Storage 저장소
key를 통해서 key 안에 있는 value를 가져오기
기본적으로 value가 들어가면 url이 생성된다.
NAS :
회사안의 파일 공유 서비스 Azure files가 이 기능을 담당
Web-WAS-NAS 구조로 파일을 공유하게 됨
Database
로컬환경에서 비용이 커질 수 있음
MySQL : 돌고래
MariaDB : 바다사자,완전 오픈소스
PostgreSQL : 코끼리
SQL
가이드
https://www.mysqltutorial.org/
SELECT, FROM, WHERE, GROUP BY, HAVING, ORDER BY 를 주로 씀
SELECT lastname, firstname, jobtitle FROM employees
SELECT contractLastname, contractFirstnam
FROM customerss 거나 FROM classimodels.customers
ORDER BY(정렬) contactLastname, contactFistName
역순 DESC 붙이면 됨, 정순(기본값)은 ASC
ex) ORDER BY contactLastname DESC, contactFIstName ASC
SELECT*FROM orderdetails
SELECT orderNUMber. orderLienumber, quantityOrderedpriceEach
FROM orderdeTails
ORDER BY quantitiyOrderedpriceEach
SELECT orderNUMber. orderLienumber, quantityOrdered*priceEach AS subTotal
FROM orderdeTails
ORDER BY subTotal
SELECT firstName, lastName, reportstTo
FROM employees
WHERE(조건문)
SELECT
lastName,
firstName,
jobtitle,
officeCode
FROM
employeesWHERE
jobtitle = 'Sales Rep' AND officeCode = 1 (조건 둘 다 만족)WHERE firstName BETWEEN 1 AND 3 (1~3의 fistName만 적용)WHERE lastName LIKE '%son' (son으로 끝나는 사람)
%so% : so가 들어간 단어 전부 찾아줌WHERE officeCode = 1 OR officCdoe = 3
= officeCode IN (1,3) (같은 결과 도출)Query 분석 및 해석 -> 데이터베이스 상태 확인 -> Query 작성 플랜을 짜는 순서로 이루어지기 때문에 같은 결과가 도출할 수 있다.
쿼리를 준비할때 index를 잘 짤 필요성이 있다.
Stored Procedures 일련의 순서를 미리 저장해둠으로 속도를 높임 But 나중으로 갈수록 속도가 느려짐.
현재 데이터베이스상태에 맞춰서 만들어지기 때문에 데이터베이스가 계속변화하면서 느려지게된다. 이러한 단점떄문에 잘 안쓰임
SELECT
lastName,
firstName,
reportsTo
FROM
employees
where
reportsTO IS NULLIS 명령어로만 NULL 값을 찾을 수 있음
WHERE
jobtitle <> 'Sales REP'제외하고 찾는 코드
SELECT
DISTINT lastName
FROM
employeesDISTINT 중복을 제거 하는 명령어
SELECT
e.firstNAme,
e.lsastName
FROM
employees e
ORDER BY
e.fistName employees를 e로 지정하겠다.
AS를 생략할 수 있음 'employees as e'
Group by는??
예를 들어cutomers와 orders를 연결하는것이 customerNumber
고리를 이용해서 두개의 테이블에 있는 내용을 하나로 합치는 것
SELECT
constomerName
COUNT(*)
FROM
customers c
COUNT(*) as 'orderCount'
INNER JOIN
order o ON c.customerNumber = o.customerNumber
GROUP BY
customerName
ORDER BY orderCount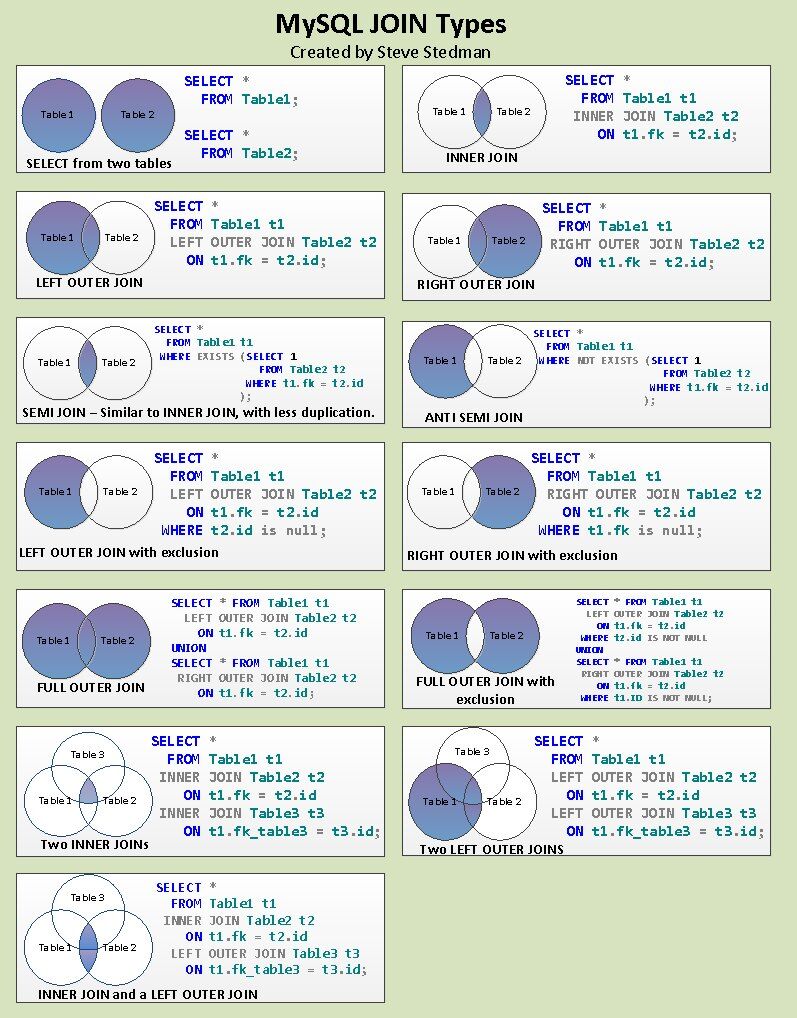
semi : select해서 나온 결과를 가지고 다시 select 하는것 = 내부적으로 2번 query하기땜에 권장하는 방법은 아니다.
SELECT
orderNUmber,
SUM(quantityOrdered),
SUM(priceEach * quantityOrdered)
FROM
orderdetails
GROUP BY orderNumber
HAVING
total > 1000 AND itemsCOunt > 600
그룹by로 집계한것에 조건을 걸고 싶을때 where 절을 쓸수 없음
= WHERE로 걸러진 내용을 그룹화하기 때문에
= HAVING을 써야 함 + AND, OR 등
INDEX
전체데이터에 대해 색인을 만들어 두는 것
TIP
Schema : 데이터를 닮는 틀 같은 개념
한 서버에 여러개의 데이터베이스가 있다.
데이터베이스 안에는 여러개의 테이블들이 있다.
테이블 사이에는 관계가 있다. Relation
RDB : Rerational DB
RDBMS : RDB management System
데이터베이스에서 PK, FK, INDEX, VIEW 가 중요하다.
view
하나의 테이블을 여러사람이 보고있으면, 사람마다 필요한 부분이 다름
하지만 모든사람에게 모든것을 보여주는 불필요한 작업을 수행하거나 보안적 위험성 발생
view 1,2,3을 만들어 놓고 테이블에 연결해놓는다. 마치 안경처럼 보이는 부분을 각자 다르게 설정
쿼리를 이용해서 view를 설정 할 수 있다.
