이번에는 InfluxDB 구조에 관한 이야기를 해보려고 한다.
주먹구구 식으로 공부했더니 정리가 안돼서 힘들었음ㅎ;
사실 아직도 다 모르겠음 ㅎ.. 스터디 과제 언제 하냐 ;ㅅ;
Overall Structure
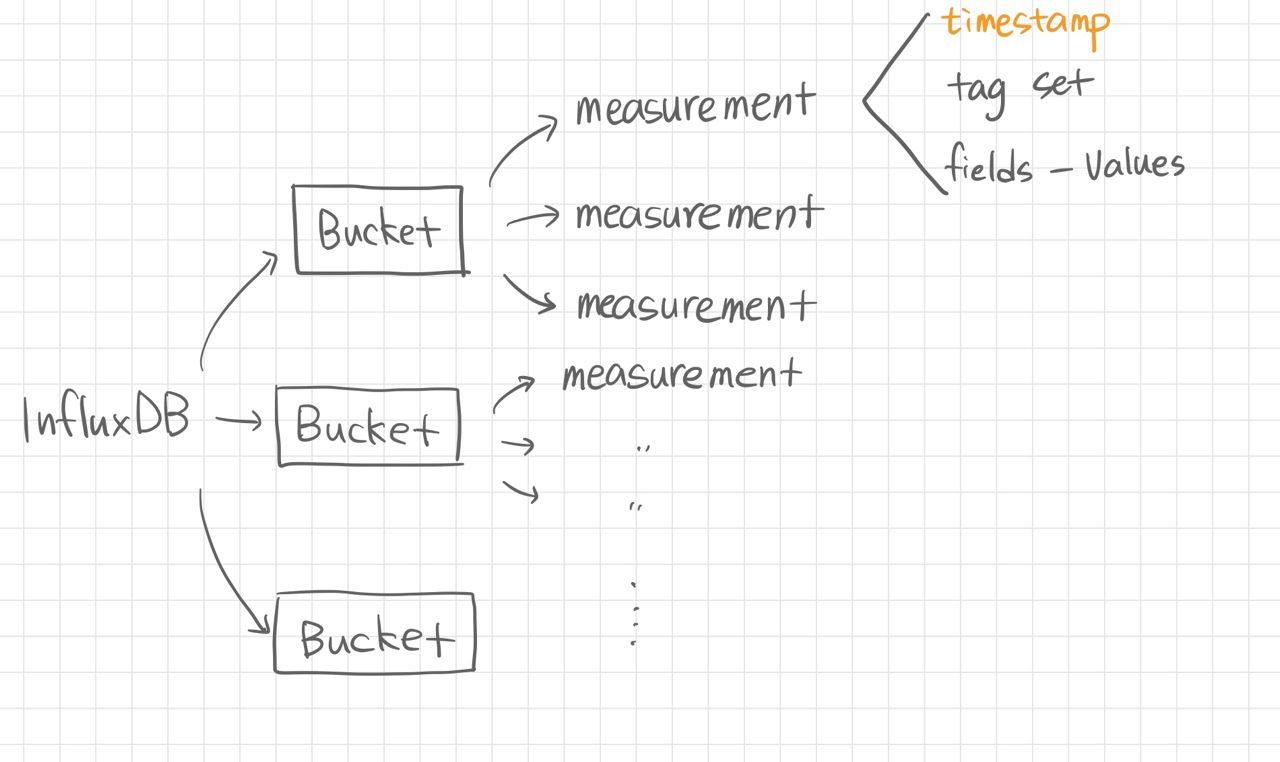
일단 v2.x 로 올라오면서 바뀐 큰 것중 하나가 이 Bucket이라고 한다
전에는 Database라는 이름으로 썼다고 하는데, 이제는 Bucket으로 대체되었다.
그리고 우리가 아는 table에 해당하는 개념이 measurement에 유사하고,
인덱스가 timestamp인 DB 정도로 이해하고 있는데 사실대로 말하면 아주 정확하다고는 할 수 없는 듯
Data Elements

field 에 대한 설명은 다음과 같음
bucket은 TS데이터가 위치해 있는 곳이고 retention-policy가 작동하는 것이기도 함
serie는 measurement, tag, field에 의해 나누었을 때 같은 테이블에 들어있는 것이라고 생각하는 게 빠르다고 생각함
measurement란 SQL database table과 유사한 것
tag는 인덱스 컬럼에 해당하는 것이고 field는 인덱싱되지 않는 컬럼에 해당하는 것이며
point는 하나의 행과 같다. (최근에 알았는데 ElasticSearch에서는 document라고 한다고 한다.)

개인적으로 이게 인상깊었는데, Tags는 인덱싱되어있고, 옵셔널하지만 field보다 속도가 빠르기 때문에 tags가 자주 쿼리되어지는 메타데이터에 대해서 더 이상적이게 만들어 준다고 한다.
사실 내가 field랑 tag랑 헷갈렸는데 이 글 보고 알아차려서 그럼
그리고 여기서 추가적으로 Series Cardinality에 대해 url이 연결되는데, 이 부분이 흥미로워서 가져와 봤다

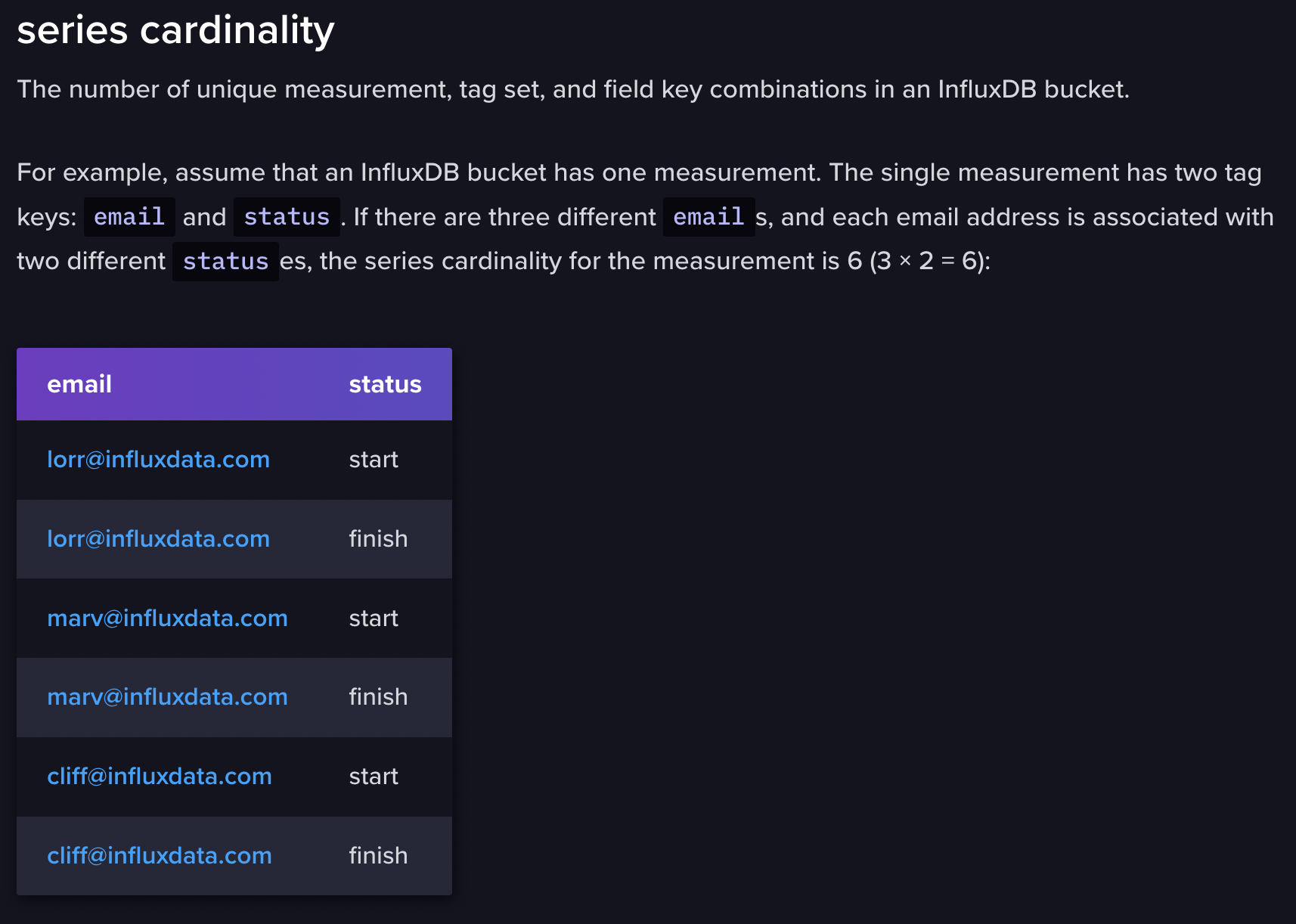

간단히 말하자면, 그냥 아래 그래프가 higher cardinality를 가질 것 같지만, first name이 하나 늘어난 것 뿐이지, first name은 결국 email에 종속성을 가지기 때문에, (email과 firstname이 짝을 이루고 있음) cardinality는 동일하다는 뜻이다.
그냥 넘어가면 충분히 간과할 만한 내용인데, 읽어보고 싶었음 ㅎ. 분명 어딘가에선 쓰이게 될 것 같음
line protocol, influxql vs. flux, writing 방법 등에 대해서는 내일 쓰겠음.. 졸려 죽겠음
+config 파일에 대해서도 써야 하는데..
