What is Big Data?
Big Data concepts and Terminology
- clustered computing: collection of resources of multiple machines
- parallel computingL simultaneous computation
- distributed computing: collection of nodes (networked computers) that run in parallel
Big Data processing systems
- Hadoop/MapReduce: salable and fault tolerant framework written in Java
- open source
- batch processing
- Apache Spark: general purpose and lightning fast cluster computing system
- open source
- both batch and real-time data processing
Features of Apache Spark framework
- distributed cluster computing framework
- efficient in-memory computations for large data sets
- lightning fast data processing framework
- provides support for Java, Scala, Python, R and SQL
Spark modes of deployment
- Local mode: Single machine (ex. laptop)
- local model convenient for testing, debugging and demonstration
- cluster mode: set of pre-defined machines
- good for production
- workflow: local -> clusters
- no code change necessary
PySpark: Spark with Python

What is Spark shell?
- interactive environment for running Spark jobs
- Helpful for fast interactive prototyping
- Spark's shells allow interacting with data on disk or in memory
- Three different Spark shells:
- Spark-shell for Scala
- PySpark-shell for Python
- SparkR for R
Understanding SparkContext
-
PySpark has a default SparkContext called
sc -
Loading data in PySpark:
parallelize(),textFile()
rdd = sc.parallelize([1,2,3,4,5])
rdd2 = sc.textFile("text.txt")Review of functional programming in Python
-
Lambda functions are anonymous function in Python
-
very powerful and used in Python. Quite efficient with
map()andfilter() -
Lambda functions create functions to be called later similar to
def -
it returns the functions without any name (i.e anonymous)
-
lambda x: x*2 -
filter(function, list) -
map(function, list)
Abstracting Data with RDDs
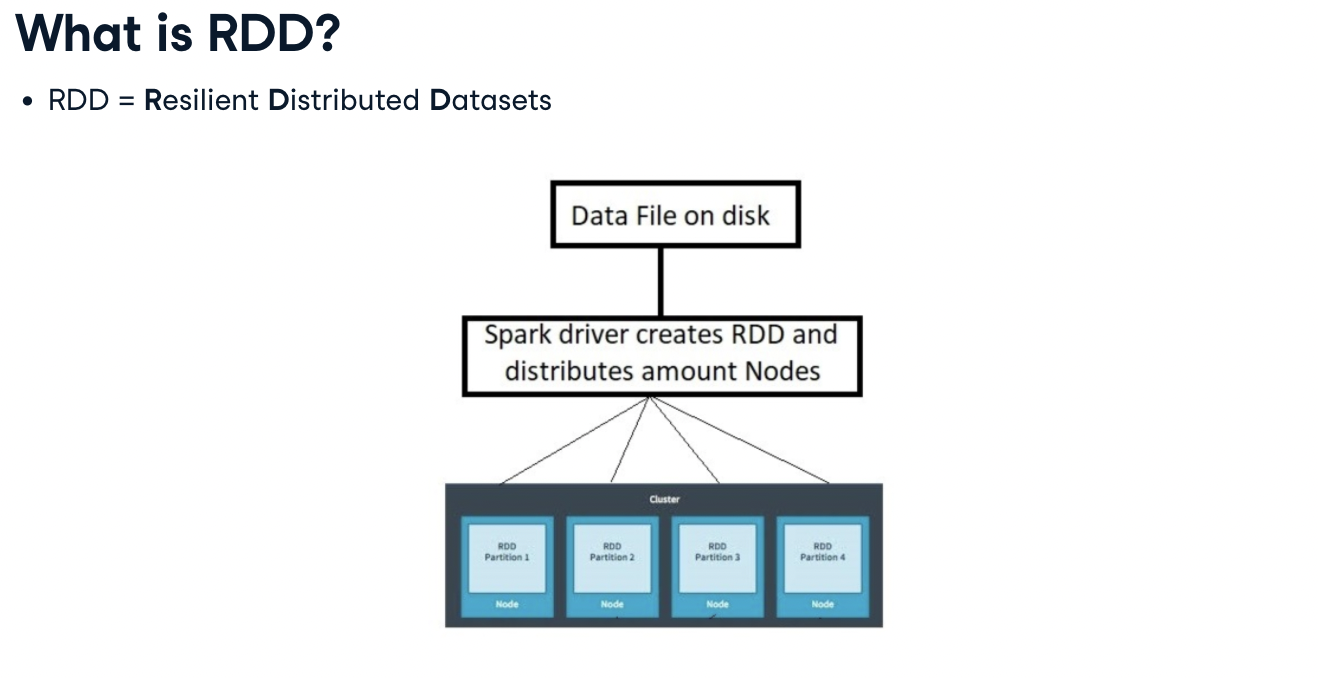
What is RDD?
-
분산 변경 불가능한 객체의 모음
-
Spark는 map reduce 작업을 RDD 개념을 통해서 사용함
-
map reduce는 데이터의 공유가 느리다는 단점이 있다.
- map reduce: 계산된 데이터를 재사용하기 위해 파일 스토리지 시스템에 저장하고 읽는 구조로 되어있음
- 복제, 직렬화, 디스크 io때문에 데이터 공유가 느려지게 됨
- 예를 들어, hadoop 시스템의 대부분은 hdfs 읽기 쓰기 작업을 수행하는데 90퍼센트 이상을 사용하고 있다고 함
ref: https://bomwo.cc/posts/spark-rdd/
ref: https://bcho.tistory.com/1027
- RDD는 여러 분산 노드에 걸쳐서 저장되는 변경이 불가능한 데이터의 집합.
- 각각의 RDD는 여러개의 파티션으로 분리가 된다. - 서로 다른 노드에서 분리되어 실행됨
- 스파크 내에 저장된 데이터를 RDD라고 하고, 변경이 불가능하다. 변경을 하려면 새로운 데이터 셋을 생성해야 한다.
- RDD에는 Transformation과 Action 오퍼레이션을 지원함.
- Transformation: 기존의 RDD 데이터를 변경하여 새로운 RDD 데이터를 생성해내는 것. 예를 들어 filter와 같이 특정 데이터만 뽑아내거나 map함수로 데이터를 분산 배치할 수 있음
- Action: RDD 값을 기반으로 무언가를 계산해서 결과를 생성해 내는 것으로 count()가 예시
- RDD의 데이터 로딩 방식은 lazy 로딩 컨셉을 사용함.
- sc.textFile("file") 을 로딩하더라도 실제로 로딩이 되는 게 아니라, action을 이용할 때 그때만 파일이 로딩되어 메모리에 올라감.
Decomposing RDDs
- resilient distributed datasets
- resilient: ability to withstand failures
- distributed: spanning across multiple machines
- datasets: collection of partitioned data e.g.Arrays, Tables, Tuples etc.,
Creating RDDs. How to do it?
- parallelizing an existing collection of objects
- External datasets:
- files in HDFS
- Objects in Amazon S3 bucket
- lines in a text file
parallelize()for creating RDDs from python lists
numRDD = sc.parallelize([1,2,3,4])
helloRDD = sc.parallelize("Hello")- From external datasets :
testFile()
fileRDD = sc.testFile("README.md")Understanding Partitioning in PySpark
- A partition is a logical division of a large distributed data set
parallelize(),textFile()method
numRDD = sc.parallelize(range(10), minParitions = 6)
fileRDD = sc.textFile("README.md", minParitions = 6)Basic RDD Transformations and Actions
flatMap() Transformation
- flatMap() transformation returns multiple values for each element in the original RDD
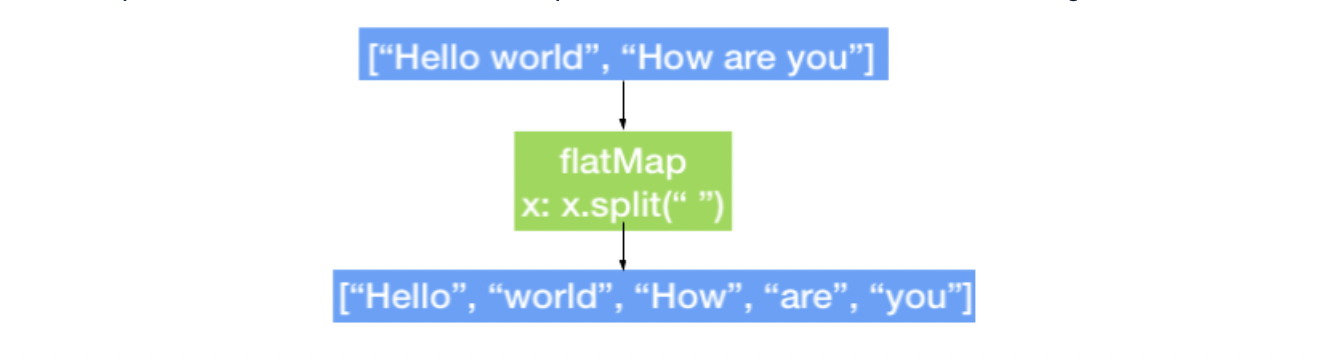
RDD = sc.parallelize(["hello world", "how are you"])
RDD_flatmap = RDD.flatMap(lambda x: x.split(" "))union() Transformation
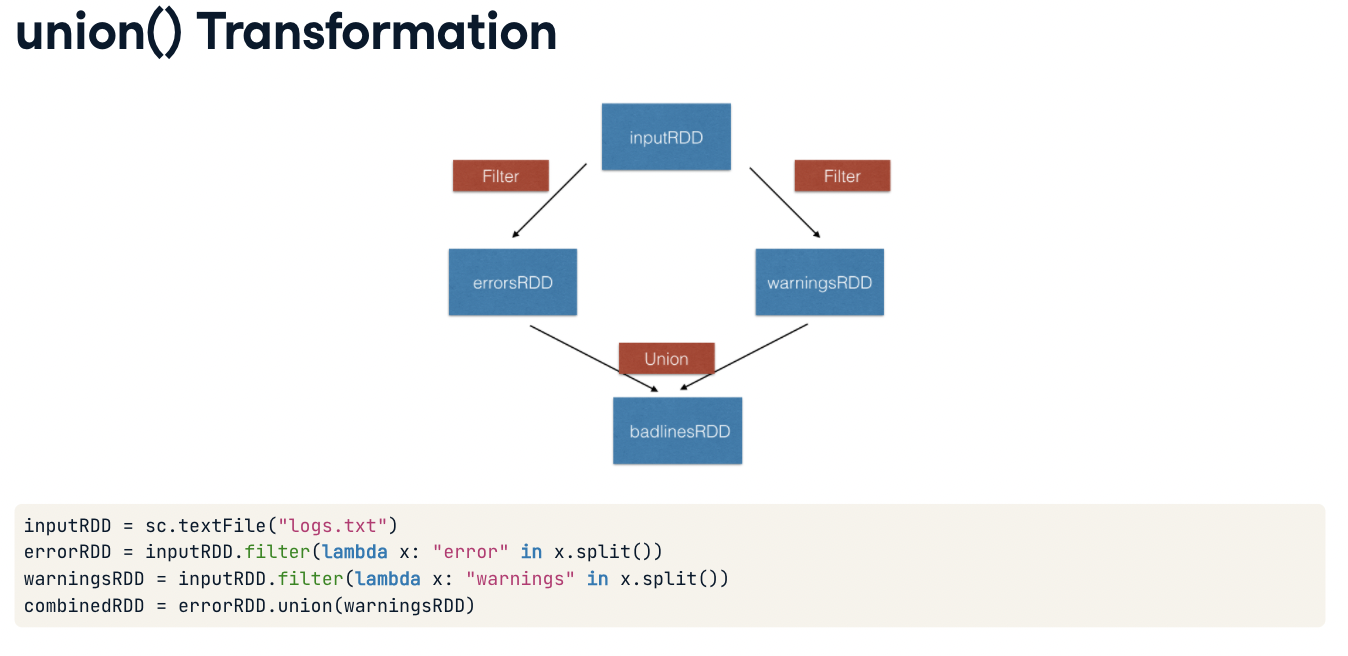
pair RDDs in PySpark

reduceByKey() transformation

groupByKey() transformation

SQLs and DataFrames
PySpark DataFrame
- for Structured and Semi-structured data
- immutable distributed collection of data with named cols
- Dataframe API is available in Python, R, Scala and Java
- support both SQL queries or expression methods(ex.
df.select())

- create a DF from reading
- csv: spark.read_csv("data", header=Boolean, inferSchema=bool)
- json: spark.read_json("data", header=Boolean, inferSchema=bool)
- txt: spark.read_txt("data", header=Boolean, inferSchema=bool)
Operating on DF in PySpark
- select()
- show()
- filter()
- groupby(), count(), orderby()
- dropDuplicates()
- printSchema(), describe()
Interacting with DF using PySpark SQL
df = spark.sql("SQL QUERIES")
df.collect()query = '''SELECT ~ '''
df = spark.sql(query)
df.show(5)PySpark MLlib


from pyspark.mllib.recommendation import ALS
from pyspark.mllib.classification import LogisticRegressionWithBFGSdocs: https://spark.apache.org/docs/2.0.0/api/python/pyspark.mllib.html

분명히 처음엔 데린이었는데,, 이제 개린이인가..