2. SQL(Structured Query Language)
2.1 SQL 의미와 종류
- 구조화된 질의 언어
- 데이터베이스가 이해할 수 있도록
특정 문법에 맞춰서 질의하는 것
- 데이터베이스가 이해할 수 있도록
ex) 한국의 육하원칙(누가 , 무엇을 ..)
ex) 영어는 주어 , 동사 , 목적어 ..
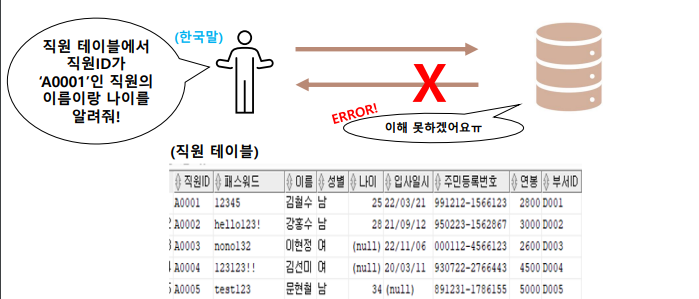
- 인간의 언어로 명령하면 컴퓨터는 이해할 수 없다. 따라서 컴퓨터가 이해할 수 있도록 SQL 문법을 지켜서 명령해야 한다.
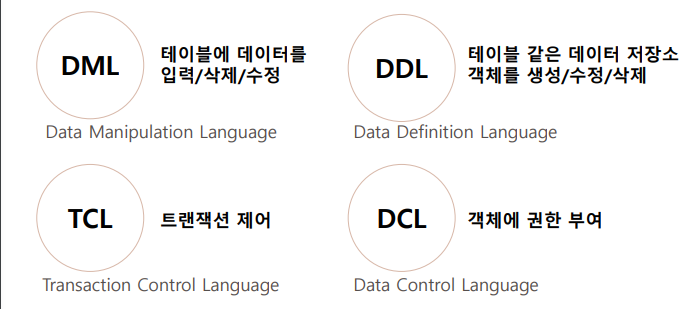
- DML(Data Manipulation Language) :
데이터베이스 내의 데이터를 조작하는 데 사용되는 SQL(Structured Query Language)의 하위 집합
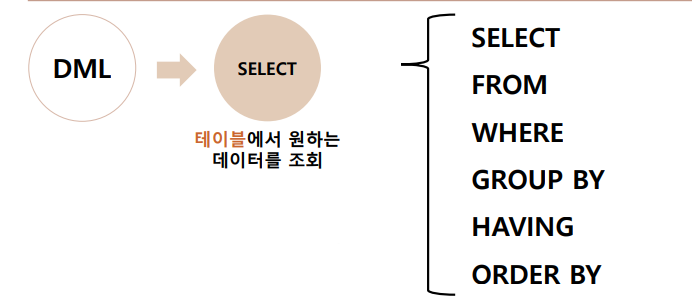
2.2 SQL 문법 실행 순서

- SQL 문법의 표기 순서와 실행되는 순서!
> 표기순서 SELECT
FROM
WHERE
GROUP BY
HAVING
ORDER BY
> 실행 순서 FROM : 데이터를 가져올 테이블'에서(FROM)'
WHERE : 원하는 튜플'만'(조건) 가져오도록 필터링한다.
GROUP BY : 특정 컬럼 기준으로 '그룹화'(중복 컬럼을 묶어 압축시킨다.)
HAVING : 그룹화된 데이터를 '필터링' (추가적으로 조건을 걸어줄 수 있다.(집계함수 사용가능))
SELECT : '출력하고 싶은 컬럼'만 '작성' (출력하려는 컬럼을 '고른다!')
ORDER BY : 특정 컬럼을 기준으로 '정렬'한다
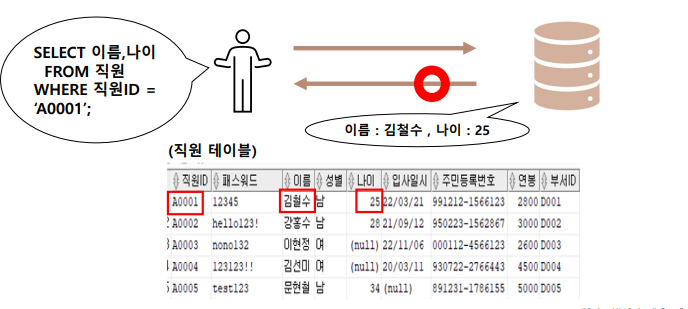
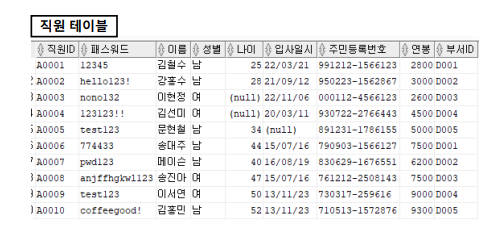
- 테이블에서(FROM) 데이터를 조회
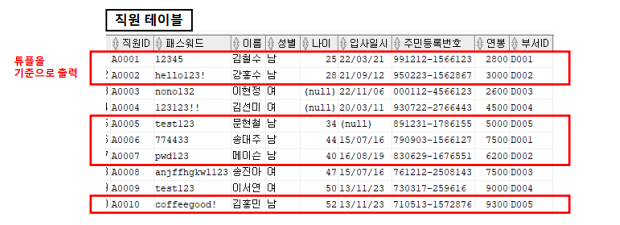
- 직원 테이블의 10개 튜플 중에서 성별 컬럼을 기준으로 '남'인 튜플만 출력
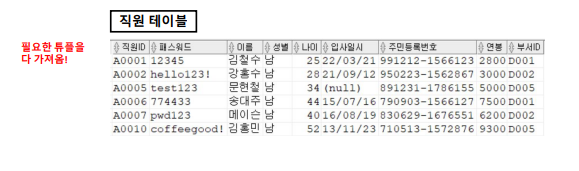
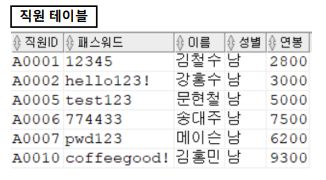
↓- 출력되는 튜플 정보에서 직원ID , 패스워드 , 이름 , 성별 , 연봉 정보만 출력
→ 컬럼단위로 쪼개기!
↓
2.3 *(Asterisk)와 DISTINCT, AS
*(Asterisk) : 모든 컬럼 정보를 출력하는 키워드
( 모든 컬럼을 직접 입력해도 같은 결과를 출력한다. )
SELECT 직원ID, 패스워드, 이름, 성별, 나이, 입사일시, 주민등록번호, 연봉, 부서ID
FROM 직원 ;
-- 같은 결과 출력
SELECT *
FROM 직원 ;DISTINCT : 출력할 컬럼 정보에서 중복 값을 없애 주는 키워드
[ 문법 ] SELECT DISTINCT 성별
FROM 직원 ;
--직원 테이블에서 성별 정보를 중복 없이 조회
AS (ALIAS) : 별칭, 통칭
- AS 는 SELECT 부분에서 출력하려는 컬럼에 대해 새로운 별칭(ALIAS)을 부여 한다.
- SELECT 이외에서도 사용 가능!
SELECT 직원ID AS EMP_ID
FROM 직원 ;
-- 직원ID 컬럼이 새로운 별칭인 EMP_ID로 표기된다.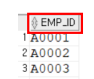
AS (ALIAS) 사용 시 주의사항
SELECT 직원ID AS EMP ID , -- 별칭 안에 띄어쓰기 불가
패스워드 AS 100PASSWD , -- 숫자 , 특수문자 시작 불가 (영문자 가능!)
이름 AS !!! , -- 특수문자는 $,_,#만 가능
연봉 AS SELECT -- 예약어 불가
부서ID DEPT_ID -- AS 대신에 ‘공백’ 가능 ( 권장X )
FROM 직원 ;2.4 NULL 함수
NULL: 값이 아직 정해지지 않은 공란, 빈 칸
NULL값은 산술, 비교 연산이 불가능하다. 이런 특징을 이용하여 산술 및 비교를 하는 문제가 다수 출제되어 알아두어야 하는 개념.
- 왜 NULL이라는 개념을 사용할까?
- 아직 정해지지 않은 값을 표현 가능하다.
- 사각형모양을 가지는 테이블의 특성을 지키기 위해 NULL을 사용한다.
값을 넣지 않아 칸이 없을 수는 없기 때문!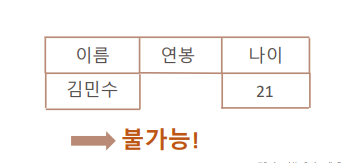
NULL 연산은 IS NULL / IS NOT NULL 로 출력 가능
-- NOT: 부정연산자(IS NOT NULL등의 특수 연산 외에는 권장x)
SELECT *
FROM 직원
WHERE 나이 IS NULL ;
-- IS NULL(NULL값을 찾거나), IS NOT NULL(NULL값이 아닌 것을 찾기)2.4.1 NVL(data1, data2) :
data1에 NULL 값이 들어오면 data2로 교체, NULL이 아니면 그대로 출력함.2.4.2 NVL2( data1 , data2 , data3 ) :
data1에 NULL 값이 들어오면 data3를 출력, NULL이 아니면 data2을 출력2.4.3 DECODE( data1 , data2 , data3 , data4 ) :
data1 과 data2 가 동일하면 data3을 출력, 그렇지 않으면 data4를 출력
ex) SELECT 직원ID , 나이 , DECODE(나이 , NULL , 0 , 나이) FROM 직원 ;
-- 나이가 NULL일 때 data3인 0으로 대체
-- 나이가 NULL이 아닐때 data4인 나이 값이 그대로 출력2.4.4 COALESCE( data1 , data2 , data3 , … , dataN ) :
앞에서부터 data를 확인하다가 NULL이 아닌 값이 나오면 출력
ex) SELECT 직원ID , 나이 , COALESCE(나이 , null , 0) FROM 직원 ; 2.5 자료형과 함수
-
자료형(Data Type) : 데이터를 저장하는 형식
데이터베이스에서는 문자형, 숫자형, 날짜형 자료형을 사용
SELECT문에서는 간단한 연산과 내장형 함수 사용이 가능하다.
ex) SELECT 직원ID , 연봉 , 연봉 + 1000
FROM 직원 ;2.5.1 내장형 함수(Built-in Function)
- 미리 만들어 선언해둔 함수
→ 함수 이름을 호출해서 바로 사용 가능하게 내부에서 설계해둔 함수
문자형 함수 : LOWER , UPPER , SUBSTR , TRIM , REPLACE
숫자형 함수 : MOD , ROUND , CEIL , FLOOR , TRUNC , ABS
날짜형 함수 : SYSDATE , LAST_DAY , ADD_MONTHS
문자형 함수
LOWER(str) : str의 문자 데이터를 대문자에서 소문자로 대체
UPPER(str) : str의 문자 데이터를 소문자에서 대문자로 대체
SUBSTR(str , x, y ) : str의 문자 데이터를 (왼쪽 기준)x자리부터 y개만큼 절단
TRIM(str) : str의 문자 데이터에서 양 끝 공백 제거(데이터 안에 있는 공백은 지우지 못함)
REPLACE(str, ‘x’, ‘y’) : str의 문자 데이터에서 x라는 문자를 y로 대체숫자형 함수
MOD(int1 , int2) : int1을 int2로 나눈 나머지를 숫자형으로 출력
※ROUND(int1 , int2)※ : int1을 반올림하여 소수점 int2자리까지 출력
CEIL(int) : int보다 크거나 같은 최소 정수를 출력
FLOOR(int) : int보다 작거나 같은 최대 정수를 출력
TRUNC(int1, int2) : int1을 소수점 int2자리까지 잘라서 버린 후 출력
ABS(int) : int의 절대값 출력날짜형 함수
※SYSDATE※ : 입력 시 현재 시간을 날짜형으로 출력
※보통 컬럼은 데이터가 저장된 시간을 많이 사용하기 때문에 SYSDATE는 꼭 기억하자!
LAST_DAY(date) : date의 날짜형 값의 해당 월 마지막 날짜를 출력
ADD_MONTHS(date , int) : date의 날짜형 값에서 int개월 수만큼 더해서 출력2.5.2 형변환 함수
- 특정 자료형 값으로 변경해주는 함수
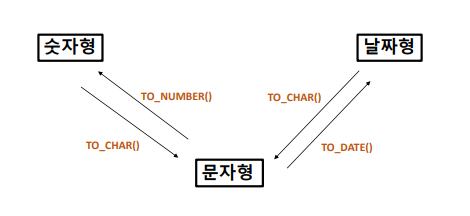
자료형(Data Type)이 일치하지 않는 값끼리의 연산
- 연산하기 전에 내부적으로 형변환 발생한다.
문자형인 ‘100’을 숫자형으로 형변환 하고 자동 연산함.
형변환 우선순위 : 날짜형 > 숫자형 > 문자형
(우선순위가 더 높은 자료형을 기준으로 바뀜!)
SELECT '100' + 1000
FROM DUAL;
→
SELECT TO_NUMBER ('100’) + 1000
FROM DUAL;
-- 더 낮은 우선순위의 문자형이 숫자형으로 바뀐 후 연산된다.