소트와 성능
메모리 소트와 디스크 소트
SQL 수행 도중 Sort 오퍼레이션이 필요할 때마다 DBMS는 정해진 메모리 공간에 Sort Area를 할당하고 정렬을 수행한다. Oracle은 소트 영역을 PGA 영역에 할당한다.
Sort 오퍼레이션도 메모리 공간이 부족할 때는 디스크 공간을 사용한다. Oracle에서는 Temp Tablespace를 이용한다.
가급적 소트 영역 내에서 데이터 정렬 작업을 완료하는 것이 최적이지만, 대량의 데이터를 정렬할 때는 디스크 소트가 불가피하다. 특히, 전체 대상 집합을 디스크에 기록했다가 다시 읽는 작업을 여러 번 반복하는 경우 SQL 수행 성능은 극도로 나빠진다.
- 메모리(In-Memory) 소트
: 전체 데이터의 정렬 작업을 할당받은 소트 영역 내에서 완료하는 것을 말하며, 'Internal Sort' 또는 'Optimal Sort'라고도 한다. - 디스크(To-Disk) 소트
: 할당받은 소트 영역 내에서 정렬을 완료하지 못해 디스크 공간까지 사용하는 경우를 말함, 'External Sort'라고도 한다.
디스크에 임시 저장했다가 다시 읽는 작업을 반복한 횟수에 따라 디스크 소트를 다음 두 가지로 구분하기도 한다.
(One pass Sort - 정렬 대상 집합을 디스크에 한 번만 기록함.
Multipass Sort - 정렬 대상 집합을 디스크에 여러 번 기록함.)
소트를 발생시키는 오퍼레이션
1) Sort Aggregate
: 전체 로우를 대상으로 집계를 수행할 때 나타난다. Oracle 실행계획에 'sort'라는 표현이 사용됐지만 실제 소트가 발생하지는 않는다.
select sum(sal), max(sal), min(sal) from emp;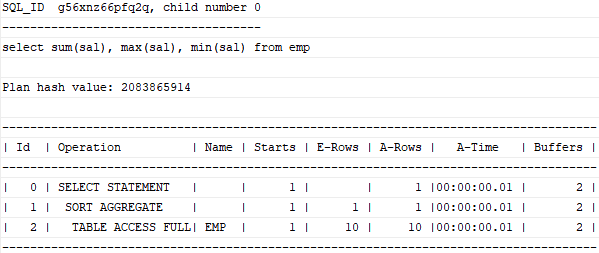
데이터 정렬 없이 SUM, MAX, MIN, AVG 값을 구하는 절차
- Sort Area에 SUM, MAX, MIN, COUNT 값을 위한 변수를 각각 하나씩 할당한다.
- 테이블 첫 번째 레코드에서 읽은 특정 컬럼의 값을 SUM, MAX, MIN 변수에 저장하고 COUNT 변수에는 1을 저장한다. (초기화)
- 테이블에서 레코드를 하나씩 읽어 내려가면서 SUM 변수에는 값을 누적하고, MAX 변수에는 기존보다 큰 값이 나타날 때마다 값을 대체하고, MIN 변수에는 기존보다 작은 값이 나타날 때마다 값을 대체한다. COUNT 변수에는 NULL이 아닌 레코드를 만날 때마다 1씩 증가시킨다.
(일단 NULL이 나오면 무시하기)- 레코드를 다 읽고 나면 SUM, MAX, MIN 값은 변수에 담긴 값을 그대로 출력하고, AVG는 SUM 값을 COUNT 값으로 나눈 2800을 출력하면 된다.
2) Sort Order By
정렬된 결과집합을 얻고자 할 때 나타난다.
select * from emp order by sal desc;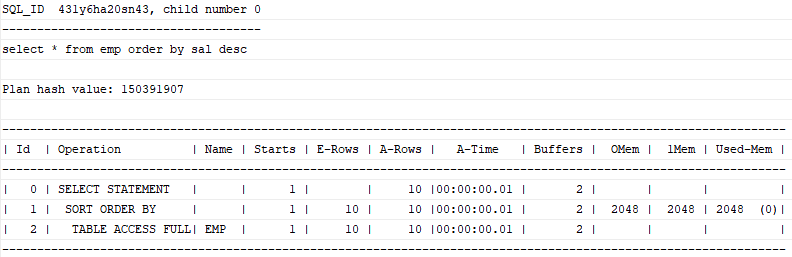
3) Sort Group By
Sort Group By는 소팅 알고리즘을 사용해 그룹별 집계를 수행할 때 나타난다.
select deptno, sum(sal), max(sal), min(sal), avg(sal)
from emp
group by deptno
order by deptno;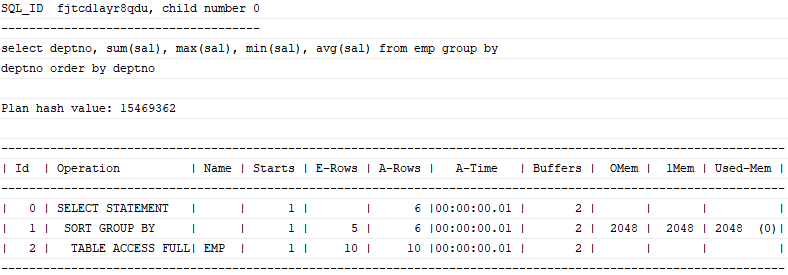
실행계획에서 표시된 'Sort Group By'의 의미는 소팅 알고리즘을 사용해 값을 집계한다는 뜻일 뿐 결과의 정렬을 의미하지는 않는다. 따라서 정렬된 그룹핑 결과를 얻고자 한다면, 실행계획에 설령 'Sort Group By'라고 표시되더라도 반드시 Order By를 명시해야 한다.
Group By 절에 Order By절을 명시하지 않으면 대부분 Hash Group By 방식으로 처리한다.
select deptno, sum(sal), max(sal), min(sal), avg(sal)
from emp
group by deptno;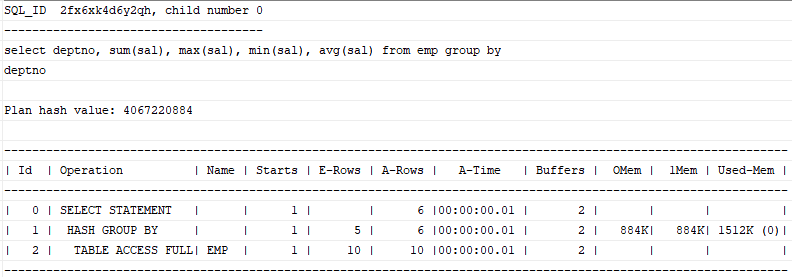
읽는 레코드마다 Group By 컬럼의 해시 값으로 해시 버킷을 찾아 그룹별로 집계항목을 갱신하는 방식이다. 여기서 주의할 점은 Hash Group By는 정렬 순서를 보장하지 않는다는 것이다.
4) Sort Unique
옵티마이저가 서브쿼리를 풀어 일반 조인문으로 변환하는 것을 '서브쿼리 Unnesting'이라고 한다. Unnesting된 서브쿼리가 M쪽 집합이면(1쪽 집합이더라도 모인 컬럼에 Unique 인덱스가 없으면) 메인 쿼리와 조인하기 전에 중복 레코드부터 제거해야 한다.
select /*+ ordered use_no(dept) */ *
from dept
where deptno in (select /*+ unnest */ deptno
from emp
where job = 'CLERK');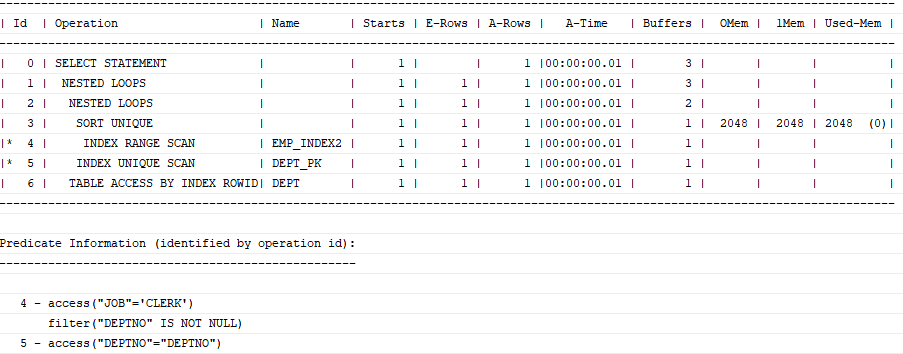
여기서 emp가 m쪽 집합이다. 만약 PK/Unique 제약 또는 Unique 인덱스를 통해 Unnesting된 서브쿼리의 유일성이 보장된다면, Sort Unique 오퍼레이션은 생략된다.
Union, Minus, Intersect과 같은 집합 연산자를 사용할 때도 Sort Unique 오퍼레이션이 나타난다.
- Union
select job, mgr from emp where deptno = 10
union
select job, mgr from emp where deptno = 20;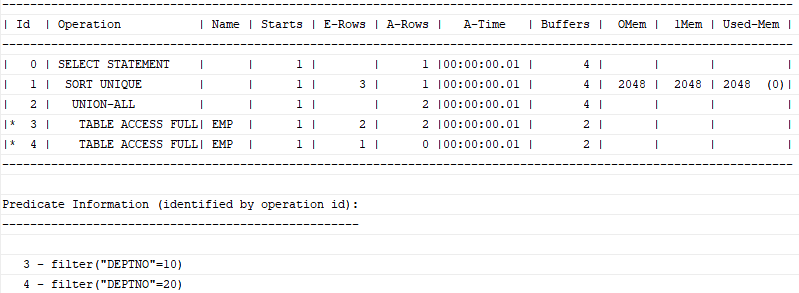
- Minus
select job, mgr from emp where deptno = 10
minus
select job, mgr from emp where deptno = 20;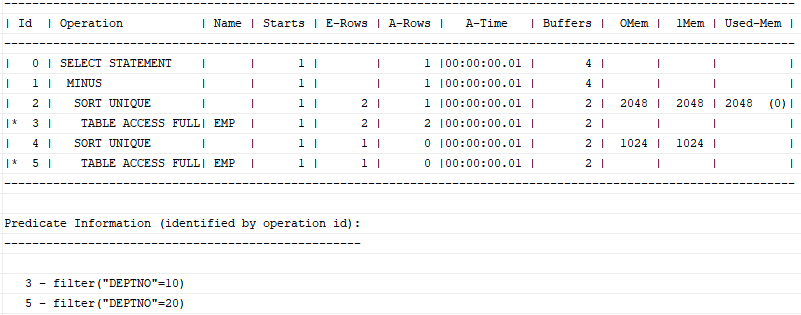
또한, Distinct 연산자를 사용해도 Sort Unique 오퍼레이션이 나타난다.
select distinct deptno from emp order by deptno;
(+ 참고로 Oracle 10gR2부터는 Distinct 연산에도 Order By를 생략할 때 Hash Unique 방식을 사용한다.
5) Sort Join
Sort Join 오퍼레이션은 소트 머지 조인을 수행할 때 나타난다.
select /*+ ordered use_merge(e) */ * from dept d, emp e where d.deptno = e.deptno;
지금 이렇게 INDEX를 통해 Table을 액세스할 경우 Sort Join은 생략하게 된다. 이미 Index 상에서 정렬된 상태이기 때문에 따로 정렬할 필요가 없어지기 때문이다.
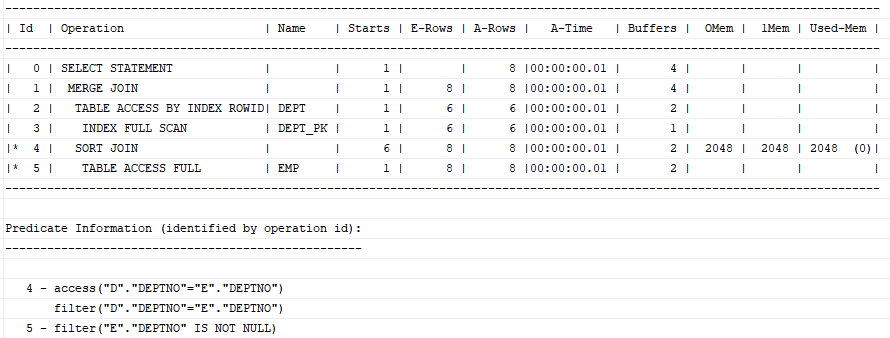
6) Window Sort
Window Sort는 윈도우 함수를 수행할 때 나타난다.
select empno, ename, job, mgr, sal, avg(sal) over (partition by deptno)
from emp;
소트 튜닝 요약
소트 오퍼레이션은 메모리 집약적일 뿐만 아니라 CPU 집약적이기도 하며, 데이터량이 많을 때는 디스크 I/O까지 발생시키므로 쿼리 성능을 크게 떨어뜨린다. 특히, 부분범위처리를 할 수 없게 만들어 OLTP 환경에서 성능을 떨어뜨리는 주 요인이 되곤 한다. 될 수 있으면 소트가 발생하지 않도록 SQL을 작성해야 하고, 소트가 불가피하다면 메모리 내에서 수행을 완료할 수 있도록 해야 한다.
- 데이터 모델 측면에서의 검토
- 소트가 발생하지 않도록 SQL 작성
- 인덱스를 이용한 소트 연산 대체
- 소트 영역을 적게 사용하도록 SQL 작성
- 소트 영역 크기 조정
데이터 모델 측면에서의 검토
group by, union, distinct 같은 연산자가 심하게 많이 사용되는 패턴을 보인다면 대개 데이터 모델이 잘 정규화되지 않았음을 암시한다.
소트가 발생하지 않도록 SQL 작성
Union을 Union All로 대체
Union을 사용하면 옵티마이저는 상단과 하단의 두 집합 간 중복을 제거하려고 Sort Unique 연산을 수행한다. 반면, Union All은 중복을 허용하며 두 집합을 단순히 결합하므로 소트 연산이 불필요하다.
- Union
select empno, job, mgr from emp where deptno = 10
union
select empno, job, mgr from emp where deptno = 20;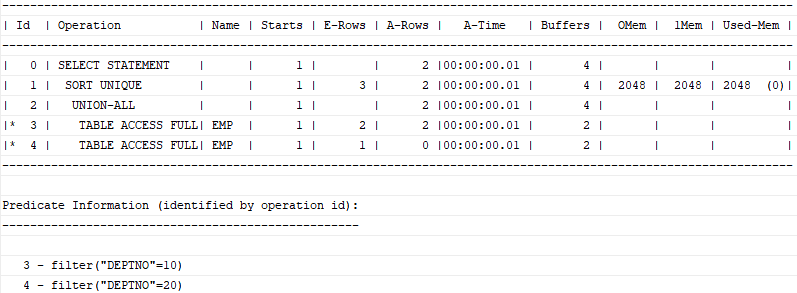
- Union All
select empno, job, mgr from emp where deptno = 10
union all
select empno, job, mgr from emp where deptno = 20;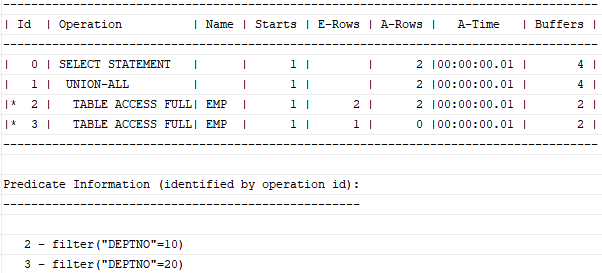
select-list에 PK 컬럼인 empno를 포함하므로 두 집합간에는 중복 가능성이 전혀 없다. Union을 사용하든 Union all을 사용하든 결과집합이 같으므로 Union all을 사용하는 것이 마땅하다.
참고로, select-list에 PK컬럼이 없다면 deptno가 10번과 20번에 해당하는 job, mgr이 같은 사원이 있을 수 있으므로 함부로 Union all로 바꾸면 안된다.
Distinct를 Exists 서브쿼리로 대체
중복 레코드를 제거하려고 distinct를 사용하는 경우도 종종 있는데, 이 연산자를 사용하면 조건에 해당하는 데이터를 모두 읽어서 중복을 제거해야 한다. 부분범위 처리는 불가능하며 모든 데이터를 읽는 과정에 많은 I/O가 발생한다.
대부분 exists 서브쿼리로 대체함으로써 소트 연산을 제거할 수 있다.
Distinct 사용 시
select distinct p.상품번호, p.상품명, p.상품가격
from 상품 p, 계약 c
where p.상품유형코드 = :pclscd
and c.상품번호 = p.상품번호
and c.계약일자 between :dt1 and :dt2
and c.계약구분코드 = :ctpcd;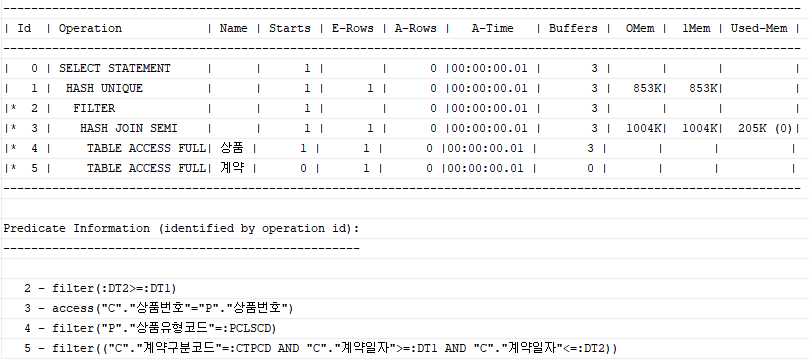
Exists 사용 시
select *
from 상품 p
where p.상품유형코드 = :pclscd
and exists (select 'x'
from 계약 c
where c.상품번호 = p.상품번호
and c.계약일자 between :dt1 and :dt2 and c.계약구분코드 = :ctpcd
);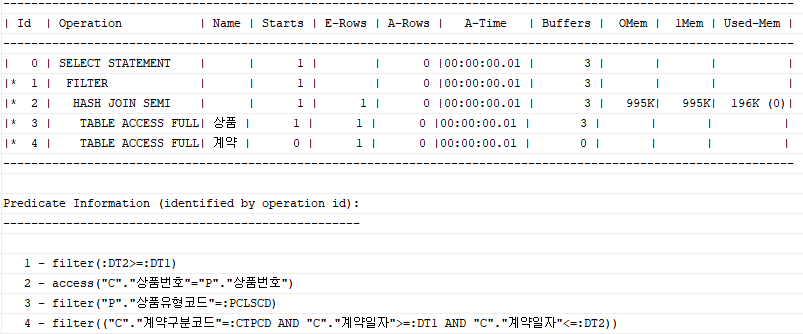
두 경우를 비교했을 때 Exists 사용 시 HASH UNIQUE가 사라진 것을 확인할 수 있다.
Exists 서브쿼리는 데이터 존재 여부만 확인하면 되기 때문에 조건절을 만족하는 데이터를 모두 읽지 않는다. Exists는 조건에 맞는 레코드를 만나는 순간 True 반환 후 서브쿼리 수행을 마친다.
위 쿼리에서 c.상품번호 = p.상품번호 에 대해 c.계약일자가 :dt1과 :dt2 사이이고 c.계약구분코드 = :ctpcd인 조건을 만족하는 데이터가 한 건이라도 존재하는지만 확인하면 된다. Distinct 연산자를 사용하지 않았으므로 상품 테이블에 대한 부분범위 처리도 가능하다.
Distinct, Minus 연산자를 사용한 쿼리는 대부분 Exists 서브쿼리로 변환 가능하다.
인덱스를 이용한 소트 연산 대체
인덱스는 항상 키 컬럼 순으로 정렬된 상태를 유지한다. 이를 활용하면 SQL에 Order By 또는 Group By 절이 있어도 소트 연산을 생략할 수 있다. 여기에 Top N 쿼리 특성을 결합하면, 온라인 트랜잭션 처리 시스템에서 대량 데이터를 조회할 때 매우 빠른 응답 속도를 낼 수 있다. 또한, 특정 조건을 만족하는 최소값 또는 최대값도 빨리 찾을 수 있다.
Sort Order By 생략
아래의 쿼리에서는 Sort 연산을 생략할 수 없다.
select /*+ full(종목거래) */ 거래일시, 체결건수, 체결수량, 거래대금
from 종목거래
where 종목코드 = 'KR123456'
order by 거래일시;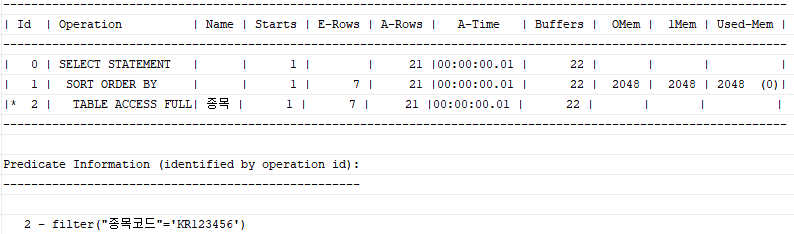
본인이 기존에 Sort Order By를 생략할 수 있는 인덱스를 만들어놨기 때문에 적절한 인덱스가 없을 경우 실행시키기 위해 Full Table Access를 유도하기 위한 옵티마이저 힌트를 사용하였다. 모든 데이터를 다 읽어 거래일시 순으로 정렬을 마치고서야 출력을 시작하므로 OLTP 환경에서 요구되는 빠른 응답 속도를 내기 어렵다.
이 상황에서 특정 종목코드에 대해 거래일시가 정렬 되어있는 인덱스를 사용해야 하므로 종목코드 + 거래일시 인덱스가 필요하다. 해당 인덱스를 탔을 때 실행 시 결과가 다음과 같다.
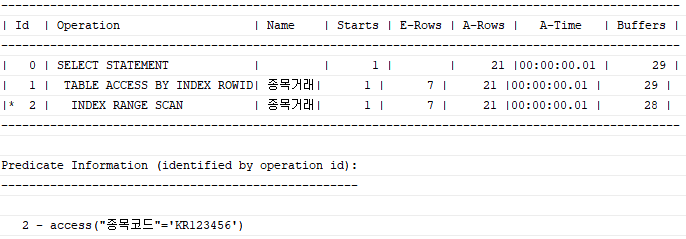
SORT ORDER BY가 사라진 것을 볼 수 있다. Sort 연산을 생략함으로써 종목코드 'KR123456' 조건을 만족하는 전체 레코드를 읽지 않고도 바로 결과집합 출력을 시작할 수 있게 되었다. 즉, 부분범위 처리가 가능한 상태가 되었다.
부분범위 처리는 쿼리 수행 결과 중 앞쪽 일부를 우선 전송하고 멈추었다가 클라이언트가 추가 전송을 요청할 때마다 남은 데이터를 조금씩 나눠 전송하는 방식을 말한다. 부분범위 처리 활용은 결과집합 출력을 바로 시작할 수 있느냐, 앞쪽 일부만 출력하고 멈출 수가 있느냐가 핵심이다.
물론, 소트해야 할 대상 레코드가 무수히 많고 그 중 일부만 읽고 멈출 수 있을 때만 유용하다. 만약 인덱스를 스캔하면서 결과집합을 끝까지 Fetch 한다면 오히려 I/O 및 리소스 사용 측면에서 손해다. 대상 레코드가 소량일 때는 소트가 발생하더라도 부하가 크지 않아 개선 효과도 미미하다.
Top N 쿼리
Top N 쿼리는 전체 결과집합 중 상위 N개 레코드만 선택하는 쿼리다. SQL Server나 Sybase는 Top N 쿼리를 다음과 같이 제공해준다.
select TOP 10 거래일시, 체결건수, 체결수량, 거래대금
from 종목거래
where 종목코드 = 'KR123456'
and 거래일시 >= '20180304'
order by 거래일시;오라클에서는 좀 불편하게 작성된다...
select *
from (select 거래일시, 체결건수, 체결수량, 거래대금
from 종목거래
where 종목코드 = 'KR123456'
and 거래일시 >= '20180304'
order by 거래일시
)
where rownum <= 10;위 쿼리에 종목코드 + 거래일시 로 구성된 인덱스를 이용하면, 옵티마이저는 소트 연산을 생략하며, 인덱스를 스캔하다가 10개 레코드를 읽는 순간 바로 멈춘다. 실행 계획은 다음과 같다.
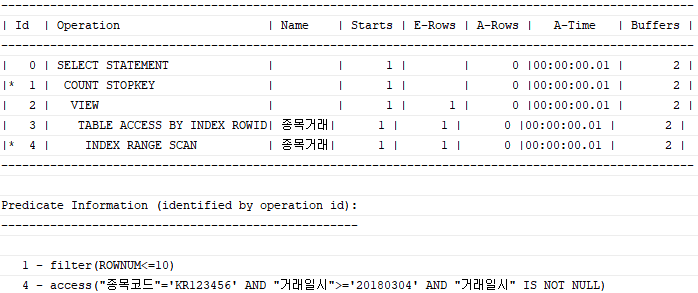
SORT ORDER BY가 사라진 것을 볼 수 있다. 대신 'COUNT STOPKEY'를 볼 수 있다. 이는 조건절에 부합하는 레코드가 아무리 많아도 그 중 ROWNUM으로 지정한 건수만큼 결과 레코드를 얻으면 거기서 바로 멈춘다는 뜻이다.
COUNT : PSEUDO COLUMNS가 SELECT 문장에 나타날 때 (Stopkey가 작동하지 않아 전체 범위를 처리하게 된다.)
COUNT STOPKEY : PSEUDO COLUMNS가 WHERE절에 나타날 때
최소값/최대값 구하기
최소값(MIN) 또는 최대값(MAX)을 구하는 SQL 실행계획을 보면, Sort Aggregate 오퍼레이션이 나타난다. 인덱스는 정렬되어 있으므로 이를 이용하면 전체 데이터를 읽지 않고도 최소 또는 최대값을 쉽게 찾을 수 있다. 인덱스 맨 왼쪽으로 내려가서 첫 번째 읽는 값이 최소값이고, 맨 오른쪽으로 내려가서 첫 번째 읽는 값이 최대값이다.
인덱스를 이용해 MIN/MAX를 구하기 위한 조건
전체 데이터를 읽지 않고 인덱스를 이용해 최소 또는 최대값을 구하려면, 조건절 컬럼과 MIN/MAX 함수 인자 컬럼이 모두 인덱스에 포함되어 있어야 한다. 즉, 테이블 액세스가 발생하지 않아야 한다.
select max(sal)
from emp
where deptno = 30 and mgr = '7698';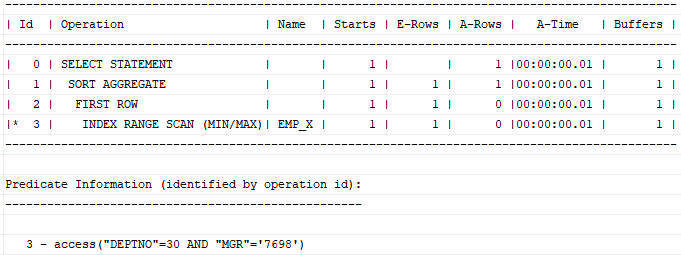
인덱스는 DEPTNO + MGR + SAL 로 구성되어 있다. 조건절 컬럼과 MAX 컬럼이 모두 인덱스에 포함되어 있고, 인덱스 선두 컬럼 DEPTNO, MGR이 모두 '=' 조건이므로 이 두 조건을 만족하는 범위 가장 오른쪽에 있는 값 하나를 읽는다. 여기서 'FIRST ROW'는 조건을 만족하는 레코드 하나를 찾았을 때 바로 멈춘다는 것을 의미한다. 조건절을 만족하는 데이터가 하나도 없다면 나타나지 않는다.
또한, MAX/MIN을 구하고자 하는 컬럼과 조건절에서 사용하는 컬럼은 모두 인덱스를 구성하고 있어야 한다. 그렇지 않는 경우에 대해서 예를 들어보자. 쿼리는 위와 동일하다.
select max(sal)
from emp
where deptno = 30 and mgr = '7698';현재 인덱스는 deptno + sal이다. deptno가 30이면서 그 안에서 max(sal)은 인덱스를 통해 쉽게 찾을 수 있다. 하지만 mgr = '7698'을 만족하는지는 Table Access를 하지 않는 이상 알 수 없다. 실행 계획은 다음과 같다.
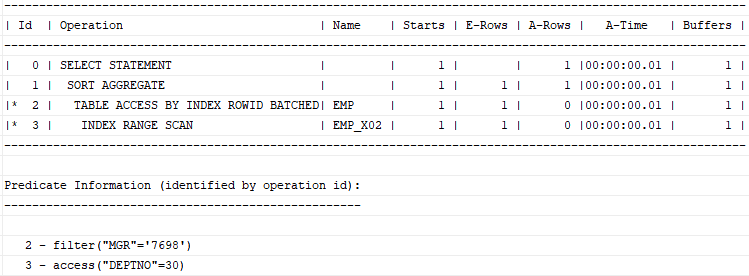
즉, 처음에 인덱스상 두 조건을 만족하는 위치가 모든 조건을 만족하는 위치라는 보장이 없는 것이다. 따라서 First Row Stopkey 알고리즘이 작동하지 않는다. (실행계획상 First Row가 없다.)
참고로 MIN/MAX 함수 내에서 인덱스 컬럼을 가공하면 인덱스를 사용하지 못하여 SORT 연산을 생략할 수 없게 된다.
Top N 쿼리를 이용해 MIN/MAX값 구하기
Top N 쿼리를 통해서도 최소 또는 최대값을 쉽게 구할 수 있다. ROWNUM <= 1 조건을 이용해 Top 1 레코드를 찾으면 된다.
select *
from ( select sal
from emp
where deptno = 30
and mgr = 7698
order by sal desc
)
where rownum <= 1;max(sal)을 구하기 위한 쿼리이다. 여기서 조건절과 order by에 사용되는 모든 컬럼이 인덱스를 구성해야 할 필요는 없다. (DEPTNO + SAL 이런 식으로 일부로만 구성되어도 된다.)
DEPTNO + SAL로 인덱스를 구성했을 때 mgr의 값을 알기 위해 table 액세스가 필요하다. table 액세스 후 조건에 맞다면 바로 멈추면 된다.
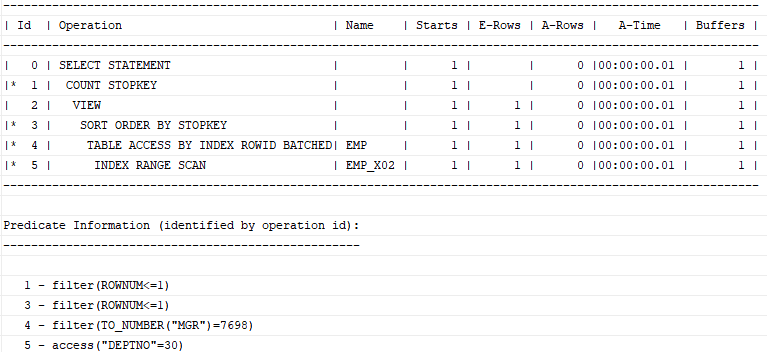
Top N 쿼리에 작동하는 Top N Stopkey 알고리즘은 모든 컬럼이 인덱스에 포함돼 있지 않아도 잘 작동한다. 특정 컬럼에 대한 MAX값을 구할 때 인덱스의 가장 오른쪽부터 역순으로 스캔하면서 테이블을 액세스하다가 조건을 만족하는 레코드 하나를 찾았을 때 바로 멈춘다. 따라서 실행계획에서도 COUNT STOPKEY를 볼 수 있다.
인라인 뷰를 사용하므로 쿼리가 약간 더 복잡하긴 하지만, 성능 측면에서는 MIN/MAX 쿼리보다 낫다.
소트 영역을 적게 사용하도록 SQL 작성
소트 연산이 불가피하다면 메모리 내에서 처리되게 하려고 노력해야 한다. 소트 영역 크기를 늘리는 방법도 있지만 그 전에 소트 영역을 적게 사용할 방법부터 찾는 것이 순서다.
- 소트 완료 후 데이터 가공
- Top-N 쿼리
Top-N 쿼리의 소트 부하 경감 원리
예를 들어 Top 10 (rownum <= 10)이면, 우선 10개 레코드를 담을 배열을 할당하고 처음 읽은 10개 레코드를 정렬된 상태로 담는다.
이후 읽는 레코드에 대해서는 맨 우측에 있는 값(=가장 큰 값)과 비교해서 그보다 작은 값이 나타날 때만 맨 우측에 있는 값을 버리고 배열 내에서 다시 정렬을 시도한다. 이 방식으로 처리하면 전체 레코드를 정렬하지 않고도 오름차순으로 최소값을 갖는 10개의 레코드를 정확히 찾아낼 수 있다.
윈도우 함수에서의 Top-N 쿼리
윈도우 함수를 이용해 마지막 이력 레코드를 찾는 경우를 보자.
- max() 함수 사용
select 고객ID, 변경순번, 전화번호, 주소, 자녀수, 직업, 고객등급
from (select 고객ID, 변경순번, max(변경순번) over (partition by 고객ID) 마지막변경순번, 전화번호, 주소, 자녀수, 직업, 고객등급
from 고객변경이력)
where 변경순번 = 마지막변경순번;- rank() 함수 사용
select 고객ID, 변경순번, 전화번호, 주소, 자녀수, 직업, 고객등급
from ( select 고객ID, 변경순번, rank() over (partition by 고객ID order by 변경순번) rnum, 전화번호, 주소, 자녀수, 직업, 고객등급
from 고객변경이력)
where rnum = 1;윈도우 함수를 사용할 때도 max() 함수보다 rank()나 row_number() 함수를 사용하는 것이 유리한데, 이것은 Top-N 쿼리 알고리즘이 작동하기 때문이다.
소트 영역 크기 조정
(참고로 SQL Server에서는 소트 영역을 수동으로 조정하는 방법을 제공하지 않는다.)
소트가 불가피하다면, 메모리 내에서 작업을 완료할 수 있어야 최적이다. 디스크 소트가 불가피할 때는, 임시 공간에 기록했다가 다시 읽는 횟수를 최소화할 수 있어야 최적이다.
이를 위해 관리자가 시스템 레벨에서, 또는 사용자가 세션 레벨에서 직접 소트 영역 크기를 조정하는 작업이 필요할 수 있다.
기본적으로 자동 PGA 메모리 관리 방식이 활성화되지만 시스템 또는 세션 레벨에서 '수동 PGA 메모리 관리' 방식으로 전환할 수 있다. 특히, 트랜잭션이 거의 없는 야간에 대량의 배치 Job을 수행할 때는 수동 방식으로 변경하고 직접 크기를 조정하는 것이 효과적일 수 있다. 자동 PGA 메모리 관리 방식 하에서는 프로세스당 사용할 수 있는 최대 크기가 제한되기 때문이다. 즉, 소트 영역을 사용 중인 다른 프로세스가 없더라도 특정 프로세스가 모든 공간을 다 쓸 수 없어 여유 메모리를 두고도 이를 충분히 활용하지 못해 작업 시간이 오래 걸릴 수 있다.
