는다.
→ A RIGHT OUTER JOIN B = B LEFT OUTER JOIN A
둘은 같은 말이다. 그리고 둘 다 기준은 B이다.
💙self - join
→ 물리적으로는 테이블 하나이지만 논리적으로 테이블을 2개로 보는것을 말한다.
CREATE TABLE emp(
e_id INT PRIMARY KEY AUTO_INCREMENT,
e_name VARCHAR(20) NOT NULL,
e_manager INT
);
INSERT INTO emp (e_name, e_manager)
VALUES
('a', 2),
('b', 3),
('c', 4),
('d', NULL);
SELECT * FROM emp;
-- 각 직원의 이름과 매니저 이름을 구하라.
SELECT e1.e_name emp_name, e2.e_name manager_name
FROM emp e1 INNER JOIN emp e2 ON e1.e_manager = e2.e_id;
-- 사장이름 구하라. 사장은 매니저가 없다.
SELECT e1.e_name emp_name
FROM emp e1 LEFT OUTER JOIN emp e2
ON e1.e_manager = e2.e_id WHERE e2.e_id IS NULL;
SELECT e_name FROM emp WHERE e_manager IS NULL;
-- 막내는 누구인가? 막내는 매니저는 있으나 본인은 매니저가 아니다.
SELECT e2.e_name FROM emp e1 RIGHT OUTER JOIN emp e2
ON e1.e_manager = e2.e_id WHERE e1.e_id IS NULL;→ 위 코드를 참고하면 된다.
💙cross - join
→ 두 테이블을 하나로 만들어 주는 것으로, 모든 경우의 수를 보여준다.
모든 경우의 수를 보여주므로, 상당한 데이터 양을 가지며 실제로는 주로 성능 테스트를 할 때 사용한다.
SELECT * FROM students, professors;
SELECT * FROM students CROSS JOIN professors;