인덱스 기본
인덱스 구조
가장 일반적으로 B*Tree 인덱스 구조를 사용한다.
인덱스 깊이 : 루프에서 리프 블록까지의 거리. 반복적으로 탐색 시 성능에 영향을 미친다.
루트, 브랜치 블록
: 각 하위 노드들의 데이터 값 범위를 나타내는 키값과 그 키값에 해당하는 블록을 찾는데 필요한 주소 정보를 가진다.
리프 블록
: 인덱스 키 값과 그 키 값에 해당하는 테이블 레코드를 찾아가는데 필요한 주소 정보(ROWID)를 가진다. (키값이 같을 경우 ROWID 순으로 정렬된다.)
범위 스캔(Range Scan)이 가능하며 양방향 Linked List로 구성되어 있어 정방향과 역방향 스캔이 가능하다.
(+ ROWID에서는 오브젝트 번호, 데이터 파일 번호, 블록 번호, 블록 내 위치 정보를 알 수 있다.)
Null값 인덱스 저장 방법
Oracle :
인덱스 구성 컬럼이 모두 Null인 레코드는 인덱스에 저장하지 않는다.
SQL Server :
인덱스 구성 컬럼이 모두 Null인 레코드도 인덱스에 저장한다.
Null값을 Oracle은 맨 뒤에 저장하고 SQL Server는 맨 앞에 저장한다.
인덱스 탐색
수평적 탐색 : 인덱스 리프 블록에 저장된 레코드끼리 연결된 순서에 따라 좌에서 우, 우에서 좌로 스캔한다.
수직적 탐색 : 수평적 탐색을 위한 시작 지점을 찾는 과정
다양한 인덱스 스캔 방식
Index Range Scan
인덱스 루트 블록에서 리프 블록까지 수직적으로 탐색한 후에 리프 블록을 필요한 범위(Range)만 스캔하는 방식이다.
B*Tree 인덱스의 가장 일반적이고 정상적인 형태의 액세스 방식이다.
실행계획 상에 Index Range Scan이 나타난다고 해서 항상 빠른 속도를 보장하는 것은 아니다. 인덱스를 스캔하는 범위(Range)를 얼마만큼 줄일 수 있느냐, 테이블로 액세스하는 횟수를 얼마만큼 줄일 수 있느냐가 관건이며, 이는 인덱스 설계와 SQL 튜닝의 핵심 원리 중 하나이다.
Index Range Scan이 가능하게 하려면 인덱스를 구성하는 선두 컬럼이 가공되지 않은 상태로 조건절에 사용되어야 한다. 그렇지 못한 상황에서 인덱스를 사용하도록 힌트로 강제한다면 Index Full Scan 방식으로 처리된다.
Index Full Scan
수직적 탐색 없이 인덱스 리프 블록을 처음부터 끝까지 수평적으로 탐색하는 방식으로서, 대개는 데이터 검색을 위한 최적의 인덱스가 없을 때 차선으로 선택된다.
그런데, 사실은 수평적 탐색이 일어나기는 한다. 루트 블록과 브랜치 블록을 거치지 않고는 가장 왼쪽에 위치한 첫 번째 리프 블록으로 찾아갈 방법이 없기 때문이다.
인덱스 선두 컬럼이 조건절에 없으면 옵티마이저는 우선적으로 Table Full Scan을 고려한다. 그런데 대용량 테이블이어서 Table Full Scan의 부담이 크다면 옵티마이저는 인덱스를 활용하는 방법을 다시 생각해본다.
만약 인덱스 스캔 단계에서 대부분 레코드를 필터링하고 일부에 대해서만 테이블 액세스가 발생하는 경우라면 테이블 전체를 스캔하는 것보다 낫다.
(데이터 저장공간은 컬럼 길이 * 레코드 수에 의해 결정되기 때문에 대개 인덱스가 차지하는 면적은 테이블보다 훨씬 적다.)
하지만 이는 차선책이기 때문에 수행 빈도가 낮은 SQL이면 상관 없지만, 그렇지 않다면 인덱스를 따로 생성해주는 것이 좋다.
인덱스를 Full Scan 하면 Range Scan과 마찬가지로 결과집합이 인덱스 컬럼 순으로 정렬되기 때문에 Sort Order By 연산을 생략할 목적으로 사용할 수도 있다. 이 때는 차선책이 아니라 옵티마이저가 전략적으로 선택한 경우에 해당한다.
select /*+ first_rows */ *
from emp
where sal > 1000 order by ename;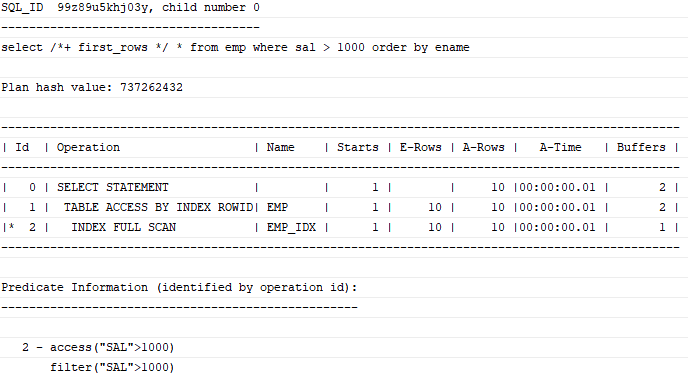
만약 대부분의 행이 조건에 해당한다면 인덱스 사용 시 Table Full Scan할 때보다도 성능이 저하된다. 그럼에도 불구하고 first_rows 힌트를 사용하면 소트 연산을 생략함으로써 전체 집합 중 처음 일부를 빠르게 출력할 목적으로 옵티마이저가 Index Full Scan 방식을 선택한다. 이 선택은 부분범위 처리가 가능한 상황에서 극적인 성능 개선 효과를 가져다 준다.
Index Unique Scan
수직적 탐색만으로 데이터를 찾는 스캔 방식으로서 Unique 인덱스를 '=' 조건으로 탐색하는 경우에 작동한다. Unique 인덱스는 DBMS가 데이터 정합성을 관리해주므로 데이터를 한 건 찾는 순간 더이상 탐색할 필요가 없다.
Unique 인덱스라고 해도 범위검색 조건(between, 부등호, like)으로 검색할 때는 Index Range Scan으로 처리된다.
또한, Unique 결합 인덱스에 대해 일부 컬럼만으로 검색할 때도 Index Range Scan이 나타난다.
ex) 인덱스를 컬럼1 + 컬럼2 + 컬럼3으로 구성했는데 컬럼1과 컬럼2로만 검색하는 경우
Index Skip Scan
인덱스 선두 컬럼을 조건절에서 사용하지 않았을 때 Table Full Scan보다 I/O를 줄일 수 있거나 정렬된 결과를 쉽게 얻을 수 있다면 Index Full Scan을 사용하기도 한다. 오라클은 인덱스 선두 컬럼이 조건절에 없어도 인덱스를 활용하는 새로운 스캔 방식을 9i 버전에서 선보였는데 Index Skip Scan이 그것이다.
Index Skip Scan은 루트 또는 브랜치 블록에서 읽은 컬럼 값 정보를 이용해 조건에 부합하는 레코드를 포함할 "가능성이 있는" 하위 블록을 골라서 액세스하는 방식이다. 이 스캔 방식은 조건절에 빠진 인덱스 선두 컬럼의 Distinct Value 개수가 적고 후행 컬럼의 Distinct Value 개수가 많을 때 유리하다.
SELECT /*+ index_ss(사원 사원_IDX) */
FROM 사원
WHERE 연봉 BETWEEN 2000 AND 4000;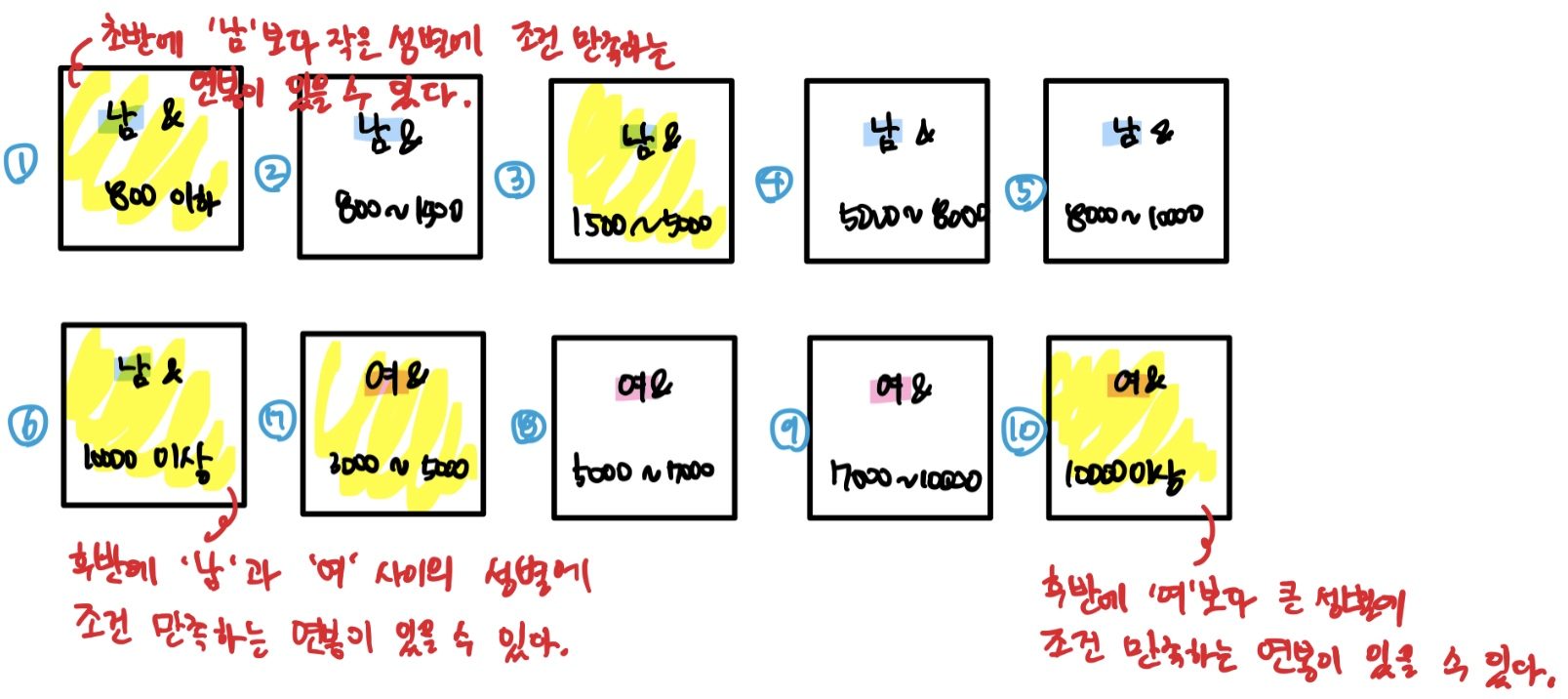
(사원_IDX : 성별 + 연봉)
노란색으로 칠한 블록이 접근한 블록이며 1, 6, 10번 블록에 접근한 이유를 아는 것이 중요하다. 우리는 성별이 '남'과 '여'로 구성되었다는 사실을 이미 알고 있지만 옵티마이저는 모르기 때문에 발생하는 현상이다.
Index Skip Scan이 작동하기 위한 조건
- 선두 컬럼에 대한 조건절은 있고, 중간 컬럼에 대한 조건절이 없는 경우
- 선두 컬럼이 부등호, BETWEEN, LIKE 같은 범위검색 조건인 경우
...인덱스는 기본적으로 최적의 Index Range Scan을 목표로 설계해야 하며, 수행 횟수가 적은 SQL을 위해 인덱스를 추가하는 것이 비효율적일 때 이들 스캔 방식을 차선책으로 활용하는 전략이 바람직하다.
Index Fast Full Scan
말 그대로 Index Fast Full Scan은 Index Full Scan보다 빠르다. Index Fast Full Scan이 Index Full Scan보다 빠른 이유는, 인덱스 트리 구조를 무시하고 인덱스 세그먼트 전체를 Multiblock Read 방식으로 스캔하기 때문이다.
Index Full Scan VS Index Fast Full Scan
1) Index Full Scan
- 인덱스 구조를 따라 스캔
- 결과집합 순서 보장
- Single Block I/O
- (파티션 되어있지 않으면) 병렬스캔 불가
- 인덱스에 포함되지 않은 컬럼 조회 시에도 사용 가능
2) Index Fast Full Scan
- 세그먼트 전체를 스캔
- 결과집합 순서 보장 안됨 (물리적으로 디스크에 저장된 순서대로 인덱스 리프 블록들을 읽어들이기 때문)
- Multiblock I/O
- 병렬스캔 가능
- 인덱스에 포함된 컬럼으로만 조회할 때 사용 가능
Index Range Scan Descending
Index Range Scan과 기본적으로 동일한 스캔 방식이다. 인덱스를 뒤에서부터 앞쪽으로 스캔하기 때문에 내림차순으로 정렬된 결과집합을 얻는다는 점만 다르다.
select *
from emp
order by empno desc;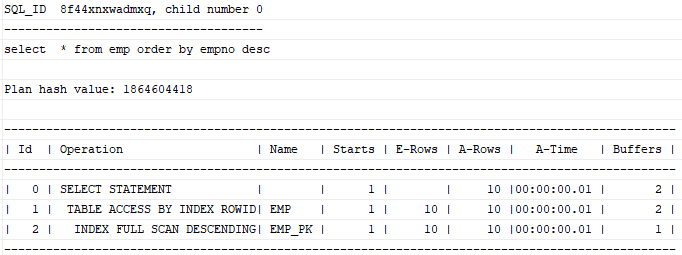
order by절에 인덱스 선두 컬럼에 속하는 컬럼을 넣어주면 옵티마이저가 알아서 인덱스를 거꾸로 읽는 실행계획을 수립한다.
인덱스 종류
B*Tree 인덱스
Unbalanced Index
delete 작업 때문에 불균형 상태에 놓이는 현상이 B*Tree 구조에서는 절대 발생하지 않는다. B*Tree 인덱스의 'B'는 'Balanced'의 약자로서, 인덱스 루트에서 리프 블록까지 어떤 값으로 탐색하더라도 읽는 블록의 수가 같음을 의미한다. 즉, 루트로부터 모든 리프 블록까지의 높이가 동일하다.
Index Skew
불균형은 생길 수 없지만 Index Fragmentation에 의한 Index Skew 또는 Sparse 현상이 생기는 경우는 종종 있고, 이는 인덱스 스캔 효율에 나쁜 영향을 미칠 수 있다.
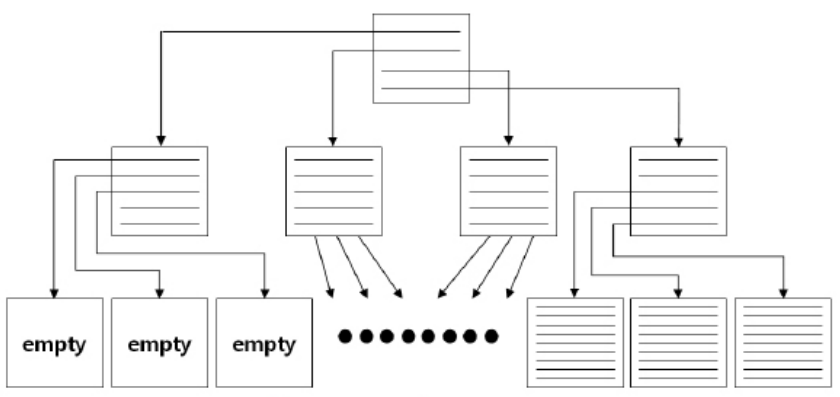
Oracle의 경우, 텅 빈 인덱스 블록은 커밋하는 순간 freelist로 반환되지만 인덱스 구조 상에는 그대로 남는다. 상위 브랜치에서 해당 리프 블록을 가리키는 엔트리가 그대로 남아있어 인덱스 정렬 순서상 그곳에 입력될 새로운 값이 들어오면 언제든 재사용될 수 있다.
새로운 값이 하나라도 입력되기 전 다른 노드에 인덱스 분할이 발생하면 이들 블록이 재사용된다. 이때는 상위 브랜치에서 해당 리프 블록을 가리키는 엔트리가 제거돼 다른 쪽 브랜치의 자식 노드로 이동하고, freelist에서도 제거된다.
freelist : 사용자 요구 시 할당 가능한 free block에 대한 리스트가 관리되며 테이블 및 인덱스에 각각 하나의 리스트로써 운영된다.
레코드가 모두 삭제된 블록은 언제든 재사용 가능하지만, 문제는 다시 채워질 때까지 인덱스 스캔 효율이 낮다는 데에 있다.
Index Sparse
인덱스 블록 전반에 걸쳐 밀도가 떨어지는 현상을 말한다.
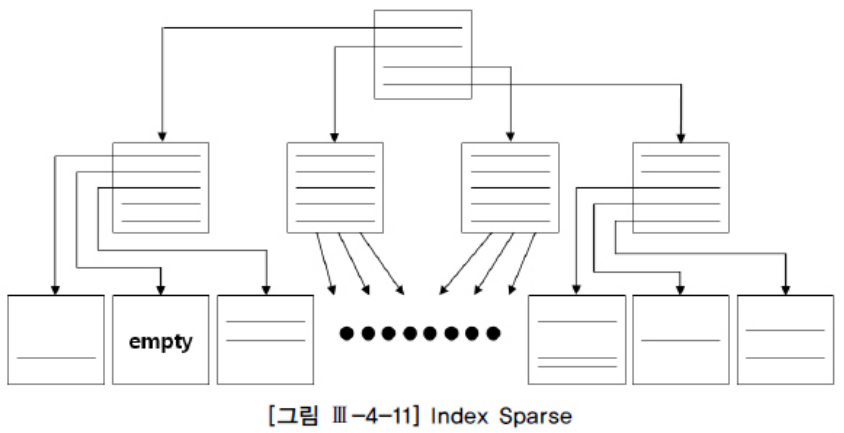
지워진 자리에 인덱스 정렬 순서에 따라 새로운 값이 입력되면 그 공간은 재사용되지만, 대량의 delete 작업이 있고 난 후 한동안 인덱스 스캔 효율이 낮다는 데에 문제가 있다.
Index Skew처럼 블록이 아예 텅 비면 곧바로 freelist로 반환돼 언제든 재사용되지만, Index Sparse는 지워진 자리에 새로운 값이 입력되지 않으면 영영 재사용되지 않을 수도 있다. 총 레코드 건수가 일정한데도 인덱스 공간 사용량이 계속 커지는 것은 대개 이런 현상에 기인한다.
인덱스 재생성
Fragmentation(인덱스를 생성하고 나서 수정,삭제 반복 시 발생)때문에 인덱스 크기가 계속 증가하고 스캔 효율이 나빠지면 인덱스를 재생성하거나 DBMS가 제공하는 명령어를 이용해 빈공간을 제거하는 것이 유용할 수 있지만 일반적으로 인덱스 블록에는 어느 정도 공간을 남겨두는 것이 좋다. 빈 공간을 제거해 인덱스 구조를 슬림화하면 저장 효율이나 스캔 효율에는 좋겠지만 인덱스 분할이 자주 발생해 DML 성능이 나빠질 수 있기 때문이다.
인덱스의 주기적인 재생성 작업을 시행하는 경우
- 인덱스 분할에 의한 경합이 현저히 높을 때
- 자주 사용되는 인덱스 스캔 효율을 높이고자 할 때. 특히 NL Join에서 반복 액세스되는 인덱스 높이가 증가했을 때.
- 대량의 delete 작업을 수행한 이후 다시 레코드가 입력되기까지 오랜 기간이 소요될 때
- 총 레코드 수가 일정한데도 인덱스가 계속 커질 때
비트맵 인덱스
Oracle의 B*Tree 인덱스와 달리 비트맵 인덱스는 NULL도 저장한다.
컬럼의 Distinct Value 개수가 적을 때 비트맵 인덱스를 사용하면 저장 효율이 매우 좋다. B*Tree 인덱스보다 훨씬 적은 용량을 차지하므로 인덱스가 여러 개 필요한 대용량 테이블에 유용하다. 다양한 분석관점을 가진 팩트성 테이블이 주로 여기에 속한다.
팩트성 테이블? : 정규화된 테이블로써 스키마의 중심에 위치하는 테이블로 Dimension 테이블과 연관된 키 구조를 갖는다.
반대로 Distinct Value가 아주 많은 컬럼이면 오히려 B*Tree 인덱스보다 많은 공간을 차지한다. Distinct Value 개수가 적은 컬럼일 때 저장 효율이 좋지만 테이블 Random 액세스 발생 측면에서는 B*Tree 인덱스와 똑같기 때문에 그런 컬럼을 비트맵 인덱스로 검색하면 그다지 좋은 성능을 기대하기 어렵다. 스캔할 인덱스 블록이 줄어드는 정도의 성능 이점만 얻을 수 있고, 따라서 하나의 비트맵 인덱스 단독으로는 쓰임새가 별로 없다.
그 대신, 여러 비트맵 인덱스를 동시에 사용할 수 있는 특징 때문에 대용량 데이터 검색 성능을 향상시키는 데에 효과가 있다. 이러한 장점 때문에 다양한 조건절이 사용되는, 특히 정형화되지 않은 임의 질의가 많은 환경에 적합하다.
다만, 비트맵 인덱스는 Lock에 의한 DML 부하가 심한 것이 단점이다. 레코드 하나만 변경되더라도 해당 비트맵 범위에 속한 모든 레코드에 Lock이 걸린다.
비트맵 인덱스는 읽기 위주의 대용량 DW(특히, OLAP) 환경에 아주 적합하다.
함수기반 인덱스
Oracle이 제공하는 함수기반 인덱스는 컬럼 값 자체가 아닌, 컬럼에 특정 함수를 적용한 값으로 B*Tree 인덱스를 만든다.
ex)
select *
from 주문
where nvl(주문수량, 0) < 100;주문수량 컬럼에 인덱스가 있어도 위처럼 인덱스 컬럼을 가공하면 정상적인 인덱스 사용이 불가능하다.
create index emp_x01 on emp(nvl(주문수량, 0));하지만 조건절과 똑같이 NVL 함수를 씌워 인덱스를 만들면 인덱스 사용이 가능하다.
이 외에도 대소문자를 구분해서 입력 받은 데이터를 대소문자 구분 없이 조회할 때에도 많이 사용한다. 함수기반 인덱스는 데이터 입력, 수정 시 함수를 적용해야 하기 때문에 다소 부하가 있을 수 있으며, 사용된 함수가 사용자 정의 함수일 때는 부하가 더 심하다.
리버스 키 인덱스
일련번호나 주문일시 같은 컬럼에 인덱스를 만들면, 입력되는 값이 순차적으로 증가하기 때문에 가장 오른쪽 리프 블록에만 데이터가 쌓인다. 이런 현상이 발생하는 인덱스를 흔히 'Right Growing(or Right Hand) 인덱스'라고 부르며, 동시 INSERT가 심할 때 인덱스 블록 경합을 일으켜 초당 트랜잭션 처리량을 크게 감소시킨다.
그럴 때 리버스 키 인덱스가 유용할 수 있는데, 이는 말 그대로 입력된 키 값을 거꾸로 변환해서 저장하는 인덱스다.
create index 주문_x01 on 주문(reverse(주문일시));순차적으로 입력되는 값을 거꾸로 변환해서 저장하면 리프 블록 전체에 고르개 분산시킬 수 있다. 하지만, 리버스 키 인덱스는 데이터를 거꾸로 입력하기 때문에 '=' 조건으로만 검색이 가능하다. 즉, 부등호나 between, like같은 범위검색 조건에는 사용할 수 없다.
클러스터 인덱스
클러스터 : 디스크로부터 데이터를 읽어오는 시간을 줄이기 위해서 조인이나 자주 사용되는 테이블의 데이터를 디스크의 같은 위치에 저장시키는 방법
Oracle에는 클러스터 테이블이라는 오브젝트가 있다. 클러스터 테이블에는 인덱스 클러스터와 해시 클러스터가 있다.
인덱스 클러스터 테이블은 클러스터 키값이 같은 레코드가 한 블록에 모이도록 저장하는 구조를 사용한다. 한 블록에 모두 담을 수 없을 때는 새로운 블록을 할당해 클러스터 체인으로 연결한다.
심지어 여러 테이블 레코드가 물리적으로 같은 블록에 저장되도록 클러스터를 할당할 수도 있다.(다중 테이블 인덱스 클러스터) 여러 테이블을 서로 조인된 상태로 저장해두는 것인데, 일반적으로는 하나의 데이터 블록이 여러 테이블에 의해 공유될 수 없다고 생각하자.
create cluster c_deptno# (deptno number(2)) index;
create index i_deptno# on cluster c_deptno#;
create table emp cluster c_deptno# (deptno) as select * from emp;클러스터 인덱스가 없으면 클러스터화된 데이터에 액세스할 수 없다.
클러스터 인덱스도 일반적인 B*Tree 인덱스 구조를 사용하지만, 해당 키 값을 저장하는 첫 번째 데이터 블록만 가리킨다는 점에서 다르다. 클러스터 인덱스의 키 값은 항상 Unique하며, 테이블 레코드와 1:M 관계를 갖는다.
(일반 테이블에 생서한 인덱스 레코드는 테이블 레코드와 1:1 관계이다.)
이러한 구조적 특성 때문에 클러스터 인덱스를 스캔하면서 값을 찾을 때는 Random 액세스가 값 하나당 한 번씩만 발생한다. (클러스터 체인을 스캔하면서 발생하는 Random 액세스 제외)
클러스터에 도달해서는 Sequential 방식으로 스캔하기 때문에 넓은 범위를 검색할 때 유리하며 새로운 값이 자주 입력되거나 수정이 자주 발생하는 컬럼은 클러스터 키로 선정하지 않는 것이 좋다.
조회 성능은 높지만 데이터 저장, 수정, 삭제 또는 한 테이블 전체 Scan의 성능은 낮다.
클러스터형 인덱스/IOT
1) 클러스터형 인덱스/IOT 구조
클러스터형 인덱스도 구조적으로 B*Tree 인덱스와 같은 형태지만 별도의 테이블을 생성하지 않고 모든 행 데이터를 인덱스 리프 페이지에 저장한다는 점이다. 인덱스를 이용한 테이블 액세스가 고비용 구조라고 하니, 랜덤 액세스가 아예 발생하지 않도록 테이블을 인덱스 구조로 생성하는 방법이다.
create table index_org_t ( a number, b varchar(10), constraint index_org_t_pk primary key(a) )
organization index;일반적인 힙 구조 테이블에 데이터를 삽입할 때는 정해진 순서 없이 Random 방식으로 이루어지는 반면, 클러스터형 인덱스는 정렬 상태를 유지하며 데이터를 삽입한다. 따라서 클러스터형 인덱스는 테이블마다 단 하나만 생성할 수 있다.
IOT는 인위적으로 클러스터링 팩터를 좋게 만드는 방법 중 하나다. 같은 값을 가진 레코드들이 100% 정렬된 상태로 모여 있으므로 랜덤 액세스가 아닌 시퀀셜 방식으로 데이터를 액세스하므로 넓은 범위를 액세스할 때 유리다. 또한, PK 인덱스를 위한 별도의 세그먼트를 생성하지 않아도 된다. 하지만 데이터 입력시 느리며 인덱스 분할 발생량 차이로 인한 성능차이가 크다는 단점 또한 있으며 Direct Path Insert가 작동하지 않는다.
(참고로, Oracle에서는 PK에서만 생성할 수 있다.)
2) 클러스터형 인덱스 / IOT 활용
클러스터형 인덱스를 사용하는 경우
- 넓은 범위를 주로 검색하는 테이블
- 크기가 작고 NL Join으로 반복 룩업하는 테이블
- 컬럼 수가 적고 로우 수가 많은 테이블
- 데이터 입력과 조회 패턴이 서로 다른 테이블
3) 2차 인덱스로부터 클러스터형 인덱스/IOT 참조하는 방식
클러스터형 인덱스를 가리키는 2차 인덱스를 SQL Server에서는 비클러스터형 인덱스, Oracle에서는 Secondary Index라고 부른다. SQL Server 6.5 이전에는 비클러스터형 인덱스가 클러스터형 인덱스 레코드를 직접 가리키는 rowid를 갖도록 설계하였지만, 인덱스 분할로 인해 클러스터형 인덱스 레코드 위치가 변경될 때마다 비클러스터형 인덱스가 갖는 rowid 정보를 모두 갱신해 주어야 한다는 문제점 때문에 7.0 버전부터는 비클러스터형 인덱스가 rowid 대신 클러스터형 인덱스의 키 값을 갖도록 구조를 변경하였다.
그런데 DML부하가 줄어든 대신, 비클러스터형 인덱스에서 읽히는 레코드마다 건건이 클러스터형 인덱스 수직 탐색을 반복하기 때문에 이전보다 더 많은 I/O가 발생하는 부작용을 안게 되었다.
Oracle은 IOT를 개발하면서 위에서 말한 두 가지 액세스 방식을 모두 사용할 수 있도록 설계하였다. IOT 레코드의 위치는 영구적이지 않기 때문에 Oracle은 Secondary 인덱스로부터 IOT 레코드를 가리킬 때 물리적 주소 대신 Logical Rowid를 사용한다.
Logical Rowid = PK + Physical Guess
Physical Guess는 Secondary 인덱스를 최초 생성하거나 재생성한 시점에 IOT 레코드가 위치했던 데이터 블록 주소(DBA)다. 인덱스 분할에 의해 IOT 레코드가 다른 블록으로 이동하더라도 Secondary 인덱스에 저장된 physical guess 값은 갱신되지 않는다. physical guess가 가리키는 블록을 찾아갔다가 찾는 레코드가 없으면 PK로 다시 탐색하는 식이다.
