이 글은 만들면서 배우는 클린 아키텍처 라는 책을 읽고 작성한 글이에요. 이 책에서는 전통적인 자바 + 스프링을 기반으로 아키텍처를 설명해나가요.
Spring + Java는 잘 발달한 DI 컨테이너를 제공해주며 클래스와 인터페이스 기반의 코드를 쉽게 작성할 수도 있어 책에서 설명하는 내용을 쉽게 적용할 수 있지만 Nodejs 는 런타임 타입 추론 능력이 자바보다 떨어질 뿐만 아니라, 각각의 라이브러리 별로 공통된 형태의 인터페이스가 없어 클린 아키텍처를 구현하는데 조금 더 어려움이 있을 것 같아 보였어요.
저는 이 책에서 변경을 용이하게 하는 방식 에 가장 집중해봤어요. 또한 어떤 라이브러리를 사용해서 어떻게 구현을 해나가봤는지, 가장 중요하게 생각하는 부분이 어떤건지 실제 예제를 통해서 설명을 해보려고 해요.
이 아티클은 다음과 같은 순서로 설명을 해보려고 해요.
- 클린아키텍처란?
- 기본 틀 작성
- 유즈케이스와 도메인 작성
- 트랜잭션 다루기
1. 클린아키텍처란?
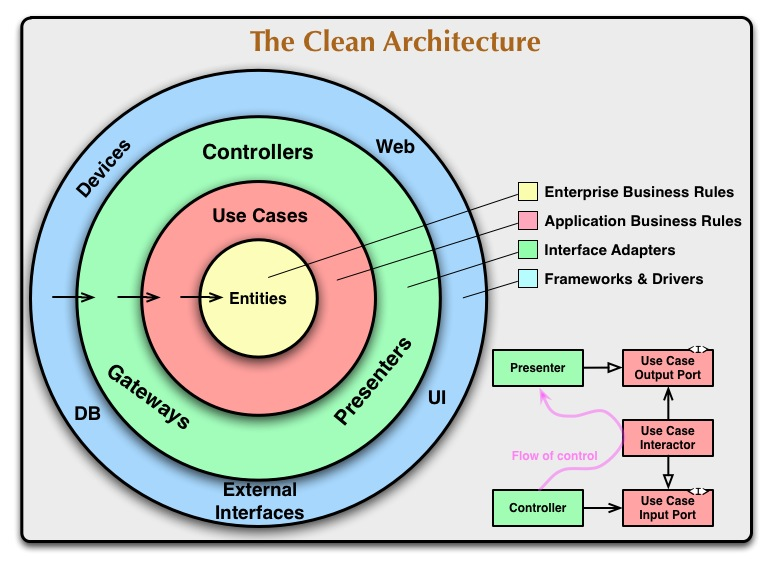
제가 프로젝트를 구성하며 가장 중요하다고 생각했던 그림이에요. 엔티티는 그 어떤 의존성을 가지지 않고 있으며, 외부 기술로 빠져 나갈수록 더 많은 의존성을 가지게 되는 그림이에요.
로버트 C. 마틴은 클린 아키텍처에서는 설계가 비즈니스 규칙의 테스트를 용이하게 하고, 비즈니스 규칙은 프레임워크, 데이터베이스, UI 기술, 그 밖의 외부 애플리케이션이나 인터페이스로 부터 독립적일 수 있다고 이야기했어요.
-> 이는 위 그림에서 도메인 코드가 바깥으로 향하는 어떠한 의존성도 없어야 하고, 의존성 역전을 활용하여 모든 의존성이 도메인을 향하도록 해야해요. 도메인은 다른 어떤 외부 의존성에 영향받지 않고, 독립적으로 구현되어있어야 하며, 데이터베이스나 UI 등 외부 기술들이 이 도메인을 활용하는 방향으로 구성이 되어있으면 된다고 이야기를 해요.
만약 ORM 을 사용한다고 가정을 해볼게요.
현 시점에서 가장 많이 사용하는 TypeORM 의 경우엔 TypeORM 에서 제공하는 Entity 클래스를 정의해서 이 클래스를 기준으로 데이터를 핸들링하고, Repository 를 이용해서 데이터를 DB 에 저장해요. 하지만 TypeORM 에서 직접 제공해주는 Repository 와 Entity 를 이용해서 도메인을 작성하게 되면 외부 의존성에 영향을 받고 독립적이지 못한 코드가 되어버려요. 따라서 도메인 계층과 데이터 영속 계층이 각각 다른 Entity 와 Repository 를 가지고, 데이터를 핸들링 할 수 있게 해야해요.
더 자세한 내용과 다양한 구현 방법은 책을 읽어보면 좋을 것 같아요!
2. 기본 틀 작성
설정한 제약사항
위에서 간단하게 설명한 바로, 가장 중요하게 생각하는 두 가지 원칙을 설정하고 기본 틀을 구성해보려고 해요.
-
비즈니스 로직은 외부 의존성에 영향을 받으면 안된다라는 원칙은 반드시 지켜야해요.위에서 언급한 클린아키텍처의 가장 중요한 부분이라고 생각해요.
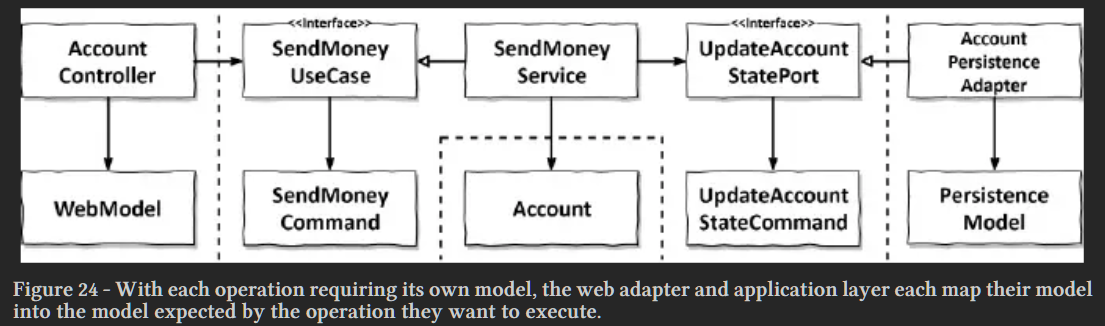
이를 위해서 첫번째로 각각의 계층에서 사용할 엔티티를 나눠 정의하는
완전 맵핑 전략을 사용 해볼 예정이에요. 도메인 계층이 외부로 나갈때는 읽기 전용 모델로 변환해서 핸들링 하고, 도메인 계층을 수정해야 할 때는 커맨드 모델로 데이터를 핸들링 해요.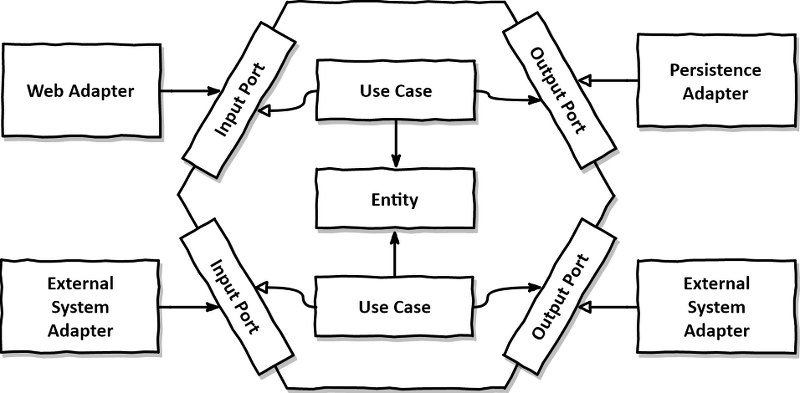
두번째로 모든 계층을 오고 갈 땐 (Controller / View 부분 제외) 모두 인터페이스를 통해서 데이터를 핸들링 해요. 육각형 아키텍처에서 port 부분을 심플하게 가져가는 방향으로 바라봐도 좋아요. 이처럼 인터페이스로 각각의 계층을 묶어놓으면, 각각의 계층의 변경에 쉽게 대처할 수 있게돼요.
-
Nodejs 에서 지원하는 기술은 도메인 계층에서도 사용할 수 있어요.
AsyncLocalStorage 등, 노드에서 직접 제공해주는 기능은 도메인에 침투해서 빠르게 비즈니스 로직을 작성할 수 있도록 편의를 위해 선택해봤어요. 프레임워크나 DB 데이터, 라이브러리 등은 충분히 바뀔 수 있지만, 언어레벨에서 변경될 여지는 가장 낮아서 이런 제약정도는 괜찮을 것 같아요. (물론 file I/O 나 위에서 말한 AsyncLocalStorage 는 추후 로직 변경이나 더 나은 성능의 라이브러리 사용을 위해서라도 인터페이스로 묶어두면 좋아요)
-
배포 환경이 변하더라도 빠르게 대응 가능해야해요.
Nodejs 는 스크립트 언어답게 Docker 환경, Lambda 등 다양한 환경에 배포할 수 있고, 서버 전략에 따라 많이 달라질 수 있어요. 이를 쉽게 대응할 수 있는 구조를 도입해보려고 했어요.
프로젝트 구조
이 제약사항을 가지고 만들어낸 디렉터리 구성은 다음과 같아요. 최대한 계층별로 역할이 잘 드러나도록 디렉터리를 구성해봤어요.
domain // 도메인 계층을 넣어둬요.
|- application // 비즈니스 로직을 넣어둬요.
| |- configuration.ts
| |- ticket
| |- usecase // UseCase 는 서비스 계층을 접근하기 위한 인터페이스와 읽기 모델, 커맨드 모델을 넣어둬요.
| | |- TicketFinder.ts
| | |- TicketCreateProcessor.ts
| |- TicketService.ts // UseCase 를 구현한 서비스에요.
|- domain // 가장 기본이 되는 도메인 엔티티에요.
| |- ticket
| |- Ticket.ts
| |- TicketRepository.ts
|- data // DB, ES 등의 영속계층에 대한 Repository 를 직접 구현한 구현모델이 있는 곳이에요.
|- configuration.ts
|- ticket
|- TicketEntity.ts
|- KnexTicketRepository.ts
handler // 서비스를 넣어둬요 (lambda 를 사용해보려고 handler 라는 이름을 사용했어요.)
|- api
| |- TicketController.ts
| |- index.ts
|- worker
|- index.ts-
각각 서버의 용도를 나누기 위해, handler 디렉터리에서는 api, worker 로 나눠서 관리해요. API 서버는 외부 요청을 받아들이는 Controller 를 담아둬요. Worker 서버는 API 서비스에서 이벤트로 발생한 비동기 요청을 처리하기 위해 존재하는 서버에요. 이 두 가지 서버에선 DI 컨테이너에 구성하는 싱글톤 클래스를 각각 다르게 담아, 필요한 기능만 사용 가능하도록 구성해봤어요.
-
domain 디렉터리에는 비즈니스 로직을 포함한 실제 도메인과 관련된 로직을 위치시켰어요.
- 먼저 domain 디렉터리에는 가장 기본이 되는 엔티티와 그 엔티티를 저장하거나 찾기 위한 Repository 인터페이스를 위치시켜요.
- 이 Repository 인터페이스는 data 디렉터리에서 필요한 외부 라이브러리를 사용하여 구성해요.
- 마지막으로 application 디렉터리에는 엔티티를 사용해서 실제 비즈니스 로직을 작성하는 부분이에요. usecase 디렉터리에 외부 컨트롤러, 이벤트에서 호출할 때 사용할 인터페이스를 정의하고, 이를 Service 에서 구현하는 방식을 사용했어요.
도메인과 서버 서비스 계층을 완전히 분리한 이유는 만약 서버 구성을 다르게 가져가야 한다면, handler 디렉터리에 서버 구성 로직을 밀어넣어두고 도메인 계층에 영향이 아예 없도록 시도해보려고 구성을 했어요. 현재는 AWS lambda 사용을 기준으로 작성했지만 방어적인 구조로 인해, Docker 기반의 물리 인스턴스로도 빠르게 마이그레이션이 가능해요.
라이브러리 선택
위의 Interface - 구현체 구조를 확장성 있게, 쉽게 완성하기 위해서는 DI 컨테이너의 도움이 필요해요. NodeJS 는 런타임에서 typescript 의 인터페이스를 찾을 수 없기에 의존성 주입이 어렵기 때문에 라이브러리의 도움을 받아야 해요. 이번 프로젝트에서는 tsyringe 을 사용했어요.
이 외의 라이브러리는 크게 중요하지 않고, 배포. DI 컨테이너 외의 기술은 아래와 같아요.
- express -> 다양한 기능을 제공하고, 여러 배포 방식을 다체롭게 지원해줘서 선택했어요.
- serverless framework
- knex / objection
*여러 DI 컨테이너를 제공해주는 라이브러리들 중 자신이 익숙한 방식의 구현체를 가지고 있다면 큰 문제는 없어보여요.
3. 유즈케이스와 도메인 작성
도메인 작성
도메인은 영속계층에 영향 받지 않는, 하나의 도메인을 통채로 묶어야 해요. 영속 계층의 테이블에 영향을 받지 않아야 하며, 만약 테이블이 여러개라도 Repository 구현체에서 이를 핸들링 할 수 있기에 큰 문제는 없어요.
이번에는 Ticket 이라는 도메인 모델을 Class 를 통해 정의했어요. Class 를 통해 정의하면, 도메인 수정이나 생성에 필요한 로직을 Class 내에 몰아서 관리할 수 있어요.
export class Ticket {
id?: string = undefined
name: string
constructor(input: {
id?: string,
name: string,
}) {
this.id = input.id ?? undefined
this.name = input.name
}
}위와 같이 티켓 도메인을 만들었어요. 이 도메인은 Repository 를 통해 save 와 select 가 가능해요.
export interface TicketRepository {
findById(id: string): Promise<Ticket | undefined>
save(ticket: Ticket): Promise<Ticket>
}
export const TicketRepository = Symbol("TicketRepository"); // DI 를 위한 Symbol 이에요. 이 아티클에선 따로 다루지는 않을거에요.위와 같이 두가지 메소드를 가지고 있어요. 앞서 설명했듯, Ticket 도메인은 영속계층에서 사용되는 모델은 아니며, TicketRepository 의 구현체에서는 각각의 ORM 에서 필요로 하는 방식으로 도메인 모델을 변경해서 사용해요.
// -- 영속 계층의 모델
export class Tickets extends Model { // Objection 의 모델
id!: string
name!: string
}
---
// -- Repository 의 구현체
@injectable()
export class KnexTicketRepository implements TicketRepository {
...
async save(ticket: Ticket): Promise<Ticket> {
const object: Partial<Tickets> = { // Objection 모델로 변환
id: ticket.id,
name: ticket.name,
}
const result = await Tickets.query().upsertGraphAndFetch(object)
return result.toTicket() // 변환되어 저장된 결과를 다시 도메인 모델로 변환
}마지막으로 Application 부분이에요. 각각의 기능별로 Finder[R], Processor[CUD] 로 나눠봤어요.
export interface TicketCreateProcessor {
process(command: TicketCreateCommand): Promise<string>
}
export type TicketCreateCommand = {
name: string,
count: number,
requesterId: string,
}위와 같이 커멘드를 통해 필요한 정보를 외부에서 직접 주입해서 사용할 수 있도록 제한했어요. 만약 유효성 검증이 필요하다면 Class 로 선언해서 내부 메소드로서 검증을 위한 로직을 밀어넣어도 좋다고 생각돼요.
// TicketCreateProcessor 의 구현체
async process(command: TicketCreateCommand): Promise<string> {
const ticketId = await this.transactionManager.init(async () => {
const ticket = await this.ticketRepository.save(
new Ticket({
name: command.name,
count: command.count,
createdBy: command.requesterId
}),
)
return ticket.requireId()
})위의 로직에서 볼 수 있듯, 외부 Command 를 내부 엔티티 모델인 Ticket 으로 변환해서 사용을 하고, DI 컨테이너에서 주입받은 레포지토리를 사용하여 도메인 엔티티를 저장해요. 필요하다면 다른 엔티티를 들고와서 비즈니스 로직을 완성할 수 있어요.
컨트롤러나 그 외 다른 외부 콜에서는 Processor 나 Finder 를 통해 읽기 모델을 리턴받아서 사용하고, Repository 를 직접적으로 바라봐서 로직이 파편화되는 문제를 해결할 수 있어요.
4. 트랜잭션 다루기
Spring 의 경우 @Transactional 어노테이션을 제공해주지만 (책에서도 굉장히 짧게 다뤄서 가장 애를 먹었던 곳이에요), Nodejs 진영에선 통합된 영속 계층 규약이 없기에 이런 통합적인 규약이 없지만, ORM 에서 공통적으로 보이는 특징은 아래와 같아요.
// TypeORM
await myDataSource.transaction(async (transactionalEntityManager) => {
// execute queries using transactionalEntityManager
})
// Objection
const returnValue = await Person.transaction(async trx => {
// Here you can use the transaction.
// Whatever you return from the transaction callback gets returned
// from the `transaction` function.
return 'the return value of the transaction';
});
// Sequelize
const result = await sequelize.transaction(async (t) => {
const user = await User.create({
firstName: 'Abraham',
lastName: 'Lincoln'
}, { transaction: t });
return user;
});위의 코드들과 같이, connection / 전역 변수를 통해 Transaction 을 실행시키고, 내부 콜백에서 영속 계층을 다루기 위한 코드를 넣어서 핸들링해요.
위의 코드를 살펴보면 Application 계층에서 Repository 를 호출하는 형태가 가장 일반적이에요. 또한 비즈니스 로직에서만이 특정 데이터들을 Atomic 하게 다룰지 판단할 수 있어요. 따라서 비즈니스 로직에서 아래와 같은 형태가 보이면 트랜잭션을 컨트롤 할 수 있을거에요.
// Application 계층 구현체
async findById(id: string): Promise<TicketDetail> {
const ticket = await this.transactionManager.init(async () => { // 이곳에서 트랜잭션을 열어요.
const ticket = await this.ticketRepository.findById(id) // Repository 호출
if (ticket === undefined) throw new TicketNotFoundError()
return ticket
})
return new TicketDetail(ticket)
}
// Repository 계층 구현체
async findById(id: string): Promise<Ticket | undefined> {
const trx = this.transactionManager.getTransaction() // 현재 열려있는 트랜잭션 객체 가져오기.
const result = await Tickets
.query(trx)
.select('*')
.where('id', id)
.first()
if (result === undefined) {
return result
} else {
return result?.toTicket()
}
}
Repository 는 비즈니스 로직 내에서 호출되기에, 트랜잭션을 직접 열 수 있는 initTransaction 을 사용해서 트랜잭션 객체를 생성해요. 콜백 내에서는 getTransaction 을 통해 현재 열려있는 트랜잭션 객체를 가져올 수 있어요. (라이브러리에 따라 현재 트랜잭션 객체가 없더라도 동작하게 할 수 있을거에요. 제가 사용한 Objection 은 트랜잭션 객체가 없더라도 전역 커넥션을 꺼내와서 동작해요.)
이런 코드는 AsyncLocalStoage 를 사용하면 쉽게 구현할 수 있어요.
export class KnexTransactionManager implements TransactionManager {
private asyncLocalStorage: AsyncLocalStorage<Knex.Transaction>;
constructor() {
this.asyncLocalStorage = new AsyncLocalStorage();
}
// 트랜잭션을 열기 위한 메소드, 콜백을 받아서 트랜잭션 객체를 넣어줘요.
async init<T>(callback: (trx: Knex.Transaction) => Promise<T>): Promise<T> {
return await connection.transaction(async trx => {
return await this.asyncLocalStorage.run(trx, async () => await callback(trx))
})
}
// init 메소드 내에서 실행된
getTransaction(): Knex.Transaction | undefined {
return this.asyncLocalStorage.getStore()
}
}AsyncLocalStorage 는 Node.js 16 부터 stable 이 된 기능이에요. 마치 ThreadLocal 처럼 호출한 하나의 비동기 로직 내에서 마치 내부 스토리지를 사용할 수 있도록 도와주는 기능이에요. 이를 통해, 상위 계층에서 호출한 트랜잭션을 하위 메소드에서도 쉽게 가져다 쓸 수 있는 방식이 완성되었어요. 이 또한 외부 라이브러리로 의존성이 변경될 수 있기에, 공통기능을 묶어서 인터페이스로 제공할 수 있도록 했어요.
참고
이번 글을 쓰면서 (심심해서 만든) 원본 프로젝트 레포 에요. 설명이 안된 여러 개념들이 녹아들어 있지만 천천히 아티클을 고쳐나가보려고 해요.
추가적인 의견이 있거나 부족한 부분이 있으면 댓글로 알려주시면 감사하겠습니다..!
