Apache Flume이란?
Apache Flume은 오픈소스 프로젝트로 개발된 로그 데이터를 수집 기술이다. 여러 서버에서 생산된 대용량 로그 데이터를 효과적으로 수집하여, HDFS과 같은 원격 목적지에 데이터를 전송하는 기능을 제공한다.
구조가 단순하고 유연하여 다양한 유형의 스트리밍 데이터 플로우(Streaming Data Flow) 아키텍처를 구성할 수 있다.
-
구성요소
-
Source (수집담당): 다양한 원천 데이터를 수집하기 위해 Avro, Thrift, JMS, Spool Dir, Kafka 등 여러 주요 컴포넌트를 제공하며 수집한 데이터를 Channel로 전달한다.
데이터가 발생하는 소스로부터 (로그)데이터 수집 담당
-
Channel (소스와 싱크의 중간다리): Source와 Sink를 연결하며, 데이터를 버퍼링하는 컴포넌트로 메모리, 파일, 데이터베이스를 채널의 저장소로 활용한다.
Source와 Sink 사이의 Queue
-
Sink (적재담당): 수집한 데이터를 Channel로부터 전달받아 최종 목적지에 저장시켜준다.
HDFS, Hive, Logger, Avro, ElasticSearch, Thrift 등을 제공수집한 데이터를 외부로 보내는 역할
-
Interceptor (수집데이터 전처리): Source와 Channel사이에서 데이터 필터링 및 가공하는 컴포넌트로서 필요시 사용자가 직접 정의한 interceptor를 사용할 수 있다.
-
Agent (플럼구성요소의 집합): Source -> (Interceptor) -> Channel -> Sink로 구성된 일련의 과정들을 한 묶음으로 플럼의 에이전트라고 한다.
-
Flow
-
Multi-Agent
다른 Agent에게 데이터를 전달은 Avro를 이용하여 여러 단계를 거치는 형태를 구성 할 수 있다.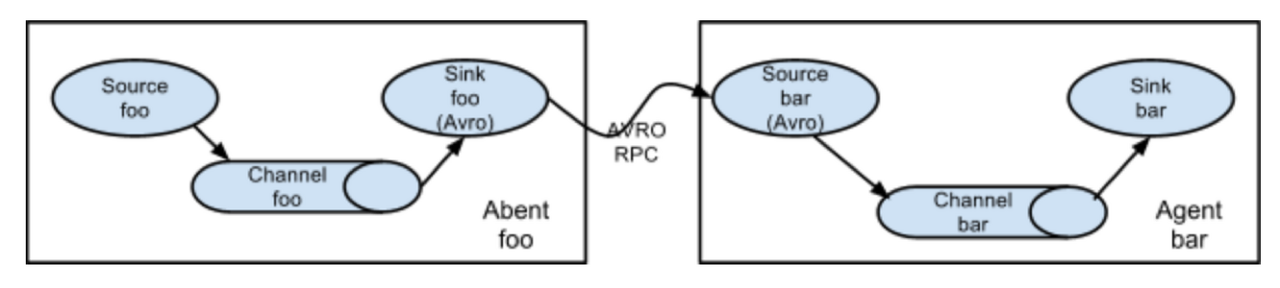
-
Consolidation (Fan-in)
보통 로그데이터를 수집할 때, 하나의 웹 서버에서 수집 되진 않는다. 서비스가 클 수록 수십대의 웹 서버에서 로그가 수집되어진다.각 웹 서버에는 Flume Agent가 있어서 수집을 돕고, 하나의 Agent에서 이를 통합 (Consolidates)한다. 마지막에 Sink를 통해 어떤 레파지토리에 데이터를 저장할지 정해준다.
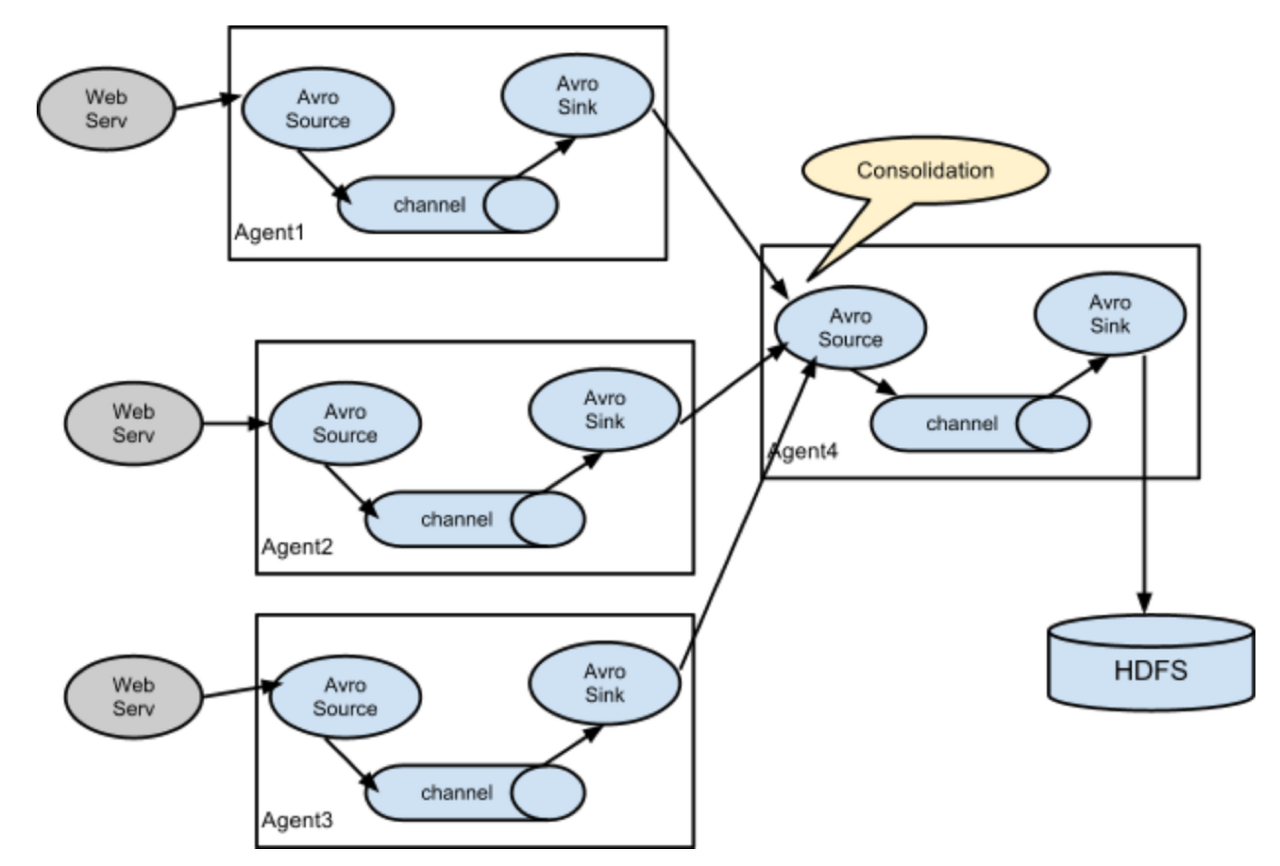
-
Multiplexing the Flow
flume은 하나 이상의 목적지에 데이터를 저장할 수 있게 하기 위해, 다중 이벤트 flow를 지원한다. 멀티플렉서 정의를 하면 channel-sink 가 복사 되어 원하는 레파지토리로 데이터를 전송할 수 있다.다양한 레파지토리로 연결 되는 것 뿐만 아니라 아래에서 설명한 Multi-Agent도 가능하다.
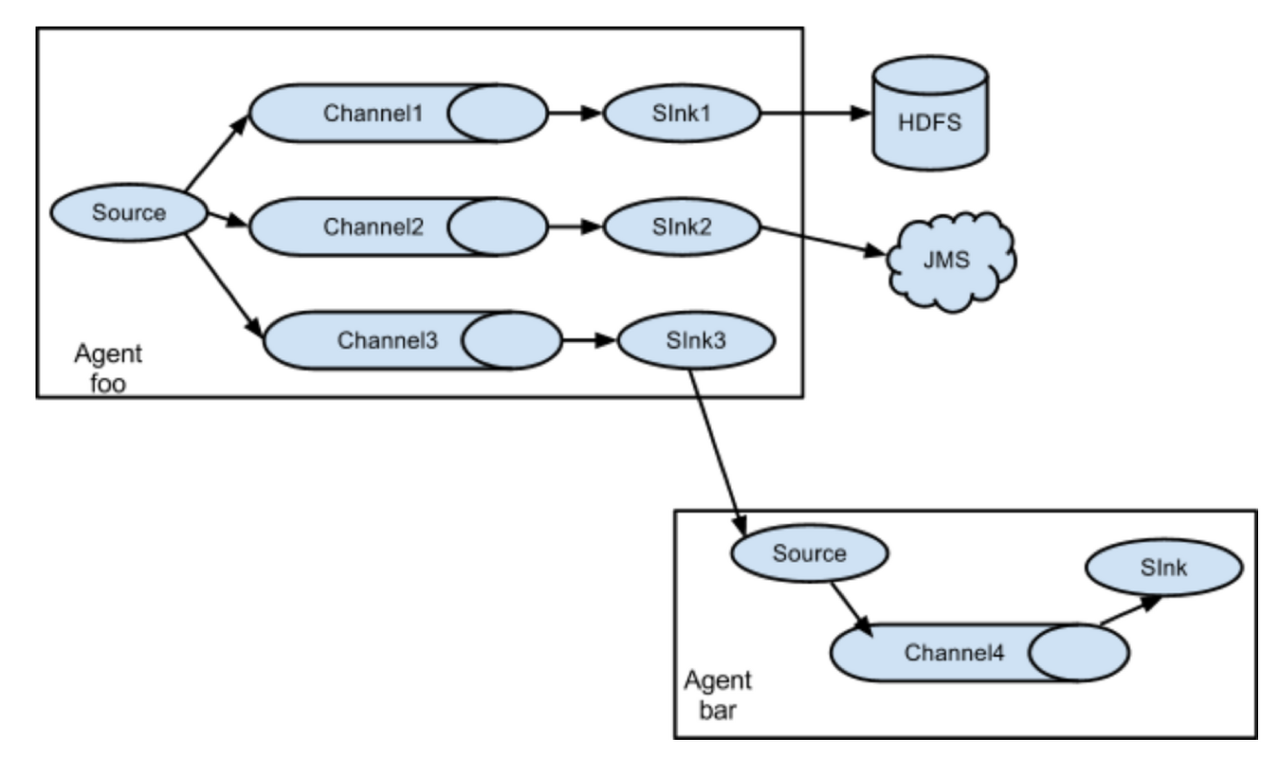
Kafka vs Flume
둘다 빠르게 생성되는 '빅'데이터(대용량 데이터)를 처리하기에 적합하지만, 태생 자체의 목적이 약간 다르다.
- Flume은 그냥 마구마구 생성되는 로그데이터를 하둡에 생각없이 때려박고 싶을때 쓰면 좋다.
- Kafka는 데이터 전송에 있어서 high-신뢰성,확장성이 장점이므로, 중요한 '빅'데이터(손실이 되면 안되는!!) 처리에 좋다.
Reference
