refs: Introduction to the Data Engineering from DATACAMP
INTRO
DE gather data from diff sources
Definition of the job
An engineer that develops, constructs, tests and maintains architectures such as DB and large-scale ones
Tools of the DE
DB
- Hold large amounts of data
- support application
- for DS
processing
- clean data
- aggregate data
- join data
Scheduling
- plan jobs with specific intervals
- resolve dependency requirements of data
Existing tools
DB : MySQL
processing : Spark
Scheduling : Apache Airflow
Data processing in the cloud
- covers electrical and maintenance costs
- peaks vs. quiet moments
reliability is required
- replicate
Tools for DE
DB
-
A usually large collection of data organized especially for rapid search and retrieval
-
Database: very organized, easy to search
Storage: less organized, texts, images, etc. -
Structed/Unstructed/Semi-structured -
SQL: Tables, Relational DB, schema
NoSQL: Non-relational (Not only SQL LOL) , K-V, Structed & Unstructured
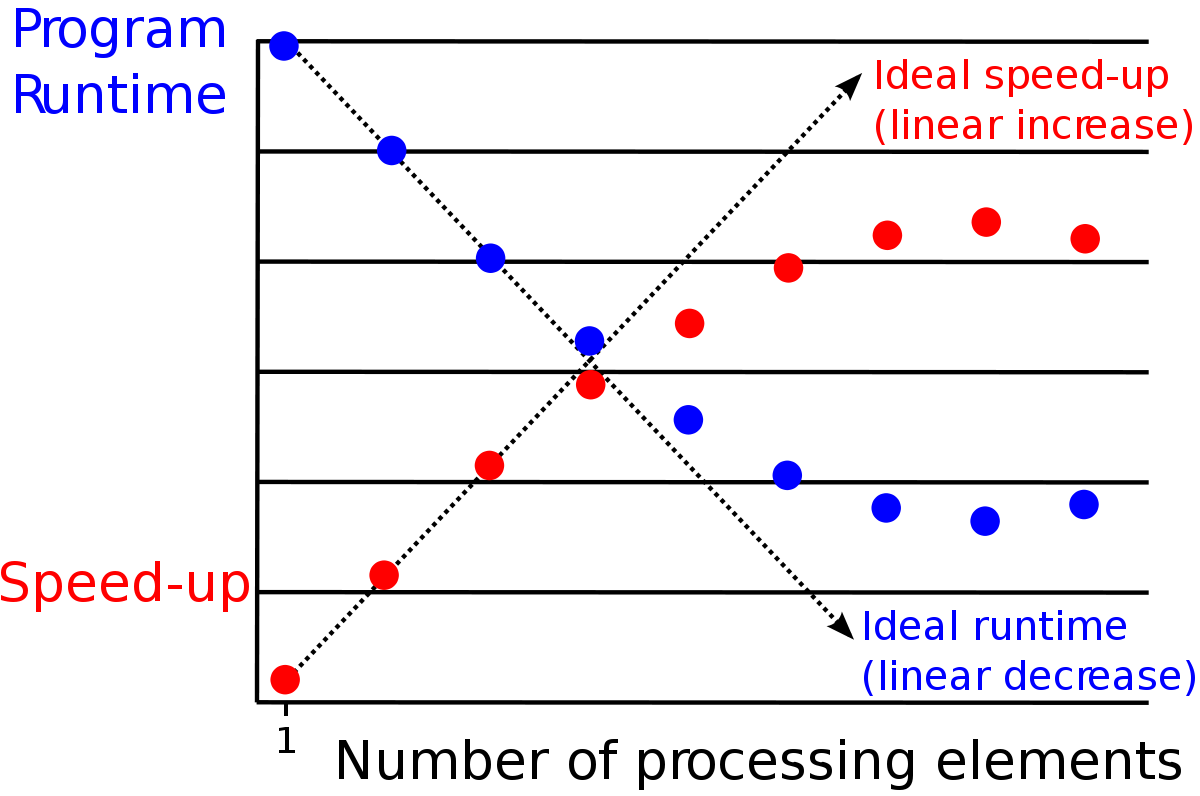
Parallel computing
INTRO1이랑 많이 겹치는듯..Idea:- split tasks with subtasks
- distribute subtasks
Benefits:- processing power
- memory benefits
Risks:- overhead due to communication
- task needs to be large
- need several processing units
- parallel slowdown
multiprocessing.pool
from multiprocessing import Pool
def take_mean_age(year_and_group):
year, group = year_and_group
return pd.DataFrame({"Age":groupg["Age"].mean()}, index=[year])
with Pool(4) as p:
results = p.map(take_mean_age, athlete_events.groupby("Year"))dask
SK플래닛 강의 들을 때 강사님께서 소개해주셨던..
몇십만줄짜리 데이터가 안들어와서 써본적이 있움
그냥 판다스처럼 쓰면 되는데 굉장히 빠르고 좋았다 import dask.dataframe as dd
dask_data = dd.from_pandas(data, npartitions=4)
result_df = dask_data.groupby('Year').Age.mean().compute()HDFS
Hadoop Map Reduce
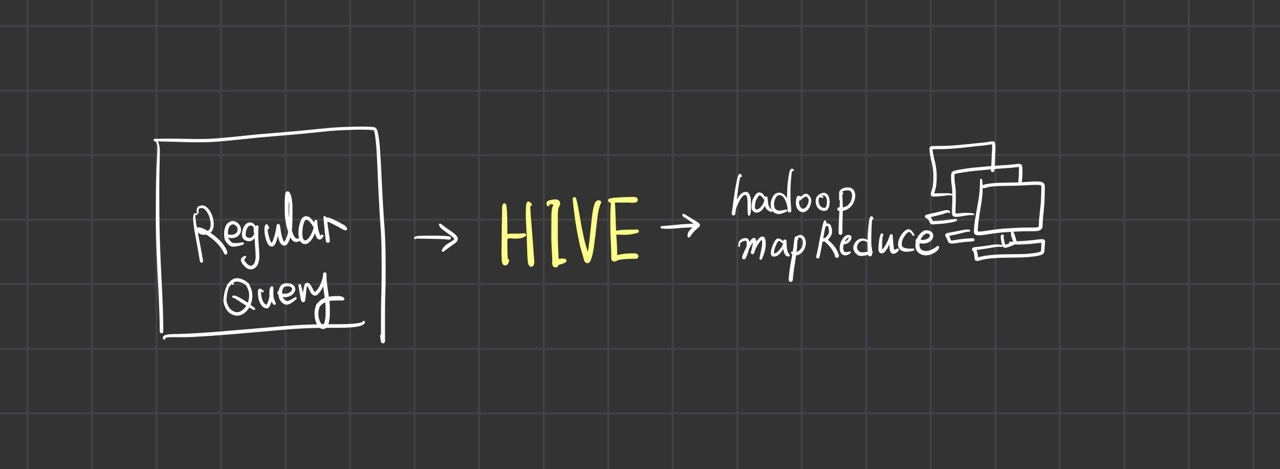
Hive
- top of the hadoop ecosystem
- runs on Hadoop
- Structured Query Language: Hive SQL
- initially MapReduce, now others
SELECT year, AVG(age)
FROM views.athlete_events
GROUP BY year- looks same with regular ones
- but, behind the curtains, it works on the clusters of computers, and HIVE makes it possible.
Spark
- map reduce
- avoid disk writes
Hadoop: get data from disks
- 데이터의 읽기, 쓰기 속도는 느리지만 디스크 용량 만큼의 데이터를 한번에 처리할 수 있음.
Spark: get data from memory
- 데이터의 읽기, 쓰기 속도는 빠르지만, 메모리 용량만큼의 데이터만 한번에 처리할 수 있음.
- 메모리 용량보다 큰 데이터를 처리할 때는 처리 이외의 메모리 내 데이터 교체나 작업 과정 저장, context switching 등과 같은 과부하 상황이 발생할 수 있다.
Resilient distributed datasets (RDD)
- Spark relies on them
- Similar to list of tuples
- Transformations:
.map()or.filter() - Actions:
.count()or.first()
PySpark
-
Python interface to Spark
-
Dataframe abstraction
-
Looks similar to Pandas
-
instead of SQL, can use dataframeworks
Workflow scheduling frameworks
- sth have to orchestrate all things
DAGs
Directed Acyclic Graph
- Set of nodes
- Directed edges
- No cycles
the tools for the job
- Linux's cron
- spotify's Luigi
- Apache Airflow <- 요즘 핫하다고 하던데..
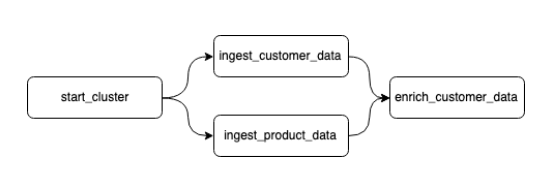
# Create the DAG Object
dag = DAG(dag_id="ex", ..., schedule_interval="8***")
# Define operations
start_cluster = StartClusterOperator(task_id="start_cluster", dag=dag)
ingest_customer_data = SparkJobOperator(task_id="ingest_customer_data", dag=dag)
ingest_product_data = SparkJobOperator(task_id="ingest_product_data", dag=dag)
enrich_customer_data = PythonOperator(task_id="enrich_customer_data", ..., dag=dag)
# Set up dependency flow
start_cluster.set_downstream(ingest_customer_data)
ingest_customer_data.set_downstream(enrich_customer_data)
ingest_product_data.set_downstream(enrich_customer_data)(+) Crontab Notation
| * | * | * | * | * |
|---|---|---|---|---|
| 분(0-59) | 시간(0-23) | 일(1-31) | 월(1-12) | 요일(0-7) |
참고로 요일은 0: 일, 1: 월 ~ 6: 토, 7: 일로 되어있음!
example
매분: * * * * * /home/script/test.sh매주 금요일 오전 5시 45분: 45 5 * * 5 [file_name]매일 매시간 0분, 20분, 40분: 0,20,40 * * * * [file name]
더 자세한 건 여기 refs: https://jdm.kr/blog/2
- example
# Create the DAG object
dag = DAG(dag_id="car_factory_simulation",
default_args={"owner": "airflow","start_date": airflow.utils.dates.days_ago(2)},
schedule_interval="0 * * * *")
# Task definitions
assemble_frame = BashOperator(task_id="assemble_frame", bash_command='echo ~', dag=dag)
place_tires = BashOperator(task_id="place_tires", bash_command='echo ~', dag=dag)
assemble_body = BashOperator(task_id="assemble_body", bash_command='echo "~', dag=dag)
# Complete the downstream flow
assemble_frame.set_downstream(place_tires)
assemble_frame.set_downstream(~)
assemble_frame.set_downstream(~)ETL
Extract
- three ways
- from text files, like
.txtor.csv - from APIs of web services, like the HackerNews API
- from a DB, like a SQL application DB
- from text files, like
Data on the Web through APIs
-
Data on the Web use requests
-
send data in JSON format
-
Twitter API :
{ "statuses: [{"created_at": "Mon May 06 20:01:29 +0000 2019", "text": "this is a tweet"}] } -
Hackernews API
import requests
response=requests.get("~")
print(response.json)Data in DB
-
Applications DB
- Transactions
- inserts or changes
- OLTP
- Row-oriented
-
Analytical DB
- OLAP
Extraction from DB
-
connection string/URI
- postgresql connection_uri :
"postgresql://[user[:password]@][host][:port][/database]"
- postgresql connection_uri :
import sqlalchemy
connection_uri = "~"
db_engine = sqlalchemy.create_engine(connection_uri)
import pandas as pd
pd.read_sql("SELECT * FROM customer", db_engine)Loading
Analytics or applications DB
| Analytics | Applications |
|---|---|
| Aggregate queries | Lots of transactions |
| Online analytical processing(OLAP) | Online transaction processing(OLTP) |
(+) 참고:
- OLAP: Online analytical processing
OLTP: Online transaction processing
Column- and row-oriented
| Analytics | Applications |
|---|---|
| column-oriented | Row-oriented |
| queries about subset of columns | stored per record |
| parallalization | added per transaction |
| - | e.g. adding customer is fast |
MPP Database
-
Massively Parallel Processing Databases
-
Ex) RedShift
df.to_parquet("./s3://path~.parquet")
df.write.parquet("./s3://path~.parquet")(+) What's Parquet?
- 데이터 저장 방식 중 하나로, 하둡에서 많이 쓰임
- 빅데이터처리는 빠르게 읽고, 압축률이 좋고, 특정언어에 종속되지 않아야 하므로 이러한 포맷인 Parquet, ORC, avro가 있게 됨.
- 목적은 필요한 데이터만 디스크로부터 읽어와서 I/O를 최소화하고, 데이터 크기를 줄이는 것
자세하게 잘 정리하신 곳 refs: https://pearlluck.tistory.com/561
