옵티마이저 소개
옵티마이저(Optimizer) : SQL을 가장 빠르고 효율적으로 수행할 최적(최저비용)의 처리경로를 생성해주는 DBMS 내부의 핵심 엔진
실행계획 : 옵티마이저가 생성한 SQL 처리경로
옵티마이저의 SQL 최적화 과정
1. 사용자가 던진 쿼리수행을 위해, 후보군이 될만한 실행계획을 찾는다.
2. 데이터 딕셔너리(Data Dictionary)에 미리 수집해놓은 오브젝트 통계 및 시스템 통계정보를 이용해 각 실행계획의 예상비용을 산정한다.
3. 각 실행계획을 비교해서 최저비용을 갖는 하나를 선택한다.
옵티마이저 종류
규칙 기반 옵티마이저(Rule-Based Optimizer, RBO)
휴리스틱 옵티마이저라고도 불리며, 미리 정해놓은 규칙에 따라 액세스 경로를 평가하고 실행계획을 선택한다. 여기서 규칙이란 액세스 경로별 우선순위로서, 인덱스 구조, 연산자, 조건절 형태가 순위를 결정짓는 주요인이다.
비용 기반 옵티마이저(Cost-Based Optimizer, CBO)
비용을 기반으로 최적화를 수행한다. 여기서 비용이란, 쿼리를 수행하는데 소요되는 일량 또는 시간을 뜻한다. 미리 구해놓은 테이블과 인덱스에 대한 여러 통계정보를 기초로 각 오퍼레이션 단계별 예상 비용을 산정하고, 이를 합산한 총비용이 가장 낮은 실행계획을 선택한다.
SQL 최적화 과정
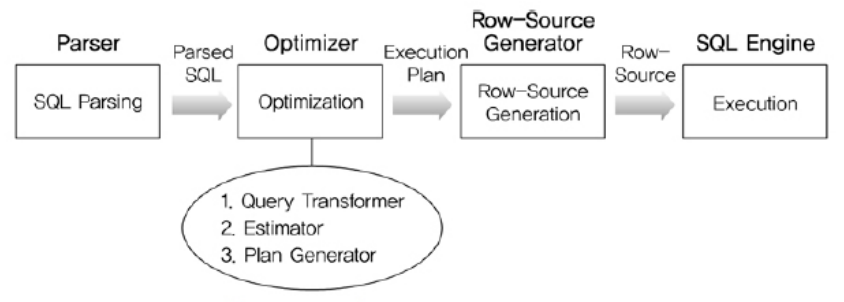
1. SQL Syntax 체크와 Semantic 체크를 한다.
2. 파싱된 SQL을 좀 더 일반적이고 표준적인 형태로 변환한다.
3. 실행계획 전체에 대한 총 비용을 계산한다.
4. 하나의 쿼리를 수행하는데 있어 후보군이 될만한 실행계획을 생성해낸다.
5. 실행계획을 SQL 엔진이 실제 실행할 수 있는 코드 형태로 포맷팅한다.
6. SQL을 실행한다.
최적화 목표
전체 처리속도 최적화
쿼리 최종 결과집합을 끝까지 읽는 것을 전제로, 시스템 리소스(I/O, CPU, 메모리 등)를 가장 적게 사용하는 실행계획을 선택한다.
alter system set optimizer_mode = all_rows;
alter session set optimizer_mode = all_rows;
select /*+ all_rows */ from t where ... ;
최초 응답속도 최적화
전체 결과집합 중 일부만 읽다가 멈추는 것을 전제로, 가장 빠른 응답속도를 낼 수 있는 실행계획을 선택한다.
alter system set optimizer_mode = first_rows;
alter session set optimizer_mode = first_rows;
select /*+ first_rows(10) */ from t where ... ;
해당 모드에서 생성된 실행 계획으로 데이터를 끝까지 읽는다면 전체 처리속도 최적화 실행계획보다 더 많은 리소스를 사용하고 전체 수행 속도도 느려질 수 있다.
옵티마이저 행동에 영향을 미치는 요소
- SQL과 연산자 형태
결과가 같더라도 작성한 형태와 어떤 연산자를 사용했는지에 따라 옵티마이저가 다른 선택을 할 수 있다. - 옵티마이징 팩터
쿼리를 똑같이 작성하더라도 인덱스, IOT, 클러스터링, 파티셔닝, MV 구성에 따라 실행 계획과 성능이 크게 달라진다. - DBMS 제약 설정
개체 무결성, 참조 무결성, 도메인 무결성 등을 위해 DBMS가 제공하는 PK, FK, Check, Not Null 같은 제약 설정 기능을 이용할 수 있고, 이들 제약 설정은 옵티마이저가 쿼리 성능을 최적화하는 데에 매우 중요한 정보를 제공한다. - 옵티마이저 힌트
- 통계정보
CBO의 모든 판단 기준은 통계정보에서 나온다. - 옵티마이저 관련 파라미터
- DBMS 버전과 종류
옵티마이저의 한계
-
옵티마이징 팩터의 부족
사용자가 적절한 옵티마이징 팩터(효과적으로 구성된 인덱스, IOT, 클러스터링, 파티셔닝 등)를 제공하지 않는다면 결코 좋은 실행계획을 수립할 수 없다. -
통계정보의 부정확성
컬럼 분포가 고르지 않을 때 컬럼 히스토그램이 반드시 필요한데, 이를 수집하고 유지하는 비용에 제약이 있다. 이는 상관관계에 있는 두 컬럼이 조건절에 사용될 때 옵티마이저가 잘못된 실행계획을 수립하게 만들 수 있다. -
바인드 변수 사용 시 균등분포 가정
아무리 정확한 컬럼 히스토그램을 보유하더라도 바인드 변수를 사용한 SQL에는 무용지물이다. -
비현실적인 가정
-
규칙에 의존하는 CBO
아무리 비용기반 옵티마이저라 하더라도 부분적으로는 규칙에 의존한다. -
하드웨어 성능
통계정보를 이용한 비용계산 원리
실행계획을 수립할 때 CBO는 SQL 문장에서 액세스할 데이터 특성을 고려하기 위해 통계정보를 이용한다.
옵티마이저 통계 유형
- 테이블 통계
: 전체 레코드 수(NUM_ROWS), 총 블록 수(BLOCKS), 빈 블록 수, 한 행당 평균 크기(AVG_ROW_LEN) 등 - 인덱스 통계
: 인덱스 높이(BLEVEL), 리프 블록 수(LEAF_BLOCKS), 클러스터링 팩터(CLUSTERING_FACTOR), 인덱스 레코드 수(NUM_ROWS) 등 - 컬럼 통계
: 값의 수(NUM_DISTINCT), 최저 값(LOW_VALUE), 최고 값(HIGH_VALUE), 밀도(DENSITY), null값 개수(NUM_NULLS), 컬럼 히스토그램(HISTOGRAM) 등 - 시스템 통계
: CPU 속도, 평균적인 I/O 속도(Single Block I/O, Multi Block I/O), 초당 I/O 처리량 등
히스토그램
옵티마이저가 더 정확하게 카디널리티를 구할 수 있도록 하며 특히, 분포가 균일하지 않은 칼럼으로 조회할 때 효과를 발휘한다.
-
도수분포(FREQUENCY) 히스토그램
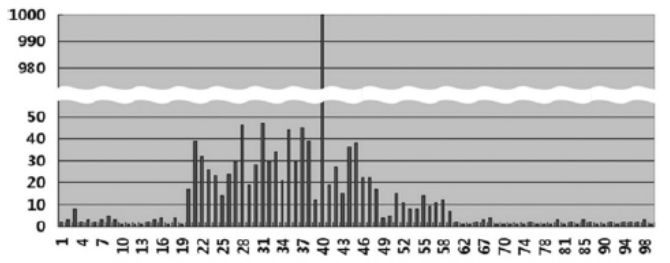
값별로 빈도수를 저장할 때 사용하며 컬럼이 가진 값의 수가 적을 떄 사용된다. -
높이균형(HEIGHT-BALANCED) 히스토그램
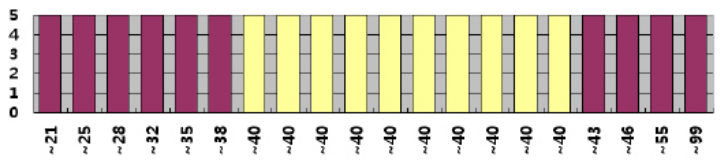
각 버킷의 높이가 동일하도록 데이터 분포를 관리하며 컬럼이 가진 값의 수가 아주 많아 각각 하나의 버킷을 할당하기 어려울 때 사용된다.
(각 버킷이 갖는 빈도수 = 총 레코드 개수 / 버킷 개수)
빈도수가 많은 값에 대해서는 두 개 이상의 버킷이 할당되며 위 그래프에서는 x축에서 나타내는 값이 40인 레코드 비중이 50%이라서 총 20개 중 10개 버킷을 차지한 것을 볼 수 있다.
비용
인덱스를 경유한 테이블 액세스 비용
I/O 비용 모델에서의 비용은 디스크 I/O Call 횟수를 의미하며 인덱스를 경유한 테이블 액세스 시에는 Single Block I/O 방식이 사용된다.
-
인덱스 키값을 모두 '=' 조건으로 검색할 때
비용
= BLEVEL + AVG_LEAF_BLOCKS_PER_KEY + AVG_DATA_BLOCKS_PER_KEY -
인덱스 키값이 모두 '='조건이 아닐 때
비용
= BLEVEL + (LEAF_BLOCKS * 유효 인덱스 선택도) + (CLUSTERING_FACTOR * 유효 테이블 선택도)
blevel : 브랜치 레벨. 리프 블록에 도달하기 전에 읽게 될 브랜치 블록 개수
클러스터링 팩터 : 특정 컬럼을 기준으로 같은 값을 갖는 데이터가 서로 모여있는 정도.
유효 인덱스 선택도 : 전체 인덱스 레코드 중에서 조건절을 만족하는 레코드를 찾기 위해 스캔할 것으로 예상되는 비율 = 방문할 리프 블록 비율
유효 테이블 선택도 : 인덱스 스캔을 완료하고서 최종적으로 테이블을 방문할 것으로 예상되는 비율. 클러스터링 팩터에 곱함으로써 조건절에 대해 읽힐 것으로 예상되는 테이블 블록 개수를 구할 수 있음.
Full Scan에 의한 테이블 액세스 비용
테이블 전체를 순차적으로 읽어들이는 과정에서 발생하는 I/O Call 횟수로 비용을 계산한다. Full Scan할 때는 한 번의 I/O Call로써 여러 블록을 읽어들이는 Multiblock I/O 방식을 사용하므로 총 블록 수를 Multiblock I/O 단위로 나눈만큼 I/O Call이 발생한다.
