지금까지 고통받고 있는 EKS to Lambda 를 통해 알아낸 것들을 소개할 예정.
Connection 관리와 Batch, 등 기존 아키텍쳐를 이전하는 부분에 대한 것이 가장 어려웠는데 오늘은 Database Connection 관련된 이야기를 먼저 풀어볼 예정.
Lambda?
AWS 에서 제공하는 서버리스 컴퓨팅 서비스
로드벨런서, API Gateway, AWS SQS 등 에서 발생한 이벤트 에 의해서 인프라에 대한 어떤 것도 신경쓰지 않아도 미리 정의된 코드가 알아서 실행됨
API Gateway 에 있는 HTTP API 를 통해서 Lambda 를 호출
// 각각 API Gateway 의 이벤트가 발생하면, 이 handler 함수가 실행
// 비동기 함수는 이 안에만 넣을 수 있음
export const handler = async (event, context) => {
await initDatabase();
const response = await handlerFunction(event, context);
return response;
};왜 써요?
아래 네가지 정도의 장점을 가질 수 있어서 사용
- Scale-out 이 함수 단위로 실행됨
- CloudWatch 로 모든 로그가 쌓이기에 로깅, 모니터링 유용
- 운영체제 업데이트, Node 버전 업데이트 등 신경 써야 될 부분 사라짐
APP 이외의 다른 인프라를 신경쓸 필요가 없음
뭘 했어요?
[상황] K8S + Container 기반의 서비스 v1, v2 → Lambda Migration
[DB] Postgres, Redis, Elastic Search
트래픽이 적어져서, 성능이 낮은 저장소를 사용중 → RDS 최대 커넥션 300 개 가량
람다에서 RDBMS
- 상태를 유지하지 않음
- 이벤트가 발생하면 켜지고, 실행되고 나면 꺼짐
위 두가지 조건으로 인해 람다가 실행되기 이전 / 이후 상황을 컨트롤 할 수 없음
[상황 1]
- A-0 람다가 RDS 와 Connection 을 맺음
- A-0 는 실행 종료됨
- RDS 에서는 Connection 종료를
명시적으로확인받지 못함. (RDS 는 연결상태라 판단중) - A-1 람다가 새로 실행되며 RDS 와 Connection 을 맺음
- RDS 에서는 Connection 이 과도하게 많아지게됨
- RDS 에 연결할 수 없어, 람다에서 500 에러
[상황 2]
- A 람다가 과도하게 Invoke 됨
→ API Gateway 에 HTTP 호출이 일어나는 족족 Lambda 를 실행 - 과도하게 많은 Lambda 가 실행되는 족족 Connection 을 맺음
- RDS 의 Connection 제한까지 도달함
- RDS 에 연결할 수 없어, 람다에서 500 에러
원인
- 기존 Container 기반 프로젝트 처럼 Connection Pool 이 유지되지 않음
- API Gateway 에 Invoke 되는 순간마다 Lambda 를 실행함
→ 기존의 Reverse Proxy 는 커낵션을 맺고, 현재 실행되어 있는 컨테이너에 연결되며, 각 컨테이너도 Connection Pool 을 유지하기에 별 문제가 없었음. (가용 커넥션을 넘어서도, DB Connection 이 늘어나진 않았음)
해결
- Connection 관리
- Proxy 를 이용한 풀 관리
- API 호출 최적화
이 세가지를 적절히 시도해서 최선을 찾아야한다.
Connection 관리
1. handler 하나에 1 Connection
export const handler = async (event, context) => {
context.callbackWaitsForEmptyEventLoop = false;
// 명시적인 Connection 가져오기
const connection = await getConnection();
const response = await handlerFunction(event, context);
// 명시적인 Connection 끊기
await connection.close();
return response;
};문제 - 명시적으로 끊더라도 커넥션이 반환되지 않을수도 있으며, TCP 스펙상 Connection 이 끊기는건 Server-Client 각각에서 대기시간이 추가 발생 가능하다.
2. 전역적으로 Connection 관리
async function initDatabase() {
try {
getConnection();
} catch (err) {
await createConnection(connectionOptions);
}
}
export const handler = async (event, context) => {
await initDatabase();
/* ****** */
};Lambda 가 종료되어 메모리가 반환되기 이전까진 남아있음. 그 이후에는 다시 연결이 필요함. - Scale-out 이 일어나지 않는다면 Connection 이 더이상 늘어나지 않기에, 관리가 쉬워진다.
RDS Proxy
Connection Pool 은 Proxy 가 가지고 있고, Lambda 는 그 프록시를 통해 대신 Connection 을 사용함. 이건 Container 기반의 인프라에서도 사용하면 좋음.
테스트 결과
# 간단한 API 와 SELECT 구문을 이용한 테스트 / 2019 블로그 글 인용
## https://qiita.com/G-awa/items/b9138cc1c9e4867a905e
RDS Proxy 적용 전
$ artillery quick --count 300 -n 10 ...
Connection 개수: 18 -> 124
RDS Proxy 적용 후
$ artillery quick --count 300 -n 30 ...
Connection 개수: 18 -> 43
회사 코드로 스트레스 테스트 해봤을 때는 큰 차이가 안났음. 너무 급격한 Scale-out 에는 대응하기 힘든가봄.
API 호출 최적화 (당연한 말)
람다 자체가 동시에 적게 실행되고, Connection 이 빠르게 반환되도록 하는 것이 중요.
-
RDS 에서 호출되는 SQL 중 캐싱 가능한 부분은 캐싱을 통해 Connection 을 줄여야함.
-
실행이 빡센 쿼리들 최적화를 해야함.
-
가장 많은 트래픽을 가지는 프론트 페이지에서 호출되는 API 수를 줄이고 캐싱도 필요.
RDS 성능 개선 도우미
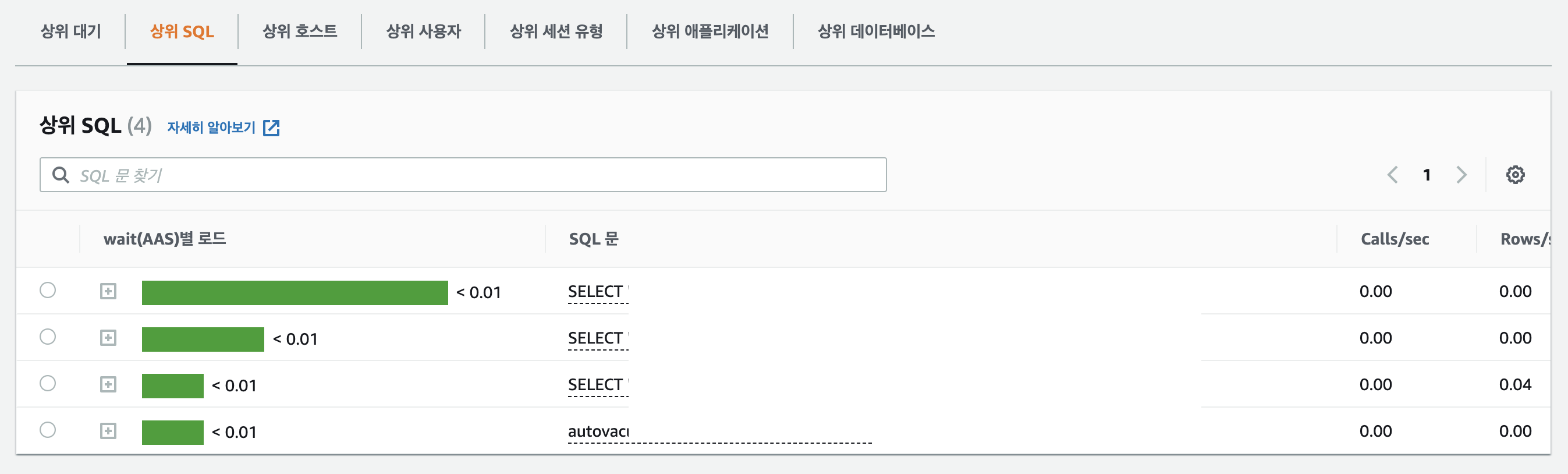
가장 많이 호출되는 SQL 구문, 실행 시간등 파악 가능해서, DB 성능 개선 순서를 파악가능
AWS X-ray
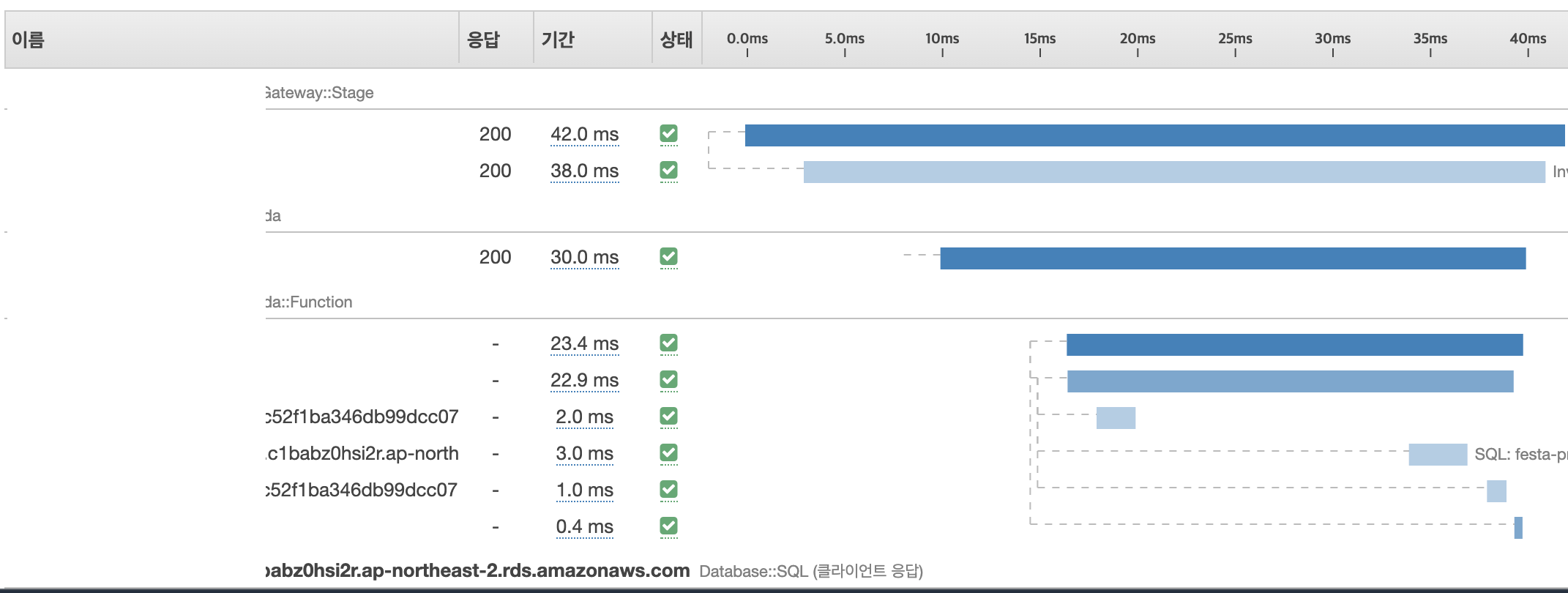
람다는 Low level 이 추상화 되어 있어, APP 에서 설정된 에러 외에는 파악이 어려움.
각 AWS 서비스별로 연결되어 DB, Redis 등의 데이터 저장소 호출시, 각 수행 시간 정보나 메타 정보를 기록해서 저장해줄 수 있는 도구.
이를 활용해서 각각의 성능 최적화를 시도할 수 있음.
결론
이 모든것을 다 하더라도, 동시에 빠르게 실행되는 API 을 제대로 감당하려면, 기존 아키텍쳐보다 훨씬 신경써야할 부분이 많음.
아키텍터는 MSA 패턴으로 짜는 것이 가장 이상적이라고 하나, 현실적으로는 불가능해서, APP 실행시 커넥션 자체를 줄이는 방향을 선택해야함.
가능하다면, Dynamo DB, AWS 오로라 등 Scale Out 이 가능한 Database 를 사용하는 것이 좋음. 또는 기본적으로 연결할 수 있는 커넥션 많은거? 하지만 Transaction 의 이점을 포기하기엔 잃을게 더 많은 것 같다.
